 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3SD: Multi-modal, Multi-scenario and Multi-language Speaker Diarization Dataset
Jun 17, 2025In the field of speaker diarization, the development of technology is constrained by two problems: insufficient data resources and poor generalization ability of deep learning models. To address these two problems, firstly, we propose an automated method for constructing speaker diarization datasets, which generates more accurate pseudo-labels for massive data through the combination of audio and video. Relying on this method, we have released Multi-modal, Multi-scenario and Multi-language Speaker Diarization (M3SD) datasets. This dataset is derived from real network videos and is highly diverse. In addition, we further propose a scenario-related model fine-tuning strategy. Based on the general model pre-trained using the above dataset, we combine the specific data of the target scenario (e.g., meetings) and achieve targeted optimization by using Adapter and LoRA joint fine-tuning, thus achieving the model's domain adaptation. Our dataset and code have been open-sourced at https://huggingface.co/spaces/OldDragon/m3sd.
Neural Speaker Diarization Using Memory-Aware Multi-Speaker Embedding with Sequence-to-Sequence Architecture
Sep 17, 2023



We propose a novel neural speaker diarization system using memory-aware multi-speaker embedding with sequence-to-sequence architecture (NSD-MS2S), which integrates the strengths of memory-aware multi-speaker embedding (MA-MSE) and sequence-to-sequence (Seq2Seq) architecture, leading to improvement in both efficiency and performance. Next, we further decrease the memory occupation of decoding by incorporating input features fusion and then employ a multi-head attention mechanism to capture features at different levels. NSD-MS2S achieved a macro diarization error rate (DER) of 15.9% on the CHiME-7 EVAL set, which signifies a relative improvement of 49% over the official baseline system, and is the key technique for us to achieve the best performance for the main track of CHiME-7 DASR Challenge. Additionally, we introduce a deep interactive module (DIM) in MA-MSE module to better retrieve a cleaner and more discriminative multi-speaker embedding, enabling the current model to outperform the system we used in the CHiME-7 DASR Challenge. Our code will be available at https://github.com/liyunlongaaa/NSD-MS2S.
The Multimodal Information Based Speech Processing (MISP) 2023 Challenge: Audio-Visual Target Speaker Extraction
