 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuned LLMs Know They Don't Know: A Parameter-Efficient Approach to Recovering Honesty
Nov 17, 2025The honesty of Large Language Models (LLMs) is increasingly important for safe deployment in high-stakes domains. However, this crucial trait is severely undermined by supervised fine-tuning (SFT), a common technique for model specialization. Existing recovery methods rely on data-intensive global parameter adjustments, implicitly assuming that SFT deeply corrupts the models' ability to recognize their knowledge boundaries. However, we observe that fine-tuned LLMs still preserve this ability; what is damaged is their capacity to faithfully express that awareness. Building on this, we propose Honesty-Critical Neurons Restoration (HCNR) to surgically repair this suppressed capacity. HCNR identifies and restores key expression-governing neurons to their pre-trained state while harmonizing them with task-oriented neurons via Hessian-guided compensation. Experiments on four QA tasks and five LLM families demonstrate that HCNR effectively recovers 33.25% of the compromised honesty while achieving at least 2.23x speedup with over 10x less data compared to baseline methods, offering a practical solution for trustworthy LLM deployment.
Lightweight posterior construction for gravitational-wave catalogs with the Kolmogorov-Arnold network
Aug 26, 2025Neural density estimation has seen widespread applications in the gravitational-wave (GW) data analysis, which enables real-time parameter estimation for compact binary coalescences and enhances rapid inference for subsequent analysis such as population inference. In this work, we explore the application of using the Kolmogorov-Arnold network (KAN) to construct efficient and interpretable neural density estimators for lightweight posterior construction of GW catalogs. By replacing conventional activation functions with learnable splines, KAN achieves superior interpretability, higher accuracy, and greater parameter efficiency on related scientific tasks. Leveraging this feature, we propose a KAN-based neural density estimator, which ingests megabyte-scale GW posterior samples and compresses them into model weights of tens of kilobytes. Subsequently, analytic expressions requiring only several kilobytes can be further distilled from these neural network weights with minimal accuracy trade-off. In practice, GW posterior samples with fidelity can be regenerated rapidly using the model weights or analytic expressions for subsequent analysis. Our lightweight posterior construction strategy is expected to facilitate user-level data storage and transmission, paving a path for efficient analysis of numerous GW events in the next-generation GW detectors.
DeepPHY: Benchmarking Agentic VLMs on Physical Reasoning
Aug 07, 2025Although Vision Language Models (VLMs) exhibit strong perceptual abilities and impressive visual reasoning, they struggle with attention to detail and precise action planning in complex, dynamic environments, leading to subpar performance. Real-world tasks typically require complex interactions, advanced spatial reasoning, long-term planning, and continuous strategy refinement, usually necessitating understanding the physics rules of the target scenario. However, evaluating these capabilities in real-world scenarios is often prohibitively expensive. To bridge this gap, we introduce DeepPHY, a novel benchmark framework designed to systematically evaluate VLMs' understanding and reasoning about fundamental physical principles through a series of challenging simulated environments. DeepPHY integrates multiple physical reasoning environments of varying difficulty levels and incorporates fine-grained evaluation metrics. Our evaluation finds that even state-of-the-art VLMs struggle to translate descriptive physical knowledge into precise, predictive control.
DISCOVERSE: Efficient Robot Simulation in Complex High-Fidelity Environments
Jul 29, 2025We present the first unified, modular, open-source 3DGS-based simulation framework for Real2Sim2Real robot learning. It features a holistic Real2Sim pipeline that synthesizes hyper-realistic geometry and appearance of complex real-world scenarios, paving the way for analyzing and bridging the Sim2Real gap. Powered by Gaussian Splatting and MuJoCo, Discoverse enables massively parallel simulation of multiple sensor modalities and accurate physics, with inclusive supports for existing 3D assets, robot models, and ROS plugins, empowering large-scale robot learning and complex robotic benchmarks. Through extensive experiments on imitation learning, Discoverse demonstrates state-of-the-art zero-shot Sim2Real transfer performance compared to existing simulators. For code and demos: https://air-discoverse.github.io/.
