 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndroidLens: Long-latency Evaluation with Nested Sub-targets for Android GUI Agents
Dec 24, 2025Graphical user interface (GUI) agents can substantially improve productivity by automating frequently executed long-latency tasks on mobile devices. However, existing evaluation benchmarks are still constrained to limited applications, simple tasks, and coarse-grained metrics. To address this, we introduce AndroidLens, a challenging evaluation framework for mobile GUI agents, comprising 571 long-latency tasks in both Chinese and English environments, each requiring an average of more than 26 steps to complete. The framework features: (1) tasks derived from real-world user scenarios across 38 domains, covering complex types such as multi-constraint, multi-goal, and domain-specific tasks; (2) static evaluation that preserves real-world anomalies and allows multiple valid paths to reduce bias; and (3) dynamic evaluation that employs a milestone-based scheme for fine-grained progress measurement via Average Task Progress (ATP). Our evaluation indicates that even the best models reach only a 12.7% task success rate and 50.47% ATP. We also underscore key challenges in real-world environments, including environmental anomalies, adaptive exploration, and long-term memory retention.
InquireMobile: Teaching VLM-based Mobile Agent to Request Human Assistance via Reinforcement Fine-Tuning
Aug 27, 2025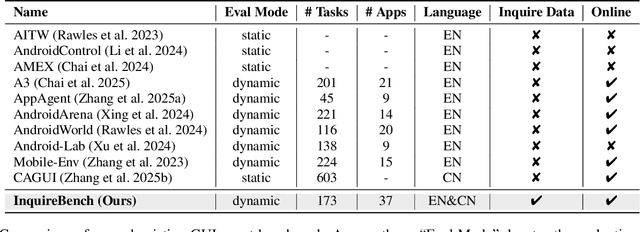
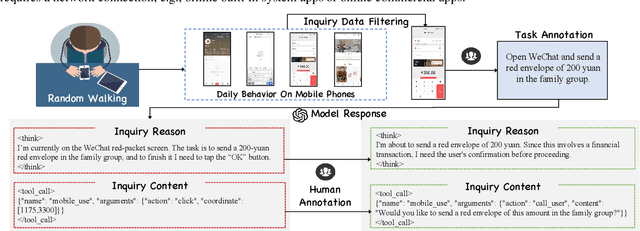
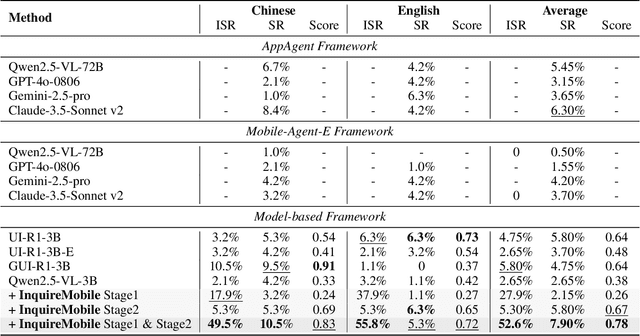
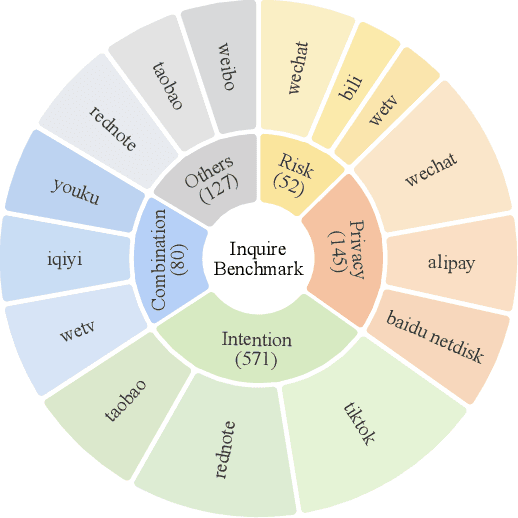
Recent advances in Vision-Language Models (VLMs) have enabled mobile agents to perceive and interact with real-world mobile environments based on human instructions. However, the current fully autonomous paradigm poses potential safety risks when model understanding or reasoning capabilities are insufficient. To address this challenge, we first introduce \textbf{InquireBench}, a comprehensive benchmark specifically designed to evaluate mobile agents' capabilities in safe interaction and proactive inquiry with users, encompassing 5 categories and 22 sub-categories, where most existing VLM-based agents demonstrate near-zero performance. In this paper, we aim to develop an interactive system that actively seeks human confirmation at critical decision points. To achieve this, we propose \textbf{InquireMobile}, a novel model inspired by reinforcement learning, featuring a two-stage training strategy and an interactive pre-action reasoning mechanism. Finally, our model achieves an 46.8% improvement in inquiry success rate and the best overall success rate among existing baselines on InquireBench. We will open-source all datasets, models, and evaluation codes to facilitate development in both academia and industry.