Sep 15, 2023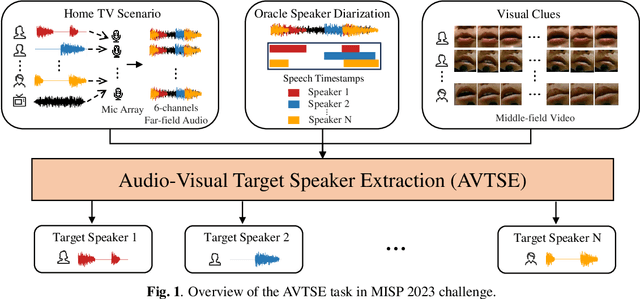
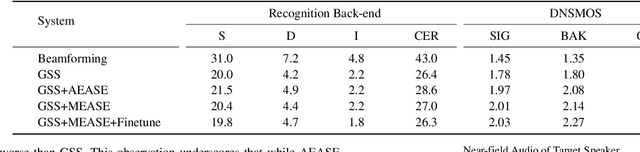
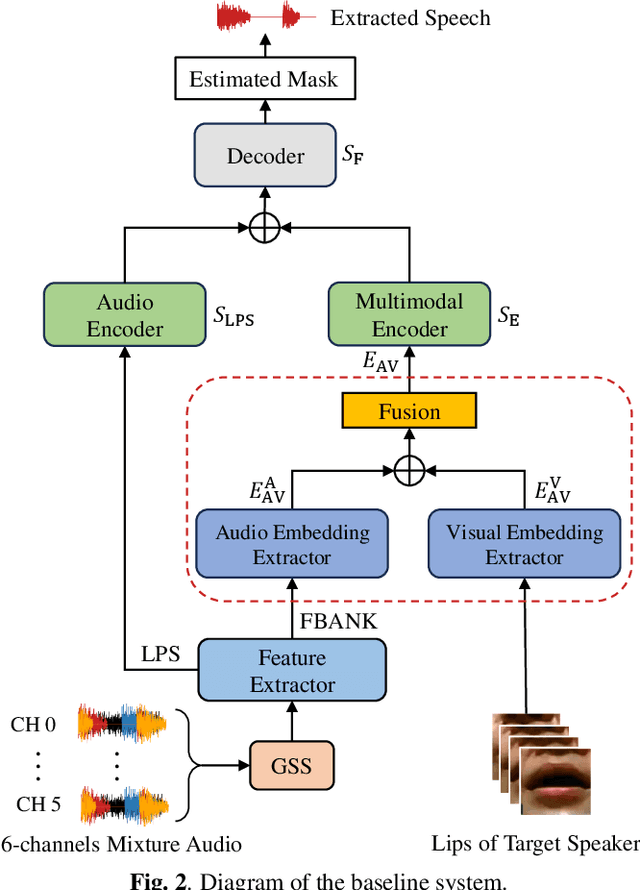

Previous Multimodal Information based Speech Processing (MISP) challenges mainly focused on audio-visual speech recognition (AVSR) with commendable success. However, the most advanced back-end recognition systems often hit performance limits due to the complex acoustic environments. This has prompted a shift in focus towards the Audio-Visual Target Speaker Extraction (AVTSE) task for the MISP 2023 challenge in ICASSP 2024 Signal Processing Grand Challenges. Unlike existing audio-visual speech enhance-ment challenges primarily focused on simulation data, the MISP 2023 challenge uniquely explores how front-end speech processing, combined with visual clues, impacts back-end tasks in real-world scenarios. This pioneering effort aims to set the first benchmark for the AVTSE task, offering fresh insights into enhancing the ac-curacy of back-end speech recognition systems through AVTSE in challenging and real acoustic environments. This paper delivers a thorough overview of the task setting, dataset, and baseline system of the MISP 2023 challenge. It also includes an in-depth analysis of the challenges participants may encounter. The experimental results highlight the demanding nature of this task, and we look forward to the innovative solutions participants will bring forward.
The USTC-NERCSLIP Systems for the CHiME-7 DASR Challenge
Aug 28, 2023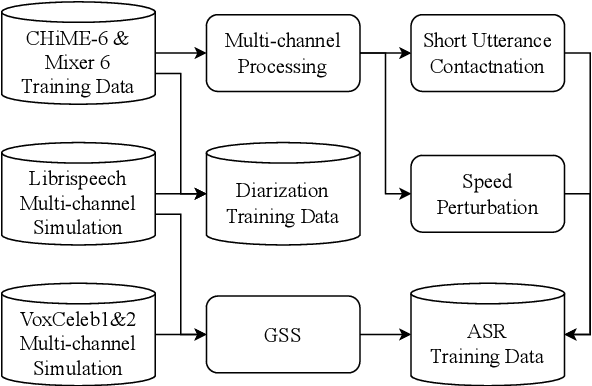
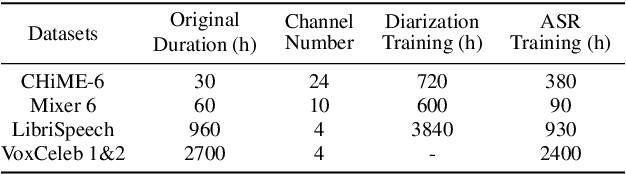
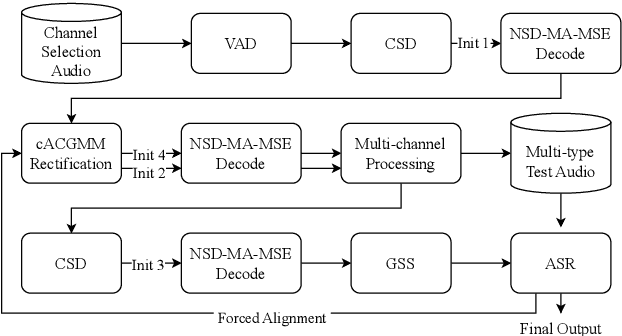
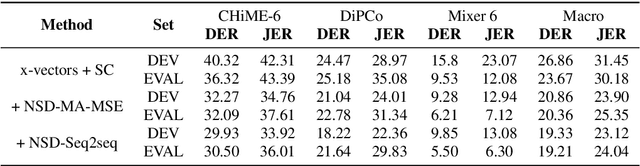
This technical report details our submission system to the CHiME-7 DASR Challenge, which focuses on speaker diarization and speech recognition under complex multi-speaker settings. Additionally, it also evaluates the efficiency of systems in handling diverse array devices. To address these issues, we implemented an end-to-end speaker diarization system and introduced a rectification strategy based on multi-channel spatial information. This approach significantly diminished the word error rates (WER). In terms of recognition, we utilized publicly available pre-trained models as the foundational models to train our end-to-end speech recognition models. Our system attained a macro-averaged diarization-attributed WER (DA-WER) of 22.4\% on the CHiME-7 development set, which signifies a relative improvement of 52.5\% over the official baseline system.