Towards Objective Fine-tuning: How LLMs' Prior Knowledge Causes Potential Poor Calibration?
May 27, 2025Fine-tuned Large Language Models (LLMs) often demonstrate poor calibration, with their confidence scores misaligned with actual performance. While calibration has been extensively studied in models trained from scratch, the impact of LLMs' prior knowledge on calibration during fine-tuning remains understudied. Our research reveals that LLMs' prior knowledge causes potential poor calibration due to the ubiquitous presence of known data in real-world fine-tuning, which appears harmful for calibration. Specifically, data aligned with LLMs' prior knowledge would induce overconfidence, while new knowledge improves calibration. Our findings expose a tension: LLMs' encyclopedic knowledge, while enabling task versatility, undermines calibration through unavoidable knowledge overlaps. To address this, we propose CogCalib, a cognition-aware framework that applies targeted learning strategies according to the model's prior knowledge. Experiments across 7 tasks using 3 LLM families prove that CogCalib significantly improves calibration while maintaining performance, achieving an average 57\% reduction in ECE compared to standard fine-tuning in Llama3-8B. These improvements generalize well to out-of-domain tasks, enhancing the objectivity and reliability of domain-specific LLMs, and making them more trustworthy for critical human-AI interaction applications.
Equivariant Flow Matching for Point Cloud Assembly
May 24, 2025The goal of point cloud assembly is to reconstruct a complete 3D shape by aligning multiple point cloud pieces. This work presents a novel equivariant solver for assembly tasks based on flow matching models. We first theoretically show that the key to learning equivariant distributions via flow matching is to learn related vector fields. Based on this result, we propose an assembly model, called equivariant diffusion assembly (Eda), which learns related vector fields conditioned on the input pieces. We further construct an equivariant path for Eda, which guarantees high data efficiency of the training process. Our numerical results show that Eda is highly competitive on practical datasets, and it can even handle the challenging situation where the input pieces are non-overlapped.
Data Whisperer: Efficient Data Selection for Task-Specific LLM Fine-Tuning via Few-Shot In-Context Learning
May 18, 2025Fine-tuning large language models (LLMs) on task-specific data is essential for their effective deployment. As dataset sizes grow, efficiently selecting optimal subsets for training becomes crucial to balancing performance and computational costs. Traditional data selection methods often require fine-tuning a scoring model on the target dataset, which is time-consuming and resource-intensive, or rely on heuristics that fail to fully leverage the model's predictive capabilities. To address these challenges, we propose Data Whisperer, an efficient, training-free, attention-based method that leverages few-shot in-context learning with the model to be fine-tuned. Comprehensive evaluations were conducted on both raw and synthetic datasets across diverse tasks and models. Notably, Data Whisperer achieves superior performance compared to the full GSM8K dataset on the Llama-3-8B-Instruct model, using just 10% of the data, and outperforms existing methods with a 3.1-point improvement and a 7.4$\times$ speedup.
ASRC-SNN: Adaptive Skip Recurrent Connection Spiking Neural Network
May 16, 2025In recent years, Recurrent Spiking Neural Networks (RSNNs) have shown promising potential in long-term temporal modeling. Many studies focus on improving neuron models and also integrate recurrent structures, leveraging their synergistic effects to improve the long-term temporal modeling capabilities of Spiking Neural Networks (SNNs). However, these studies often place an excessive emphasis on the role of neurons, overlooking the importance of analyzing neurons and recurrent structures as an integrated framework. In this work, we consider neurons and recurrent structures as an integrated system and conduct a systematic analysis of gradient propagation along the temporal dimension, revealing a challenging gradient vanishing problem. To address this issue, we propose the Skip Recurrent Connection (SRC) as a replacement for the vanilla recurrent structure, effectively mitigating the gradient vanishing problem and enhancing long-term temporal modeling performance. Additionally, we propose the Adaptive Skip Recurrent Connection (ASRC), a method that can learn the skip span of skip recurrent connection in each layer of the network. Experiments show that replacing the vanilla recurrent structure in RSNN with SRC significantly improves the model's performance on temporal benchmark datasets. Moreover, ASRC-SNN outperforms SRC-SNN in terms of temporal modeling capabilities and robustness.