GeoSense: Evaluating Identification and Application of Geometric Principles in Multimodal Reasoning
Apr 17, 2025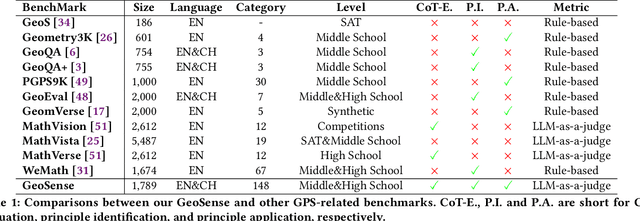
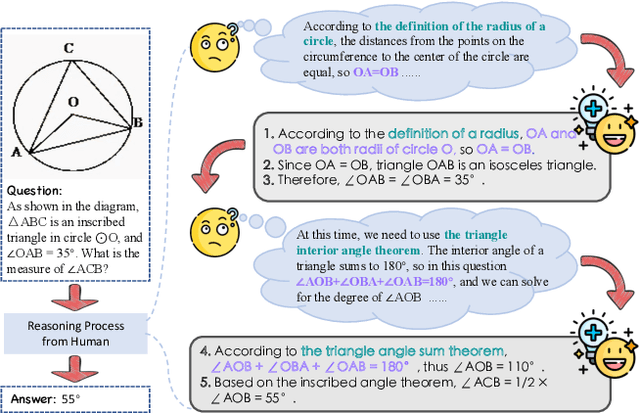
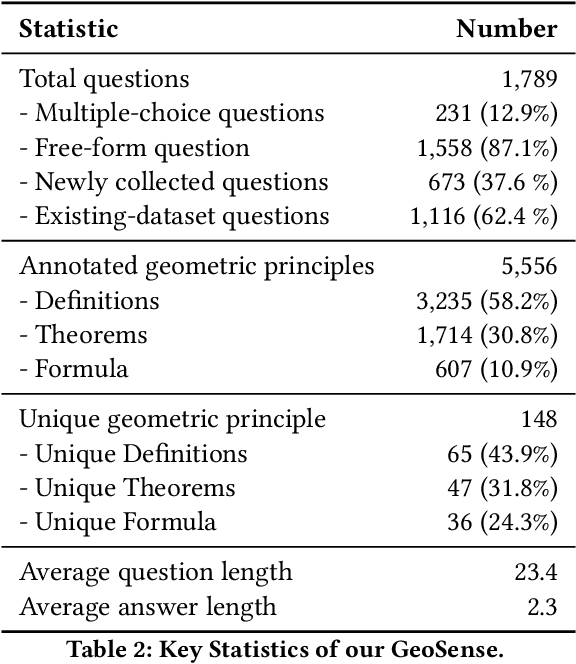
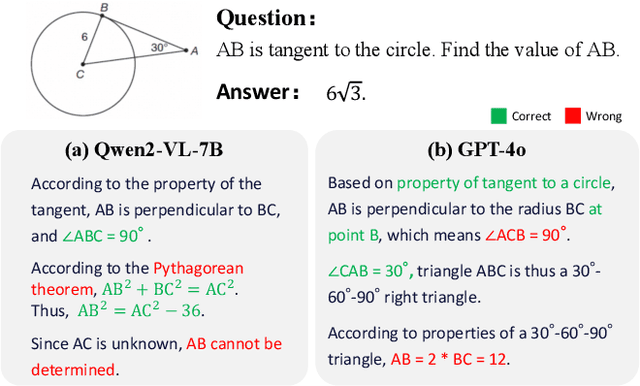
Geometry problem-solving (GPS), a challenging task requiring both visual comprehension and symbolic reasoning, effectively measures the reasoning capabilities of multimodal large language models (MLLMs). Humans exhibit strong reasoning ability in this task through accurate identification and adaptive application of geometric principles within visual contexts. However, existing benchmarks fail to jointly assess both dimensions of the human-like geometric reasoning mechanism in MLLMs, remaining a critical gap in assessing their ability to tackle GPS. To this end, we introduce GeoSense, the first comprehensive bilingual benchmark designed to systematically evaluate the geometric reasoning abilities of MLLMs through the lens of geometric principles. GeoSense features a five-level hierarchical framework of geometric principles spanning plane and solid geometry, an intricately annotated dataset of 1,789 problems, and an innovative evaluation strategy. Through extensive experiments on GeoSense with various open-source and closed-source MLLMs, we observe that Gemini-2.0-pro-flash performs best, achieving an overall score of $65.3$. Our in-depth analysis reveals that the identification and application of geometric principles remain a bottleneck for leading MLLMs, jointly hindering their reasoning abilities. These findings underscore GeoSense's potential to guide future advancements in MLLMs' geometric reasoning capabilities, paving the way for more robust and human-like reasoning in artificial intelligence.
Video SimpleQA: Towards Factuality Evaluation in Large Video Language Models
