 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Token Pruning for Historical Screenshots in GUI Visual Agents: Semantic, Spatial, and Temporal Perspectives
Mar 27, 2026In recent years, GUI visual agents built upon Multimodal Large Language Models (MLLMs) have demonstrated strong potential in navigation tasks. However, high-resolution GUI screenshots produce a large number of visual tokens, making the direct preservation of complete historical information computationally expensive. In this paper, we conduct an empirical study on token pruning for historical screenshots in GUI scenarios and distill three practical insights that are crucial for designing effective pruning strategies. First, we observe that GUI screenshots exhibit a distinctive foreground-background semantic composition. To probe this property, we apply a simple edge-based separation to partition screenshots into foreground and background regions. Surprisingly, we find that, contrary to the common assumption that background areas have little semantic value, they effectively capture interface-state transitions, thereby providing auxiliary cues for GUI reasoning. Second, compared with carefully designed pruning strategies, random pruning possesses an inherent advantage in preserving spatial structure, enabling better performance under the same computational budget. Finally, we observe that GUI Agents exhibit a recency effect similar to human cognition: by allocating larger token budgets to more recent screenshots and heavily compressing distant ones, we can significantly reduce computational cost while maintaining nearly unchanged performance. These findings offer new insights and practical guidance for the design of efficient GUI visual agents.
LEMUR: Large scale End-to-end MUltimodal Recommendation
Nov 17, 2025Traditional ID-based recommender systems often struggle with cold-start and generalization challenges. Multimodal recommendation systems, which leverage textual and visual data, offer a promising solution to mitigate these issues. However, existing industrial approaches typically adopt a two-stage training paradigm: first pretraining a multimodal model, then applying its frozen representations to train the recommendation model. This decoupled framework suffers from misalignment between multimodal learning and recommendation objectives, as well as an inability to adapt dynamically to new data. To address these limitations, we propose LEMUR, the first large-scale multimodal recommender system trained end-to-end from raw data. By jointly optimizing both the multimodal and recommendation components, LEMUR ensures tighter alignment with downstream objectives while enabling real-time parameter updates. Constructing multimodal sequential representations from user history often entails prohibitively high computational costs. To alleviate this bottleneck, we propose a novel memory bank mechanism that incrementally accumulates historical multimodal representations throughout the training process. After one month of deployment in Douyin Search, LEMUR has led to a 0.843% reduction in query change rate decay and a 0.81% improvement in QAUC. Additionally, LEMUR has shown significant gains across key offline metrics for Douyin Advertisement. Our results validate the superiority of end-to-end multimodal recommendation in real-world industrial scenarios.
Shifting AI Efficiency From Model-Centric to Data-Centric Compression
May 25, 2025The rapid advancement of large language models (LLMs) and multi-modal LLMs (MLLMs) has historically relied on model-centric scaling through increasing parameter counts from millions to hundreds of billions to drive performance gains. However, as we approach hardware limits on model size, the dominant computational bottleneck has fundamentally shifted to the quadratic cost of self-attention over long token sequences, now driven by ultra-long text contexts, high-resolution images, and extended videos. In this position paper, \textbf{we argue that the focus of research for efficient AI is shifting from model-centric compression to data-centric compression}. We position token compression as the new frontier, which improves AI efficiency via reducing the number of tokens during model training or inference. Through comprehensive analysis, we first examine recent developments in long-context AI across various domains and establish a unified mathematical framework for existing model efficiency strategies, demonstrating why token compression represents a crucial paradigm shift in addressing long-context overhead. Subsequently, we systematically review the research landscape of token compression, analyzing its fundamental benefits and identifying its compelling advantages across diverse scenarios. Furthermore, we provide an in-depth analysis of current challenges in token compression research and outline promising future directions. Ultimately, our work aims to offer a fresh perspective on AI efficiency, synthesize existing research, and catalyze innovative developments to address the challenges that increasing context lengths pose to the AI community's advancement.
Compression with Global Guidance: Towards Training-free High-Resolution MLLMs Acceleration
Jan 09, 2025



Multimodal large language models (MLLMs) have attracted considerable attention due to their exceptional performance in visual content understanding and reasoning. However, their inference efficiency has been a notable concern, as the increasing length of multimodal contexts leads to quadratic complexity. Token compression techniques, which reduce the number of visual tokens, have demonstrated their effectiveness in reducing computational costs. Yet, these approaches have struggled to keep pace with the rapid advancements in MLLMs, especially the AnyRes strategy in the context of high-resolution image understanding. In this paper, we propose a novel token compression method, GlobalCom$^2$, tailored for high-resolution MLLMs that receive both the thumbnail and multiple crops. GlobalCom$^2$ treats the tokens derived from the thumbnail as the ``commander'' of the entire token compression process, directing the allocation of retention ratios and the specific compression for each crop. In this way, redundant tokens are eliminated while important local details are adaptively preserved to the highest extent feasible. Empirical results across 10 benchmarks reveal that GlobalCom$^2$ achieves an optimal balance between performance and efficiency, and consistently outperforms state-of-the-art token compression methods with LLaVA-NeXT-7B/13B models. Our code is released at \url{https://github.com/xuyang-liu16/GlobalCom2}.
Rethinking Token Reduction in MLLMs: Towards a Unified Paradigm for Training-Free Acceleration
Nov 26, 2024