Semi-supervised multi-channel speaker diarization with cross-channel attention
Jul 17, 2023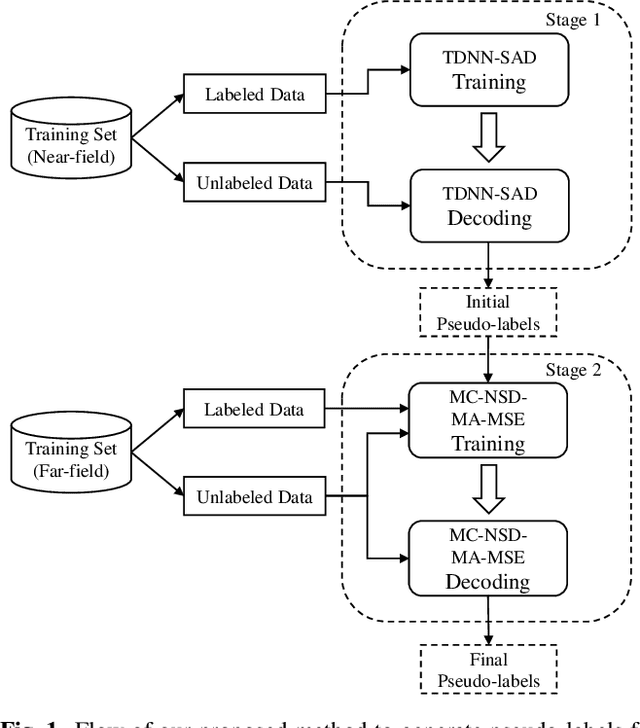
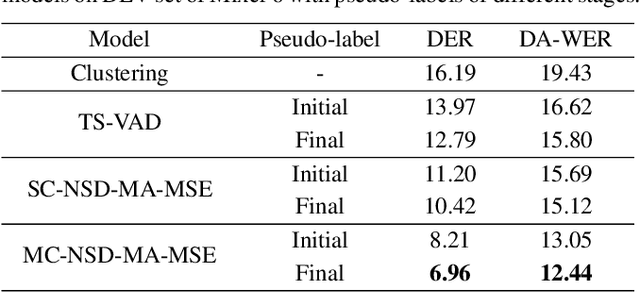

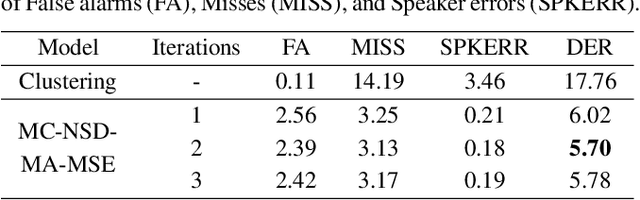
Most neural speaker diarization systems rely on sufficient manual training data labels, which are hard to collect under real-world scenarios. This paper proposes a semi-supervised speaker diarization system to utilize large-scale multi-channel training data by generating pseudo-labels for unlabeled data. Furthermore, we introduce cross-channel attention into the Neural Speaker Diarization Using Memory-Aware Multi-Speaker Embedding (NSD-MA-MSE) to learn channel contextual information of speaker embeddings better. Experimental results on the CHiME-7 Mixer6 dataset which only contains partial speakers' labels of the training set, show that our system achieved 57.01% relative DER reduction compared to the clustering-based model on the development set. We further conducted experiments on the CHiME-6 dataset to simulate the scenario of missing partial training set labels. When using 80% and 50% labeled training data, our system performs comparably to the results obtained using 100% labeled data for training.