Mar 24, 2025



Recent advancements in Large Video Language Models (LVLMs) have highlighted their potential for multi-modal understanding, yet evaluating their factual grounding in video contexts remains a critical unsolved challenge. To address this gap, we introduce Video SimpleQA, the first comprehensive benchmark tailored for factuality evaluation of LVLMs. Our work distinguishes from existing video benchmarks through the following key features: 1) Knowledge required: demanding integration of external knowledge beyond the explicit narrative; 2) Fact-seeking question: targeting objective, undisputed events or relationships, avoiding subjective interpretation; 3) Definitive & short-form answer: Answers are crafted as unambiguous and definitively correct in a short format, enabling automated evaluation through LLM-as-a-judge frameworks with minimal scoring variance; 4) External-source verified: All annotations undergo rigorous validation against authoritative external references to ensure the reliability; 5) Temporal reasoning required: The annotated question types encompass both static single-frame understanding and dynamic temporal reasoning, explicitly evaluating LVLMs factuality under the long-context dependencies. We extensively evaluate 41 state-of-the-art LVLMs and summarize key findings as follows: 1) Current LVLMs exhibit notable deficiencies in factual adherence, particularly for open-source models. The best-performing model Gemini-1.5-Pro achieves merely an F-score of 54.4%; 2) Test-time compute paradigms show insignificant performance gains, revealing fundamental constraints for enhancing factuality through post-hoc computation; 3) Retrieval-Augmented Generation demonstrates consistent improvements at the cost of additional inference time overhead, presenting a critical efficiency-performance trade-off.