To accelerate the inference of heavy Multimodal Large Language Models (MLLMs), this study rethinks the current landscape of training-free token reduction research. We regret to find that the critical components of existing methods are tightly intertwined, with their interconnections and effects remaining unclear for comparison, transfer, and expansion. Therefore, we propose a unified ''filter-correlate-compress'' paradigm that decomposes the token reduction into three distinct stages within a pipeline, maintaining consistent design objectives and elements while allowing for unique implementations. We additionally demystify the popular works and subsume them into our paradigm to showcase its universality. Finally, we offer a suite of methods grounded in the paradigm, striking a balance between speed and accuracy throughout different phases of the inference. Experimental results across 10 benchmarks indicate that our methods can achieve up to an 82.4% reduction in FLOPs with a minimal impact on performance, simultaneously surpassing state-of-the-art training-free methods. Our project page is at https://ficoco-accelerate.github.io/.
M$^2$IST: Multi-Modal Interactive Side-Tuning for Memory-efficient Referring Expression Comprehension
Jul 01, 2024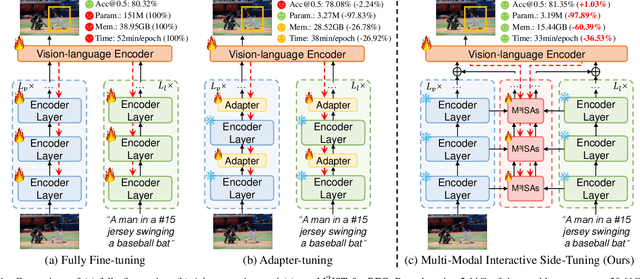

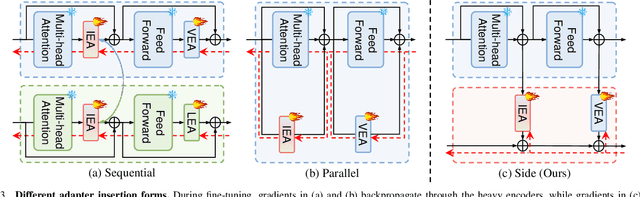

Referring expression comprehension (REC) is a vision-language task to locate a target object in an image based on a language expression. Fully fine-tuning general-purpose pre-trained models for REC yields impressive performance but becomes increasingly costly. Parameter-efficient transfer learning (PETL) methods have shown strong performance with fewer tunable parameters. However, applying PETL to REC faces two challenges: (1) insufficient interaction between pre-trained vision and language encoders, and (2) high GPU memory usage due to gradients passing through both heavy encoders. To address these issues, we present M$^2$IST: Multi-Modal Interactive Side-Tuning with M$^3$ISAs: Mixture of Multi-Modal Interactive Side-Adapters. During fine-tuning, we keep the pre-trained vision and language encoders fixed and update M$^3$ISAs on side networks to establish connections between them, thereby achieving parameter- and memory-efficient tuning for REC. Empirical results on three benchmarks show M$^2$IST achieves the best performance-parameter-memory trade-off compared to full fine-tuning and other PETL methods, with only 3.14M tunable parameters (2.11% of full fine-tuning) and 15.44GB GPU memory usage (39.61% of full fine-tuning). Source code will soon be publicly available.
Perception- and Fidelity-aware Reduced-Reference Super-Resolution Image Quality Assessment
May 15, 2024



