 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-GRPO: Optimizing Multi-Human Identity-preserving Video Generation via Reinforcement Learning
Oct 16, 2025While advanced methods like VACE and Phantom have advanced video generation for specific subjects in diverse scenarios, they struggle with multi-human identity preservation in dynamic interactions, where consistent identities across multiple characters are critical. To address this, we propose Identity-GRPO, a human feedback-driven optimization pipeline for refining multi-human identity-preserving video generation. First, we construct a video reward model trained on a large-scale preference dataset containing human-annotated and synthetic distortion data, with pairwise annotations focused on maintaining human consistency throughout the video. We then employ a GRPO variant tailored for multi-human consistency, which greatly enhances both VACE and Phantom. Through extensive ablation studies, we evaluate the impact of annotation quality and design choices on policy optimization. Experiments show that Identity-GRPO achieves up to 18.9% improvement in human consistency metrics over baseline methods, offering actionable insights for aligning reinforcement learning with personalized video generation.
Controlling Language Difficulty in Dialogues with Linguistic Features
Sep 18, 2025Large language models (LLMs) have emerged as powerful tools for supporting second language acquisition, particularly in simulating interactive dialogues for speaking practice. However, adapting the language difficulty of LLM-generated responses to match learners' proficiency levels remains a challenge. This work addresses this issue by proposing a framework for controlling language proficiency in educational dialogue systems. Our approach leverages three categories of linguistic features, readability features (e.g., Flesch-Kincaid Grade Level), syntactic features (e.g., syntactic tree depth), and lexical features (e.g., simple word ratio), to quantify and regulate text complexity. We demonstrate that training LLMs on linguistically annotated dialogue data enables precise modulation of language proficiency, outperforming prompt-based methods in both flexibility and stability. To evaluate this, we introduce Dilaprix, a novel metric integrating the aforementioned features, which shows strong correlation with expert judgments of language difficulty. Empirical results reveal that our approach achieves superior controllability of language proficiency while maintaining high dialogue quality.
High-Performance Parallel Optimization of the Fish School Behaviour on the Setonix Platform Using OpenMP
Jul 27, 2025
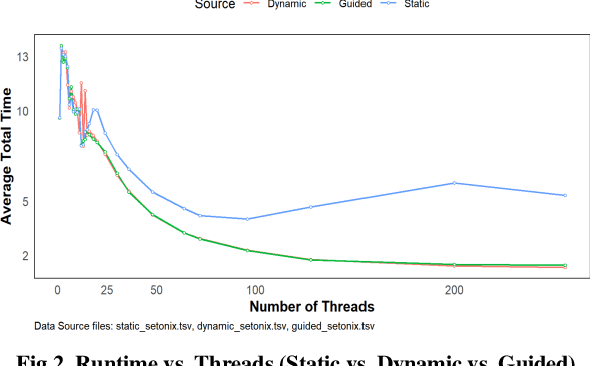
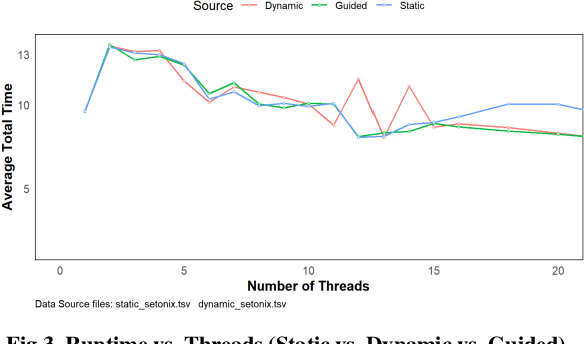
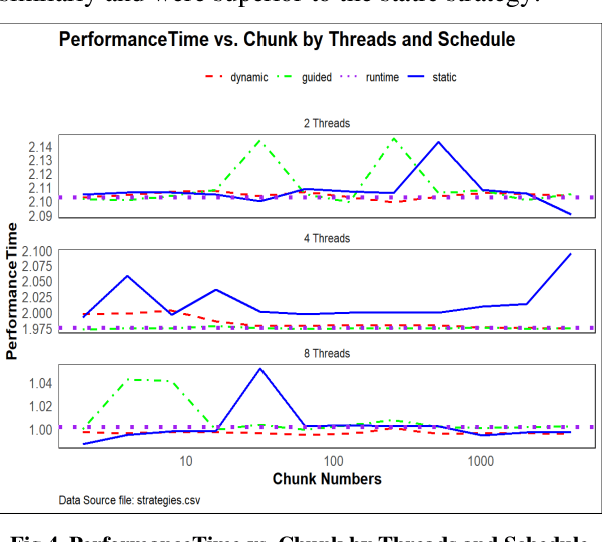
This paper presents an in-depth investigation into the high-performance parallel optimization of the Fish School Behaviour (FSB) algorithm on the Setonix supercomputing platform using the OpenMP framework. Given the increasing demand for enhanced computational capabilities for complex, large-scale calculations across diverse domains, there's an imperative need for optimized parallel algorithms and computing structures. The FSB algorithm, inspired by nature's social behavior patterns, provides an ideal platform for parallelization due to its iterative and computationally intensive nature. This