CombatVLA: An Efficient Vision-Language-Action Model for Combat Tasks in 3D Action Role-Playing Games
Mar 12, 2025
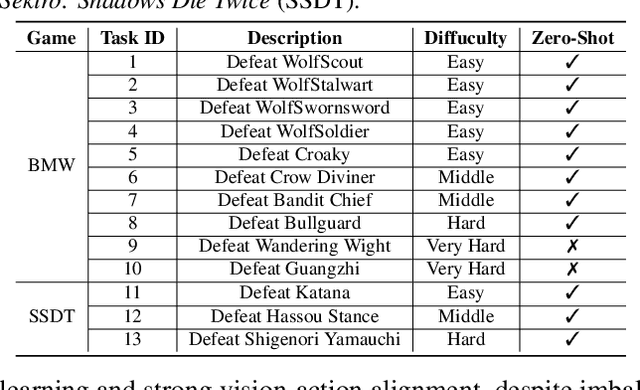

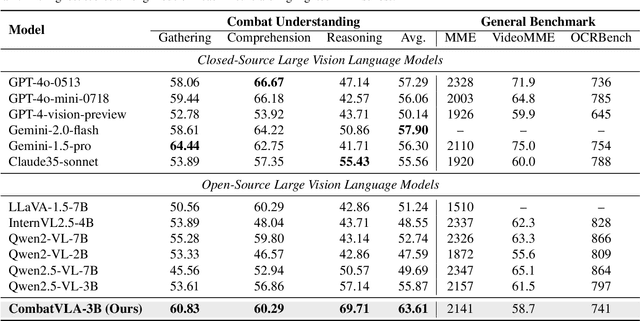
Recent advances in Vision-Language-Action models (VLAs) have expanded the capabilities of embodied intelligence. However, significant challenges remain in real-time decision-making in complex 3D environments, which demand second-level responses, high-resolution perception, and tactical reasoning under dynamic conditions. To advance the field, we introduce CombatVLA, an efficient VLA model optimized for combat tasks in 3D action role-playing games(ARPGs). Specifically, our CombatVLA is a 3B model trained on video-action pairs collected by an action tracker, where the data is formatted as action-of-thought (AoT) sequences. Thereafter, CombatVLA seamlessly integrates into an action execution framework, allowing efficient inference through our truncated AoT strategy. Experimental results demonstrate that CombatVLA not only outperforms all existing models on the combat understanding benchmark but also achieves a 50-fold acceleration in game combat. Moreover, it has a higher task success rate than human players. We will open-source all resources, including the action tracker, dataset, benchmark, model weights, training code, and the implementation of the framework at https://combatvla.github.io/.
ChineseSimpleVQA -- "See the World, Discover Knowledge": A Chinese Factuality Evaluation for Large Vision Language Models
Feb 19, 2025The evaluation of factual accuracy in large vision language models (LVLMs) has lagged behind their rapid development, making it challenging to fully reflect these models' knowledge capacity and reliability. In this paper, we introduce the first factuality-based visual question-answering benchmark in Chinese, named ChineseSimpleVQA, aimed at assessing the visual factuality of LVLMs across 8 major topics and 56 subtopics. The key features of this benchmark include a focus on the Chinese language, diverse knowledge types, a multi-hop question construction, high-quality data, static consistency, and easy-to-evaluate through short answers. Moreover, we contribute a rigorous data construction pipeline and decouple the visual factuality into two parts: seeing the world (i.e., object recognition) and discovering knowledge. This decoupling allows us to analyze the capability boundaries and execution mechanisms of LVLMs. Subsequently, we evaluate 34 advanced open-source and closed-source models, revealing critical performance gaps within this field.
Compression with Global Guidance: Towards Training-free High-Resolution MLLMs Acceleration
Jan 09, 2025



Multimodal large language models (MLLMs) have attracted considerable attention due to their exceptional performance in visual content understanding and reasoning. However, their inference efficiency has been a notable concern, as the increasing length of multimodal contexts leads to quadratic complexity. Token compression techniques, which reduce the number of visual tokens, have demonstrated their effectiveness in reducing computational costs. Yet, these approaches have struggled to keep pace with the rapid advancements in MLLMs, especially the AnyRes strategy in the context of high-resolution image understanding. In this paper, we propose a novel token compression method, GlobalCom$^2$, tailored for high-resolution MLLMs that receive both the thumbnail and multiple crops. GlobalCom$^2$ treats the tokens derived from the thumbnail as the ``commander'' of the entire token compression process, directing the allocation of retention ratios and the specific compression for each crop. In this way, redundant tokens are eliminated while important local details are adaptively preserved to the highest extent feasible. Empirical results across 10 benchmarks reveal that GlobalCom$^2$ achieves an optimal balance between performance and efficiency, and consistently outperforms state-of-the-art token compression methods with LLaVA-NeXT-7B/13B models. Our code is released at \url{https://github.com/xuyang-liu16/GlobalCom2}.
