 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-LLaMAv2 and MMEVerse: A New Framework and Benchmark for Multimodal Emotion Understanding
Jan 23, 2026Understanding human emotions from multimodal signals poses a significant challenge in affective computing and human-robot interaction. While multimodal large language models (MLLMs) have excelled in general vision-language tasks, their capabilities in emotional reasoning remain limited. The field currently suffers from a scarcity of large-scale datasets with high-quality, descriptive emotion annotations and lacks standardized benchmarks for evaluation. Our preliminary framework, Emotion-LLaMA, pioneered instruction-tuned multimodal learning for emotion reasoning but was restricted by explicit face detectors, implicit fusion strategies, and low-quality training data with limited scale. To address these limitations, we present Emotion-LLaMAv2 and the MMEVerse benchmark, establishing an end-to-end pipeline together with a standardized evaluation setting for emotion recognition and reasoning. Emotion-LLaMAv2 introduces three key advances. First, an end-to-end multiview encoder eliminates external face detection and captures nuanced emotional cues via richer spatial and temporal multiview tokens. Second, a Conv Attention pre-fusion module is designed to enable simultaneous local and global multimodal feature interactions external to the LLM backbone. Third, a perception-to-cognition curriculum instruction tuning scheme within the LLaMA2 backbone unifies emotion recognition and free-form emotion reasoning. To support large-scale training and reproducible evaluation, MMEVerse aggregates twelve publicly available emotion datasets, including IEMOCAP, MELD, DFEW, and MAFW, into a unified multimodal instruction format. The data are re-annotated via a multi-agent pipeline involving Qwen2 Audio, Qwen2.5 VL, and GPT 4o, producing 130k training clips and 36k testing clips across 18 evaluation benchmarks.
Emotion-Qwen: Training Hybrid Experts for Unified Emotion and General Vision-Language Understanding
May 10, 2025Emotion understanding in videos aims to accurately recognize and interpret individuals' emotional states by integrating contextual, visual, textual, and auditory cues. While Large Multimodal Models (LMMs) have demonstrated significant progress in general vision-language (VL) tasks, their performance in emotion-specific scenarios remains limited. Moreover, fine-tuning LMMs on emotion-related tasks often leads to catastrophic forgetting, hindering their ability to generalize across diverse tasks. To address these challenges, we present Emotion-Qwen, a tailored multimodal framework designed to enhance both emotion understanding and general VL reasoning. Emotion-Qwen incorporates a sophisticated Hybrid Compressor based on the Mixture of Experts (MoE) paradigm, which dynamically routes inputs to balance emotion-specific and general-purpose processing. The model is pre-trained in a three-stage pipeline on large-scale general and emotional image datasets to support robust multimodal representations. Furthermore, we construct the Video Emotion Reasoning (VER) dataset, comprising more than 40K bilingual video clips with fine-grained descriptive annotations, to further enrich Emotion-Qwen's emotional reasoning capability. Experimental results demonstrate that Emotion-Qwen achieves state-of-the-art performance on multiple emotion recognition benchmarks, while maintaining competitive results on general VL tasks. Code and models are available at https://anonymous.4open.science/r/Emotion-Qwen-Anonymous.
Why We Feel: Breaking Boundaries in Emotional Reasoning with Multimodal Large Language Models
Apr 10, 2025Most existing emotion analysis emphasizes which emotion arises (e.g., happy, sad, angry) but neglects the deeper why. We propose Emotion Interpretation (EI), focusing on causal factors-whether explicit (e.g., observable objects, interpersonal interactions) or implicit (e.g., cultural context, off-screen events)-that drive emotional responses. Unlike traditional emotion recognition, EI tasks require reasoning about triggers instead of mere labeling. To facilitate EI research, we present EIBench, a large-scale benchmark encompassing 1,615 basic EI samples and 50 complex EI samples featuring multifaceted emotions. Each instance demands rationale-based explanations rather than straightforward categorization. We further propose a Coarse-to-Fine Self-Ask (CFSA) annotation pipeline, which guides Vision-Language Models (VLLMs) through iterative question-answer rounds to yield high-quality labels at scale. Extensive evaluations on open-source and proprietary large language models under four experimental settings reveal consistent performance gaps-especially for more intricate scenarios-underscoring EI's potential to enrich empathetic, context-aware AI applications. Our benchmark and methods are publicly available at: https://github.com/Lum1104/EIBench, offering a foundation for advanced multimodal causal analysis and next-generation affective computing.
Dynamic Vision Mamba
Apr 07, 2025