study leverages the capabilities of the Setonix platform and the OpenMP framework to analyze various aspects of multi-threading, such as thread counts, scheduling strategies, and OpenMP constructs, aiming to discern patterns and strategies that can elevate program performance. Experiments were designed to rigorously test different configurations, and our results not only offer insights for parallel optimization of FSB on Setonix but also provide valuable references for other parallel computational research using OpenMP. Looking forward, other factors, such as cache behavior and thread scheduling strategies at micro and macro levels, hold potential for further exploration and optimization.
Tora: Trajectory-oriented Diffusion Transformer for Video Generation
Jul 31, 2024Recent advancements in Diffusion Transformer (DiT) have demonstrated remarkable proficiency in producing high-quality video content. Nonetheless, the potential of transformer-based diffusion models for effectively generating videos with controllable motion remains an area of limited exploration. This paper introduces Tora, the first trajectory-oriented DiT framework that integrates textual, visual, and trajectory conditions concurrently for video generation. Specifically, Tora consists of a Trajectory Extractor~(TE), a Spatial-Temporal DiT, and a Motion-guidance Fuser~(MGF). The TE encodes arbitrary trajectories into hierarchical spacetime motion patches with a 3D video compression network. The MGF integrates the motion patches into the DiT blocks to generate consistent videos following trajectories. Our design aligns seamlessly with DiT's scalability, allowing precise control of video content's dynamics with diverse durations, aspect ratios, and resolutions. Extensive experiments demonstrate Tora's excellence in achieving high motion fidelity, while also meticulously simulating the movement of the physical world. Page can be found at https://ali-videoai.github.io/tora_video.
DARA: Domain- and Relation-aware Adapters Make Parameter-efficient Tuning for Visual Grounding
May 10, 2024Visual grounding (VG) is a challenging task to localize an object in an image based on a textual description. Recent surge in the scale of VG models has substantially improved performance, but also introduced a significant burden on computational costs during fine-tuning. In this paper, we explore applying parameter-efficient transfer learning (PETL) to efficiently transfer the pre-trained vision-language knowledge to VG. Specifically, we propose \textbf{DARA}, a novel PETL method comprising \underline{\textbf{D}}omain-aware \underline{\textbf{A}}dapters (DA Adapters) and \underline{\textbf{R}}elation-aware \underline{\textbf{A}}dapters (RA Adapters) for VG. DA Adapters first transfer intra-modality representations to be more fine-grained for the VG domain. Then RA Adapters share weights to bridge the relation between two modalities, improving spatial reasoning. Empirical results on widely-used benchmarks demonstrate that DARA achieves the best accuracy while saving numerous updated parameters compared to the full fine-tuning and other PETL methods. Notably, with only \textbf{2.13\%} tunable backbone parameters, DARA improves average accuracy by \textbf{0.81\%} across the three benchmarks compared to the baseline model. Our code is available at \url{https://github.com/liuting20/DARA}.