Token Preference Optimization with Self-Calibrated Visual-Anchored Rewards for Hallucination Mitigation
Dec 19, 2024Direct Preference Optimization (DPO) has been demonstrated to be highly effective in mitigating hallucinations in Large Vision Language Models (LVLMs) by aligning their outputs more closely with human preferences. Despite the recent progress, existing methods suffer from two drawbacks: 1) Lack of scalable token-level rewards; and 2) Neglect of visual-anchored tokens. To this end, we propose a novel Token Preference Optimization model with self-calibrated rewards (dubbed as TPO), which adaptively attends to visual-correlated tokens without fine-grained annotations. Specifically, we introduce a token-level \emph{visual-anchored} \emph{reward} as the difference of the logistic distributions of generated tokens conditioned on the raw image and the corrupted one. In addition, to highlight the informative visual-anchored tokens, a visual-aware training objective is proposed to enhance more accurate token-level optimization. Extensive experimental results have manifested the state-of-the-art performance of the proposed TPO. For example, by building on top of LLAVA-1.5-7B, our TPO boosts the performance absolute improvement for hallucination benchmarks.
HopPG: Self-Iterative Program Generation for Multi-Hop Question Answering over Heterogeneous Knowledge
Sep 10, 2023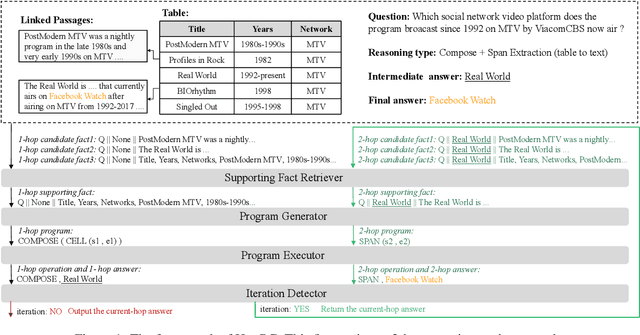
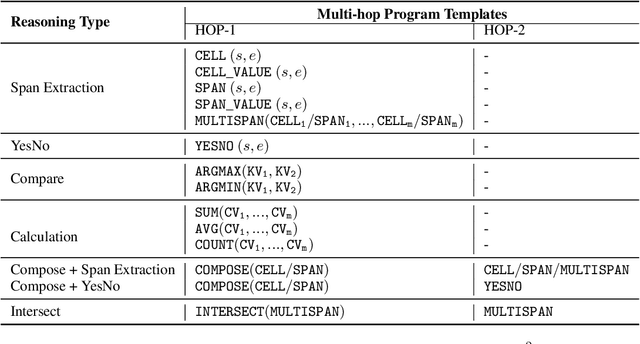
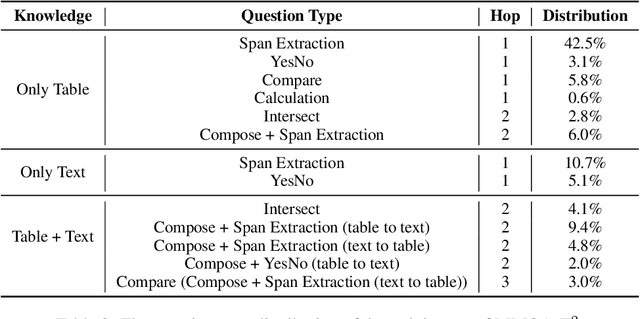

The semantic parsing-based method is an important research branch for knowledge-based question answering. It usually generates executable programs lean upon the question and then conduct them to reason answers over a knowledge base. Benefit from this inherent mechanism, it has advantages in the performance and the interpretability. However, traditional semantic parsing methods usually generate a complete program before executing it, which struggles with multi-hop question answering over heterogeneous knowledge. On one hand, generating a complete multi-hop program relies on multiple heterogeneous supporting facts, and it is difficult for generators to understand these facts simultaneously. On the other hand, this way ignores the semantic information of the intermediate answers at each hop, which is beneficial for subsequent generation. To alleviate these challenges, we propose a self-iterative framework for multi-hop program generation (HopPG) over heterogeneous knowledge, which leverages the previous execution results to retrieve supporting facts and generate subsequent programs hop by hop. We evaluate our model on MMQA-T^2, and the experimental results show that HopPG outperforms existing semantic-parsing-based baselines, especially on the multi-hop questions.