With the advent of image super-resolution (SR) algorithms, how to evaluate the quality of generated SR images has become an urgent task. Although full-reference methods perform well in SR image quality assessment (SR-IQA), their reliance on high-resolution (HR) images limits their practical applicability. Leveraging available reconstruction information as much as possible for SR-IQA, such as low-resolution (LR) images and the scale factors, is a promising way to enhance assessment performance for SR-IQA without HR for reference. In this letter, we attempt to evaluate the perceptual quality and reconstruction fidelity of SR images considering LR images and scale factors. Specifically, we propose a novel dual-branch reduced-reference SR-IQA network, \ie, Perception- and Fidelity-aware SR-IQA (PFIQA). The perception-aware branch evaluates the perceptual quality of SR images by leveraging the merits of global modeling of Vision Transformer (ViT) and local relation of ResNet, and incorporating the scale factor to enable comprehensive visual perception. Meanwhile, the fidelity-aware branch assesses the reconstruction fidelity between LR and SR images through their visual perception. The combination of the two branches substantially aligns with the human visual system, enabling a comprehensive SR image evaluation. Experimental results indicate that our PFIQA outperforms current state-of-the-art models across three widely-used SR-IQA benchmarks. Notably, PFIQA excels in assessing the quality of real-world SR images.
DARA: Domain- and Relation-aware Adapters Make Parameter-efficient Tuning for Visual Grounding
May 10, 2024Visual grounding (VG) is a challenging task to localize an object in an image based on a textual description. Recent surge in the scale of VG models has substantially improved performance, but also introduced a significant burden on computational costs during fine-tuning. In this paper, we explore applying parameter-efficient transfer learning (PETL) to efficiently transfer the pre-trained vision-language knowledge to VG. Specifically, we propose \textbf{DARA}, a novel PETL method comprising \underline{\textbf{D}}omain-aware \underline{\textbf{A}}dapters (DA Adapters) and \underline{\textbf{R}}elation-aware \underline{\textbf{A}}dapters (RA Adapters) for VG. DA Adapters first transfer intra-modality representations to be more fine-grained for the VG domain. Then RA Adapters share weights to bridge the relation between two modalities, improving spatial reasoning. Empirical results on widely-used benchmarks demonstrate that DARA achieves the best accuracy while saving numerous updated parameters compared to the full fine-tuning and other PETL methods. Notably, with only \textbf{2.13\%} tunable backbone parameters, DARA improves average accuracy by \textbf{0.81\%} across the three benchmarks compared to the baseline model. Our code is available at \url{https://github.com/liuting20/DARA}.
Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application
May 07, 2024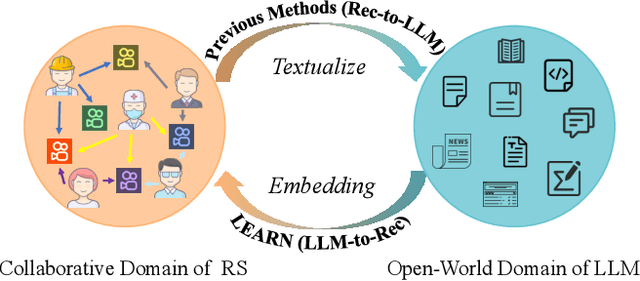


Contemporary recommender systems predominantly rely on collaborative filtering techniques, employing ID-embedding to capture latent associations among users and items. However, this approach overlooks the wealth of semantic information embedded within textual descriptions of items, leading to suboptimal performance in cold-start scenarios and long-tail user recommendations. Leveraging the capabilities of Large Language Models (LLMs) pretrained on massive text corpus presents a promising avenue for enhancing recommender systems by integrating open-world domain knowledge. In this paper, we propose an Llm-driven knowlEdge Adaptive RecommeNdation (LEARN) framework that synergizes open-world knowledge with collaborative knowledge. We address computational complexity concerns by utilizing pretrained LLMs as item encoders and freezing LLM parameters to avoid catastrophic forgetting and preserve open-world knowledge. To bridge the gap between the open-world and collaborative domains, we design a twin-tower structure supervised by the recommendation task and tailored for practical industrial application. Through offline experiments on the large-scale industrial dataset and online experiments on A/B tests, we demonstrate the efficacy of our approach.
Efficient Meta-Learning Enabled Lightweight Multiscale Few-Shot Object Detection in Remote Sensing Images
Apr 29, 2024



Presently, the task of few-shot object detection (FSOD) in remote sensing images (RSIs) has become a focal point of attention. Numerous few-shot detectors, particularly those based on two-stage detectors, face challenges when dealing with the multiscale complexities inherent in RSIs. Moreover, these detectors present impractical characteristics in real-world applications, mainly due to their unwieldy model parameters when handling large amount of data. In contrast, we recognize the advantages of one-stage detectors, including high detection speed and a global receptive field. Consequently, we choose the YOLOv7 one-stage detector as a baseline and subject it to a novel meta-learning training framework. This transformation allows the detector to adeptly address FSOD tasks while capitalizing on its inherent advantage of lightweight. Additionally, we thoroughly investigate the samples generated by the meta-learning strategy and introduce a novel meta-sampling approach to retain samples produced by our designed meta-detection head. Coupled with our devised meta-cross loss, we deliberately utilize ``negative samples" that are often overlooked to extract valuable knowledge from them. This approach serves to enhance detection accuracy and efficiently refine the overall meta-learning strategy. To validate the effectiveness of our proposed detector, we conducted performance comparisons with current state-of-the-art detectors using the DIOR and NWPU VHR-10.v2 datasets, yielding satisfactory results.