 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Layer Attentive Feature Upsampling for Low-latency Semantic Segmentation
Jan 03, 2026Semantic segmentation is a fundamental problem in computer vision and it requires high-resolution feature maps for dense prediction. Current coordinate-guided low-resolution feature interpolation methods, e.g., bilinear interpolation, produce coarse high-resolution features which suffer from feature misalignment and insufficient context information. Moreover, enriching semantics to high-resolution features requires a high computation burden, so that it is challenging to meet the requirement of lowlatency inference. We propose a novel Guided Attentive Interpolation (GAI) method to adaptively interpolate fine-grained high-resolution features with semantic features to tackle these issues. Guided Attentive Interpolation determines both spatial and semantic relations of pixels from features of different resolutions and then leverages these relations to interpolate high-resolution features with rich semantics. GAI can be integrated with any deep convolutional network for efficient semantic segmentation. In experiments, the GAI-based semantic segmentation networks, i.e., GAIN, can achieve78.8 mIoU with 22.3 FPS on Cityscapes and 80.6 mIoU with 64.5 on CamVid using an NVIDIA 1080Ti GPU, which are the new state-of-the-art results of low-latency semantic segmentation. Code and models are available at: https://github.com/hustvl/simpleseg.
Identity-GRPO: Optimizing Multi-Human Identity-preserving Video Generation via Reinforcement Learning
Oct 16, 2025While advanced methods like VACE and Phantom have advanced video generation for specific subjects in diverse scenarios, they struggle with multi-human identity preservation in dynamic interactions, where consistent identities across multiple characters are critical. To address this, we propose Identity-GRPO, a human feedback-driven optimization pipeline for refining multi-human identity-preserving video generation. First, we construct a video reward model trained on a large-scale preference dataset containing human-annotated and synthetic distortion data, with pairwise annotations focused on maintaining human consistency throughout the video. We then employ a GRPO variant tailored for multi-human consistency, which greatly enhances both VACE and Phantom. Through extensive ablation studies, we evaluate the impact of annotation quality and design choices on policy optimization. Experiments show that Identity-GRPO achieves up to 18.9% improvement in human consistency metrics over baseline methods, offering actionable insights for aligning reinforcement learning with personalized video generation.
Tora: Trajectory-oriented Diffusion Transformer for Video Generation
Jul 31, 2024Recent advancements in Diffusion Transformer (DiT) have demonstrated remarkable proficiency in producing high-quality video content. Nonetheless, the potential of transformer-based diffusion models for effectively generating videos with controllable motion remains an area of limited exploration. This paper introduces Tora, the first trajectory-oriented DiT framework that integrates textual, visual, and trajectory conditions concurrently for video generation. Specifically, Tora consists of a Trajectory Extractor~(TE), a Spatial-Temporal DiT, and a Motion-guidance Fuser~(MGF). The TE encodes arbitrary trajectories into hierarchical spacetime motion patches with a 3D video compression network. The MGF integrates the motion patches into the DiT blocks to generate consistent videos following trajectories. Our design aligns seamlessly with DiT's scalability, allowing precise control of video content's dynamics with diverse durations, aspect ratios, and resolutions. Extensive experiments demonstrate Tora's excellence in achieving high motion fidelity, while also meticulously simulating the movement of the physical world. Page can be found at https://ali-videoai.github.io/tora_video.
Knowledge Mining with Scene Text for Fine-Grained Recognition
Mar 27, 2022
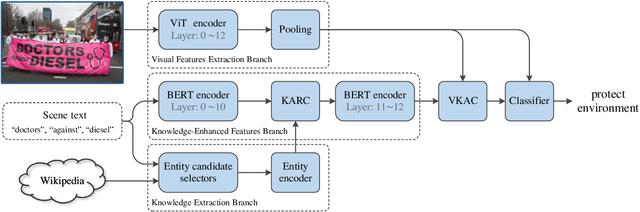


Recently, the semantics of scene text has been proven to be essential in fine-grained image classification. However, the existing methods mainly exploit the literal meaning of scene text for fine-grained recognition, which might be irrelevant when it is not significantly related to objects/scenes. We propose an end-to-end trainable network that mines implicit contextual knowledge behind scene text image and enhance the semantics and correlation to fine-tune the image representation. Unlike the existing methods, our model integrates three modalities: visual feature extraction, text semantics extraction, and correlating background knowledge to fine-grained image classification. Specifically, we employ KnowBert to retrieve relevant knowledge for semantic representation and combine it with image features for fine-grained classification. Experiments on two benchmark datasets, Con-Text, and Drink Bottle, show that our method outperforms the state-of-the-art by 3.72\% mAP and 5.39\% mAP, respectively. To further validate the effectiveness of the proposed method, we create a new dataset on crowd activity recognition for the evaluation. The source code and new dataset of this work are available at https://github.com/lanfeng4659/KnowledgeMiningWithSceneText.