Large Language Model based Situational Dialogues for Second Language Learning
Mar 29, 2024In second language learning, scenario-based conversation practice is important for language learners to achieve fluency in speaking, but students often lack sufficient opportunities to practice their conversational skills with qualified instructors or native speakers. To bridge this gap, we propose situational dialogue models for students to engage in conversational practice. Our situational dialogue models are fine-tuned on large language models (LLMs), with the aim of combining the engaging nature of an open-ended conversation with the focused practice of scenario-based tasks. Leveraging the generalization capabilities of LLMs, we demonstrate that our situational dialogue models perform effectively not only on training topics but also on topics not encountered during training. This offers a promising solution to support a wide range of conversational topics without extensive manual work. Additionally, research in the field of dialogue systems still lacks reliable automatic evaluation metrics, leading to human evaluation as the gold standard (Smith et al., 2022), which is typically expensive. To address the limitations of existing evaluation methods, we present a novel automatic evaluation method that employs fine-tuned LLMs to efficiently and effectively assess the performance of situational dialogue models.
MM-Diff: High-Fidelity Image Personalization via Multi-Modal Condition Integration
Mar 22, 2024
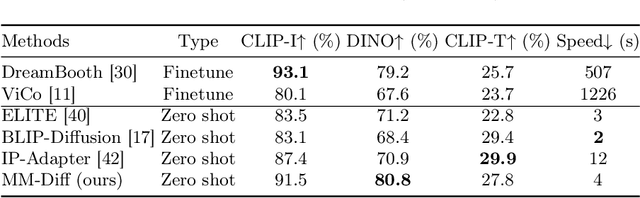
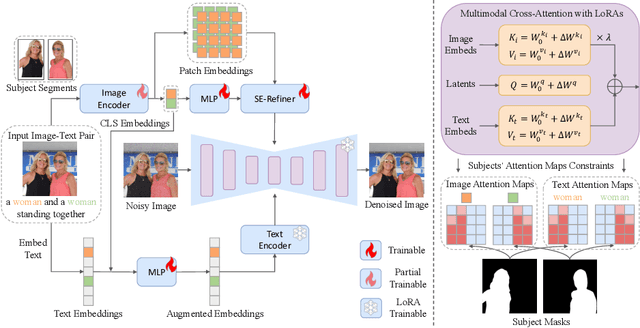
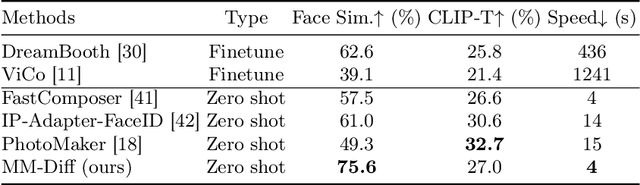
Recent advances in tuning-free personalized image generation based on diffusion models are impressive. However, to improve subject fidelity, existing methods either retrain the diffusion model or infuse it with dense visual embeddings, both of which suffer from poor generalization and efficiency. Also, these methods falter in multi-subject image generation due to the unconstrained cross-attention mechanism. In this paper, we propose MM-Diff, a unified and tuning-free image personalization framework capable of generating high-fidelity images of both single and multiple subjects in seconds. Specifically, to simultaneously enhance text consistency and subject fidelity, MM-Diff employs a vision encoder to transform the input image into CLS and patch embeddings. CLS embeddings are used on the one hand to augment the text embeddings, and on the other hand together with patch embeddings to derive a small number of detail-rich subject embeddings, both of which are efficiently integrated into the diffusion model through the well-designed multimodal cross-attention mechanism. Additionally, MM-Diff introduces cross-attention map constraints during the training phase, ensuring flexible multi-subject image sampling during inference without any predefined inputs (e.g., layout). Extensive experiments demonstrate the superior performance of MM-Diff over other leading methods.