CombatVLA: An Efficient Vision-Language-Action Model for Combat Tasks in 3D Action Role-Playing Games
Mar 12, 2025
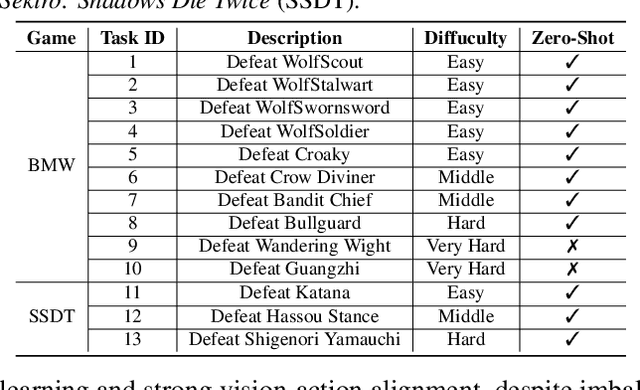

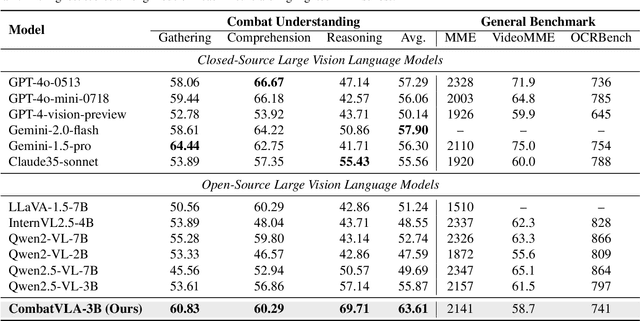
Recent advances in Vision-Language-Action models (VLAs) have expanded the capabilities of embodied intelligence. However, significant challenges remain in real-time decision-making in complex 3D environments, which demand second-level responses, high-resolution perception, and tactical reasoning under dynamic conditions. To advance the field, we introduce CombatVLA, an efficient VLA model optimized for combat tasks in 3D action role-playing games(ARPGs). Specifically, our CombatVLA is a 3B model trained on video-action pairs collected by an action tracker, where the data is formatted as action-of-thought (AoT) sequences. Thereafter, CombatVLA seamlessly integrates into an action execution framework, allowing efficient inference through our truncated AoT strategy. Experimental results demonstrate that CombatVLA not only outperforms all existing models on the combat understanding benchmark but also achieves a 50-fold acceleration in game combat. Moreover, it has a higher task success rate than human players. We will open-source all resources, including the action tracker, dataset, benchmark, model weights, training code, and the implementation of the framework at https://combatvla.github.io/.
FanChuan: A Multilingual and Graph-Structured Benchmark For Parody Detection and Analysis
Feb 23, 2025



Parody is an emerging phenomenon on social media, where individuals imitate a role or position opposite to their own, often for humor, provocation, or controversy. Detecting and analyzing parody can be challenging and is often reliant on context, yet it plays a crucial role in understanding cultural values, promoting subcultures, and enhancing self-expression. However, the study of parody is hindered by limited available data and deficient diversity in current datasets. To bridge this gap, we built seven parody datasets from both English and Chinese corpora, with 14,755 annotated users and 21,210 annotated comments in total. To provide sufficient context information, we also collect replies and construct user-interaction graphs to provide richer contextual information, which is lacking in existing datasets. With these datasets, we test traditional methods and Large Language Models (LLMs) on three key tasks: (1) parody detection, (2) comment sentiment analysis with parody, and (3) user sentiment analysis with parody. Our extensive experiments reveal that parody-related tasks still remain challenging for all models, and contextual information plays a critical role. Interestingly, we find that, in certain scenarios, traditional sentence embedding methods combined with simple classifiers can outperform advanced LLMs, i.e. DeepSeek-R1 and GPT-o3, highlighting parody as a significant challenge for LLMs.