 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTora3: Trajectory-Guided Audio-Video Generation with Physical Coherence
Apr 10, 2026Audio-video (AV) generation has recently made strong progress in perceptual quality and multimodal coherence, yet generating content with plausible motion-sound relations remains challenging. Existing methods often produce object motions that are visually unstable and sounds that are only loosely aligned with salient motion or contact events, largely because they lack an explicit motion-aware structure shared by video and audio generation. We present Tora3, a trajectory-guided AV generation framework that improves physical coherence by using object trajectories as a shared kinematic prior. Rather than treating trajectories as a video-only control signal, Tora3 uses them to jointly guide visual motion and acoustic events. Specifically, we design a trajectory-aligned motion representation for video, a kinematic-audio alignment module driven by trajectory-derived second-order kinematic states, and a hybrid flow matching scheme that preserves trajectory fidelity in trajectory-conditioned regions while maintaining local coherence elsewhere. We further curate PAV, a large-scale AV dataset emphasizing motion-relevant patterns with automatically extracted motion annotations. Extensive experiments show that Tora3 improves motion realism, motion-sound synchronization, and overall AV generation quality over strong open-source baselines.
PaperX: A Unified Framework for Multimodal Academic Presentation Generation with Scholar DAG
Feb 05, 2026Transforming scientific papers into multimodal presentation content is essential for research dissemination but remains labor intensive. Existing automated solutions typically treat each format as an isolated downstream task, leading to redundant processing and semantic inconsistency. We introduce PaperX, a unified framework that models academic presentation generation as a structural transformation and rendering process. Central to our approach is the Scholar DAG, an intermediate representation that decouples the paper's logical structure from its final presentation syntax. By applying adaptive graph traversal strategies, PaperX generates diverse, high quality outputs from a single source. Comprehensive evaluations demonstrate that our framework achieves the state of the art performance in content fidelity and aesthetic quality while significantly improving cost efficiency compared to specialized single task agents.
ShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
SpaceDrive: Infusing Spatial Awareness into VLM-based Autonomous Driving
Dec 11, 2025End-to-end autonomous driving methods built on vision language models (VLMs) have undergone rapid development driven by their universal visual understanding and strong reasoning capabilities obtained from the large-scale pretraining. However, we find that current VLMs struggle to understand fine-grained 3D spatial relationships which is a fundamental requirement for systems interacting with the physical world. To address this issue, we propose SpaceDrive, a spatial-aware VLM-based driving framework that treats spatial information as explicit positional encodings (PEs) instead of textual digit tokens, enabling joint reasoning over semantic and spatial representations. SpaceDrive employs a universal positional encoder to all 3D coordinates derived from multi-view depth estimation, historical ego-states, and text prompts. These 3D PEs are first superimposed to augment the corresponding 2D visual tokens. Meanwhile, they serve as a task-agnostic coordinate representation, replacing the digit-wise numerical tokens as both inputs and outputs for the VLM. This mechanism enables the model to better index specific visual semantics in spatial reasoning and directly regress trajectory coordinates rather than generating digit-by-digit, thereby enhancing planning accuracy. Extensive experiments validate that SpaceDrive achieves state-of-the-art open-loop performance on the nuScenes dataset and the second-best Driving Score of 78.02 on the Bench2Drive closed-loop benchmark over existing VLM-based methods.