EffiVED:Efficient Video Editing via Text-instruction Diffusion Models
Mar 18, 2024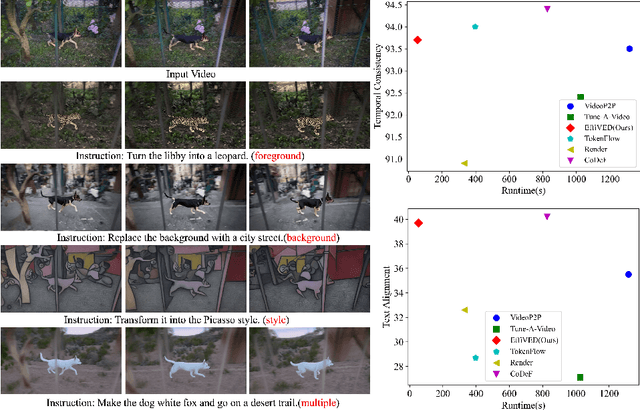
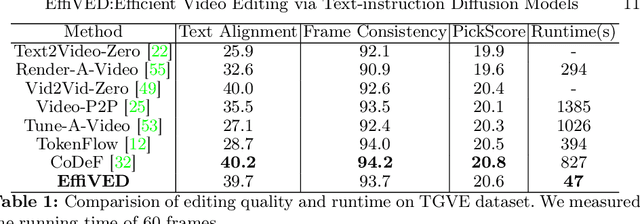
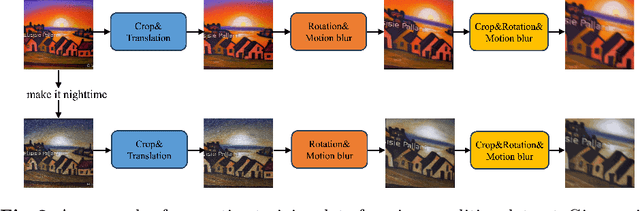
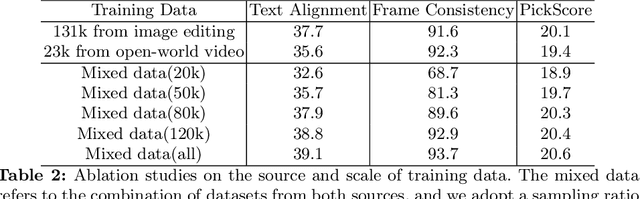
Large-scale text-to-video models have shown remarkable abilities, but their direct application in video editing remains challenging due to limited available datasets. Current video editing methods commonly require per-video fine-tuning of diffusion models or specific inversion optimization to ensure high-fidelity edits. In this paper, we introduce EffiVED, an efficient diffusion-based model that directly supports instruction-guided video editing. To achieve this, we present two efficient workflows to gather video editing pairs, utilizing augmentation and fundamental vision-language techniques. These workflows transform vast image editing datasets and open-world videos into a high-quality dataset for training EffiVED. Experimental results reveal that EffiVED not only generates high-quality editing videos but also executes rapidly. Finally, we demonstrate that our data collection method significantly improves editing performance and can potentially tackle the scarcity of video editing data. The datasets will be made publicly available upon publication.
AnimateAnything: Fine-Grained Open Domain Image Animation with Motion Guidance
Dec 04, 2023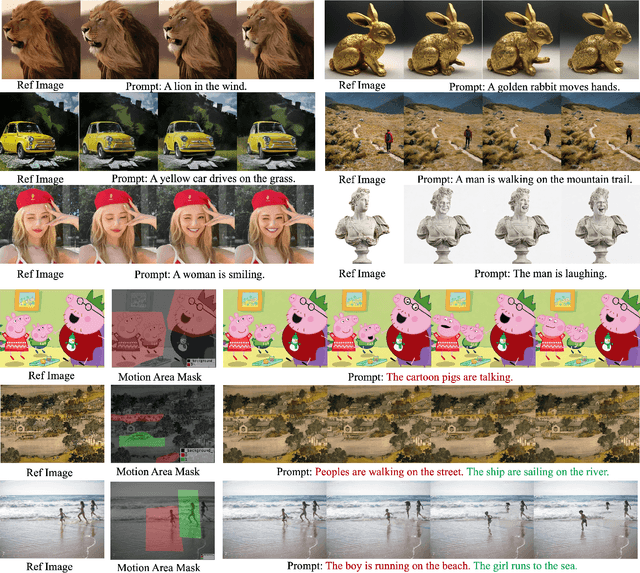
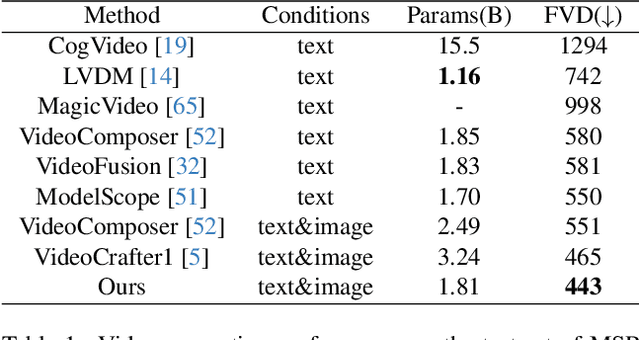
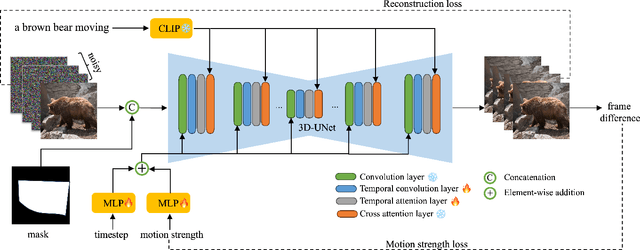
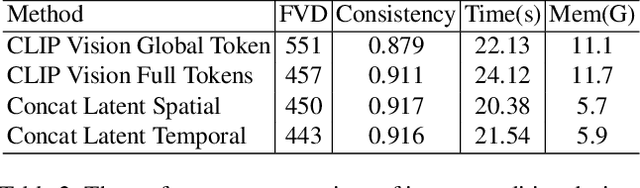