Mamba-based vision models have gained extensive attention as a result of being computationally more efficient than attention-based models. However, spatial redundancy still exists in these models, represented by token and block redundancy. For token redundancy, we analytically find that early token pruning methods will result in inconsistency between training and inference or introduce extra computation for inference. Therefore, we customize token pruning to fit the Mamba structure by rearranging the pruned sequence before feeding it into the next Mamba block. For block redundancy, we allow each image to select SSM blocks dynamically based on an empirical observation that the inference speed of Mamba-based vision models is largely affected by the number of SSM blocks. Our proposed method, Dynamic Vision Mamba (DyVM), effectively reduces FLOPs with minor performance drops. We achieve a reduction of 35.2\% FLOPs with only a loss of accuracy of 1.7\% on Vim-S. It also generalizes well across different Mamba vision model architectures and different vision tasks. Our code will be made public.
PEBench: A Fictitious Dataset to Benchmark Machine Unlearning for Multimodal Large Language Models
Mar 16, 2025



In recent years, Multimodal Large Language Models (MLLMs) have demonstrated remarkable advancements in tasks such as visual question answering, visual understanding, and reasoning. However, this impressive progress relies on vast amounts of data collected from the internet, raising significant concerns about privacy and security. To address these issues, machine unlearning (MU) has emerged as a promising solution, enabling the removal of specific knowledge from an already trained model without requiring retraining from scratch. Although MU for MLLMs has gained attention, current evaluations of its efficacy remain incomplete, and the underlying problem is often poorly defined, which hinders the development of strategies for creating more secure and trustworthy systems. To bridge this gap, we introduce a benchmark, named PEBench, which includes a dataset of personal entities and corresponding general event scenes, designed to comprehensively assess the performance of MU for MLLMs. Through PEBench, we aim to provide a standardized and robust framework to advance research in secure and privacy-preserving multimodal models. We benchmarked 6 MU methods, revealing their strengths and limitations, and shedding light on key challenges and opportunities for MU in MLLMs.
MPBench: A Comprehensive Multimodal Reasoning Benchmark for Process Errors Identification
Mar 16, 2025



Reasoning is an essential capacity for large language models (LLMs) to address complex tasks, where the identification of process errors is vital for improving this ability. Recently, process-level reward models (PRMs) were proposed to provide step-wise rewards that facilitate reinforcement learning and data production during training and guide LLMs toward correct steps during inference, thereby improving reasoning accuracy. However, existing benchmarks of PRMs are text-based and focus on error detection, neglecting other scenarios like reasoning search. To address this gap, we introduce MPBench, a comprehensive, multi-task, multimodal benchmark designed to systematically assess the effectiveness of PRMs in diverse scenarios. MPBench employs three evaluation paradigms, each targeting a specific role of PRMs in the reasoning process: (1) Step Correctness, which assesses the correctness of each intermediate reasoning step; (2) Answer Aggregation, which aggregates multiple solutions and selects the best one; and (3) Reasoning Process Search, which guides the search for optimal reasoning steps during inference. Through these paradigms, MPBench makes comprehensive evaluations and provides insights into the development of multimodal PRMs.
Faster Vision Mamba is Rebuilt in Minutes via Merged Token Re-training
Dec 17, 2024



Vision Mamba (e.g., Vim) has successfully been integrated into computer vision, and token reduction has yielded promising outcomes in Vision Transformers (ViTs). However, token reduction performs less effectively on Vision Mamba compared to ViTs. Pruning informative tokens in Mamba leads to a high loss of key knowledge and bad performance. This makes it not a good solution for enhancing efficiency in Mamba. Token merging, which preserves more token information than pruning, has demonstrated commendable performance in ViTs. Nevertheless, vanilla merging performance decreases as the reduction ratio increases either, failing to maintain the key knowledge in Mamba. Re-training the token-reduced model enhances the performance of Mamba, by effectively rebuilding the key knowledge. Empirically, pruned Vims only drop up to 0.9% accuracy on ImageNet-1K, recovered by our proposed framework R-MeeTo in our main evaluation. We show how simple and effective the fast recovery can be achieved at minute-level, in particular, a 35.9% accuracy spike over 3 epochs of training on Vim-Ti. Moreover, Vim-Ti/S/B are re-trained within 5/7/17 minutes, and Vim-S only drop 1.3% with 1.2x (up to 1.5x) speed up in inference.
Is Graph Convolution Always Beneficial For Every Feature?
Nov 12, 2024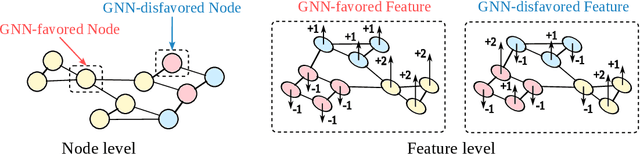