MuGER$^2$: Multi-Granularity Evidence Retrieval and Reasoning for Hybrid Question Answering
Oct 19, 2022
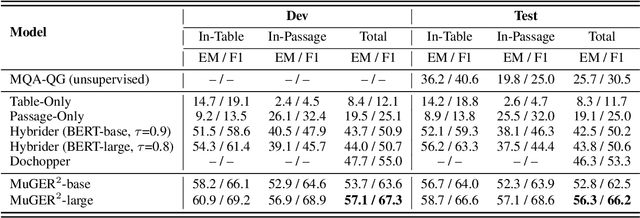
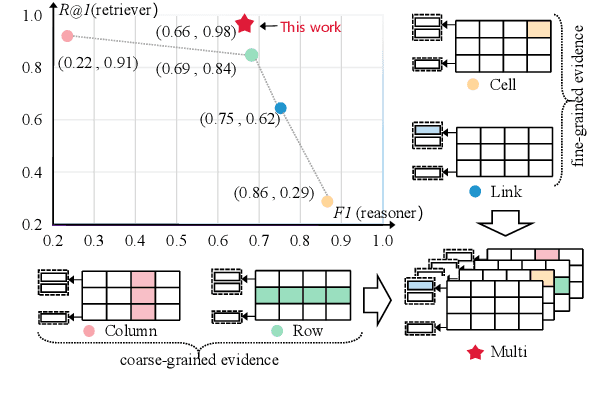
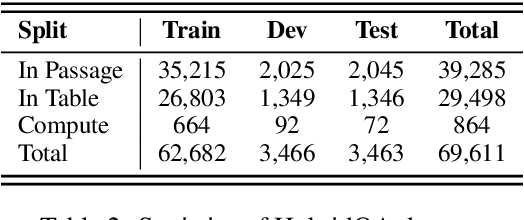
Hybrid question answering (HQA) aims to answer questions over heterogeneous data, including tables and passages linked to table cells. The heterogeneous data can provide different granularity evidence to HQA models, e.t., column, row, cell, and link. Conventional HQA models usually retrieve coarse- or fine-grained evidence to reason the answer. Through comparison, we find that coarse-grained evidence is easier to retrieve but contributes less to the reasoner, while fine-grained evidence is the opposite. To preserve the advantage and eliminate the disadvantage of different granularity evidence, we propose MuGER$^2$, a Multi-Granularity Evidence Retrieval and Reasoning approach. In evidence retrieval, a unified retriever is designed to learn the multi-granularity evidence from the heterogeneous data. In answer reasoning, an evidence selector is proposed to navigate the fine-grained evidence for the answer reader based on the learned multi-granularity evidence. Experiment results on the HybridQA dataset show that MuGER$^2$ significantly boosts the HQA performance. Further ablation analysis verifies the effectiveness of both the retrieval and reasoning designs.