Image animation is a key task in computer vision which aims to generate dynamic visual content from static image. Recent image animation methods employ neural based rendering technique to generate realistic animations. Despite these advancements, achieving fine-grained and controllable image animation guided by text remains challenging, particularly for open-domain images captured in diverse real environments. In this paper, we introduce an open domain image animation method that leverages the motion prior of video diffusion model. Our approach introduces targeted motion area guidance and motion strength guidance, enabling precise control the movable area and its motion speed. This results in enhanced alignment between the animated visual elements and the prompting text, thereby facilitating a fine-grained and interactive animation generation process for intricate motion sequences. We validate the effectiveness of our method through rigorous experiments on an open-domain dataset, with the results showcasing its superior performance. Project page can be found at https://animationai.github.io/AnimateAnything.
How to Evaluate Your Dialogue Models: A Review of Approaches
Aug 03, 2021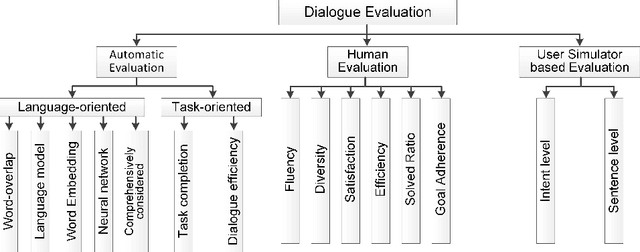

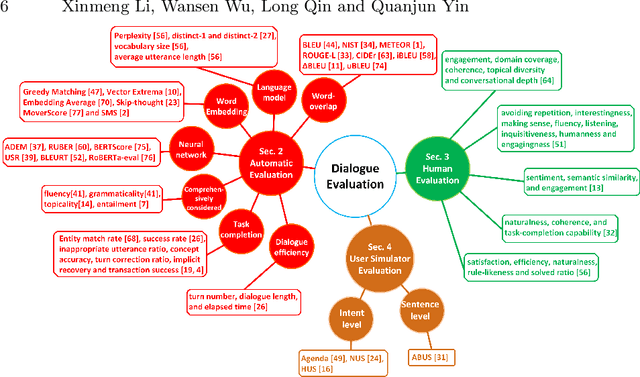
Evaluating the quality of a dialogue system is an understudied problem. The recent evolution of evaluation method motivated this survey, in which an explicit and comprehensive analysis of the existing methods is sought. We are first to divide the evaluation methods into three classes, i.e., automatic evaluation, human-involved evaluation and user simulator based evaluation. Then, each class is covered with main features and the related evaluation metrics. The existence of benchmarks, suitable for the evaluation of dialogue techniques are also discussed in detail. Finally, some open issues are pointed out to bring the evaluation method into a new frontier.