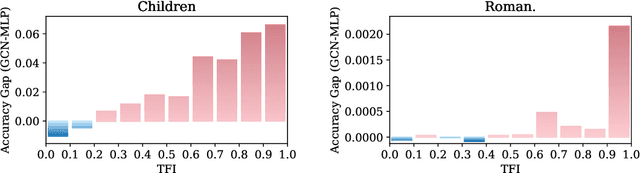

Graph Neural Networks (GNNs) have demonstrated strong capabilities in processing structured data. While traditional GNNs typically treat each feature dimension equally during graph convolution, we raise an important question: Is the graph convolution operation equally beneficial for each feature? If not, the convolution operation on certain feature dimensions can possibly lead to harmful effects, even worse than the convolution-free models. In prior studies, to assess the impacts of graph convolution on features, people proposed metrics based on feature homophily to measure feature consistency with the graph topology. However, these metrics have shown unsatisfactory alignment with GNN performance and have not been effectively employed to guide feature selection in GNNs. To address these limitations, we introduce a novel metric, Topological Feature Informativeness (TFI), to distinguish between GNN-favored and GNN-disfavored features, where its effectiveness is validated through both theoretical analysis and empirical observations. Based on TFI, we propose a simple yet effective Graph Feature Selection (GFS) method, which processes GNN-favored and GNN-disfavored features separately, using GNNs and non-GNN models. Compared to original GNNs, GFS significantly improves the extraction of useful topological information from each feature with comparable computational costs. Extensive experiments show that after applying GFS to 8 baseline and state-of-the-art (SOTA) GNN architectures across 10 datasets, 83.75% of the GFS-augmented cases show significant performance boosts. Furthermore, our proposed TFI metric outperforms other feature selection methods. These results validate the effectiveness of both GFS and TFI. Additionally, we demonstrate that GFS's improvements are robust to hyperparameter tuning, highlighting its potential as a universal method for enhancing various GNN architectures.
Rethinking Structure Learning For Graph Neural Networks
Nov 12, 2024
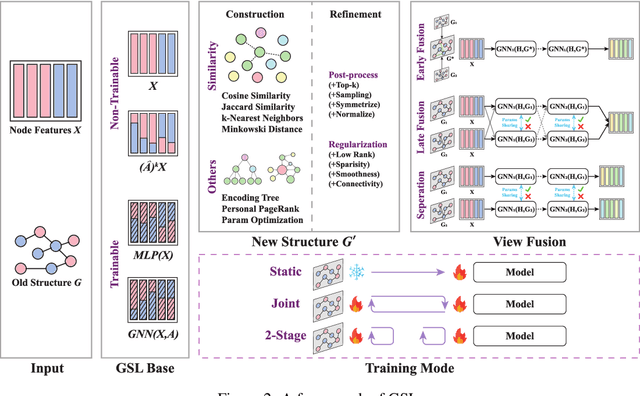

To improve the performance of Graph Neural Networks (GNNs), Graph Structure Learning (GSL) has been extensively applied to reconstruct or refine original graph structures, effectively addressing issues like heterophily, over-squashing, and noisy structures. While GSL is generally thought to improve GNN performance, it often leads to longer training times and more hyperparameter tuning. Besides, the distinctions among current GSL methods remain ambiguous from the perspective of GNN training, and there is a lack of theoretical analysis to quantify their effectiveness. Recent studies further suggest that, under fair comparisons with the same hyperparameter tuning, GSL does not consistently outperform baseline GNNs. This motivates us to ask a critical question: is GSL really useful for GNNs? To address this question, this paper makes two key contributions. First, we propose a new GSL framework, which includes three steps: GSL base (the representation used for GSL) construction, new structure construction, and view fusion, to better understand the effectiveness of GSL in GNNs. Second, after graph convolution, we analyze the differences in mutual information (MI) between node representations derived from the original topology and those from the newly constructed topology. Surprisingly, our empirical observations and theoretical analysis show that no matter which type of graph structure construction methods are used, after feeding the same GSL bases to the newly constructed graph, there is no MI gain compared to the original GSL bases. To fairly reassess the effectiveness of GSL, we conduct ablation experiments and find that it is the pretrained GSL bases that enhance GNN performance, and in most cases, GSL cannot improve GNN performance. This finding encourages us to rethink the essential components in GNNs, such as self-training and structural encoding, in GNN design rather than GSL.
Mamba-Enhanced Text-Audio-Video Alignment Network for Emotion Recognition in Conversations
Sep 08, 2024



Emotion Recognition in Conversations (ERCs) is a vital area within multimodal interaction research, dedicated to accurately identifying and classifying the emotions expressed by speakers throughout a conversation. Traditional ERC approaches predominantly rely on unimodal cues\-such as text, audio, or visual data\-leading to limitations in their effectiveness. These methods encounter two significant challenges: 1) Consistency in multimodal information. Before integrating various modalities, it is crucial to ensure that the data from different sources is aligned and coherent. 2) Contextual information capture. Successfully fusing multimodal features requires a keen understanding of the evolving emotional tone, especially in lengthy dialogues where emotions may shift and develop over time. To address these limitations, we propose a novel Mamba-enhanced Text-Audio-Video alignment network (MaTAV) for the ERC task. MaTAV is with the advantages of aligning unimodal features to ensure consistency across different modalities and handling long input sequences to better capture contextual multimodal information. The extensive experiments on the MELD and IEMOCAP datasets demonstrate that MaTAV significantly outperforms existing state-of-the-art methods on the ERC task with a big margin.