Dynamic Deep Graph Learning for Incomplete Multi-View Clustering with Masked Graph Reconstruction Loss
Nov 14, 2025The prevalence of real-world multi-view data makes incomplete multi-view clustering (IMVC) a crucial research. The rapid development of Graph Neural Networks (GNNs) has established them as one of the mainstream approaches for multi-view clustering. Despite significant progress in GNNs-based IMVC, some challenges remain: (1) Most methods rely on the K-Nearest Neighbors (KNN) algorithm to construct static graphs from raw data, which introduces noise and diminishes the robustness of the graph topology. (2) Existing methods typically utilize the Mean Squared Error (MSE) loss between the reconstructed graph and the sparse adjacency graph directly as the graph reconstruction loss, leading to substantial gradient noise during optimization. To address these issues, we propose a novel \textbf{D}ynamic Deep \textbf{G}raph Learning for \textbf{I}ncomplete \textbf{M}ulti-\textbf{V}iew \textbf{C}lustering with \textbf{M}asked Graph Reconstruction Loss (DGIMVCM). Firstly, we construct a missing-robust global graph from the raw data. A graph convolutional embedding layer is then designed to extract primary features and refined dynamic view-specific graph structures, leveraging the global graph for imputation of missing views. This process is complemented by graph structure contrastive learning, which identifies consistency among view-specific graph structures. Secondly, a graph self-attention encoder is introduced to extract high-level representations based on the imputed primary features and view-specific graphs, and is optimized with a masked graph reconstruction loss to mitigate gradient noise during optimization. Finally, a clustering module is constructed and optimized through a pseudo-label self-supervised training mechanism. Extensive experiments on multiple datasets validate the effectiveness and superiority of DGIMVCM.
Identity-GRPO: Optimizing Multi-Human Identity-preserving Video Generation via Reinforcement Learning
Oct 16, 2025While advanced methods like VACE and Phantom have advanced video generation for specific subjects in diverse scenarios, they struggle with multi-human identity preservation in dynamic interactions, where consistent identities across multiple characters are critical. To address this, we propose Identity-GRPO, a human feedback-driven optimization pipeline for refining multi-human identity-preserving video generation. First, we construct a video reward model trained on a large-scale preference dataset containing human-annotated and synthetic distortion data, with pairwise annotations focused on maintaining human consistency throughout the video. We then employ a GRPO variant tailored for multi-human consistency, which greatly enhances both VACE and Phantom. Through extensive ablation studies, we evaluate the impact of annotation quality and design choices on policy optimization. Experiments show that Identity-GRPO achieves up to 18.9% improvement in human consistency metrics over baseline methods, offering actionable insights for aligning reinforcement learning with personalized video generation.
Tora: Trajectory-oriented Diffusion Transformer for Video Generation
Jul 31, 2024Recent advancements in Diffusion Transformer (DiT) have demonstrated remarkable proficiency in producing high-quality video content. Nonetheless, the potential of transformer-based diffusion models for effectively generating videos with controllable motion remains an area of limited exploration. This paper introduces Tora, the first trajectory-oriented DiT framework that integrates textual, visual, and trajectory conditions concurrently for video generation. Specifically, Tora consists of a Trajectory Extractor~(TE), a Spatial-Temporal DiT, and a Motion-guidance Fuser~(MGF). The TE encodes arbitrary trajectories into hierarchical spacetime motion patches with a 3D video compression network. The MGF integrates the motion patches into the DiT blocks to generate consistent videos following trajectories. Our design aligns seamlessly with DiT's scalability, allowing precise control of video content's dynamics with diverse durations, aspect ratios, and resolutions. Extensive experiments demonstrate Tora's excellence in achieving high motion fidelity, while also meticulously simulating the movement of the physical world. Page can be found at https://ali-videoai.github.io/tora_video.
MapLocNet: Coarse-to-Fine Feature Registration for Visual Re-Localization in Navigation Maps
Jul 11, 2024



Robust localization is the cornerstone of autonomous driving, especially in challenging urban environments where GPS signals suffer from multipath errors. Traditional localization approaches rely on high-definition (HD) maps, which consist of precisely annotated landmarks. However, building HD map is expensive and challenging to scale up. Given these limitations, leveraging navigation maps has emerged as a promising low-cost alternative for localization. Current approaches based on navigation maps can achieve highly accurate localization, but their complex matching strategies lead to unacceptable inference latency that fails to meet the real-time demands. To address these limitations, we propose a novel transformer-based neural re-localization method. Inspired by image registration, our approach performs a coarse-to-fine neural feature registration between navigation map and visual bird's-eye view features. Our method significantly outperforms the current state-of-the-art OrienterNet on both the nuScenes and Argoverse datasets, which is nearly 10%/20% localization accuracy and 30/16 FPS improvement on single-view and surround-view input settings, separately. We highlight that our research presents an HD-map-free localization method for autonomous driving, offering cost-effective, reliable, and scalable performance in challenging driving environments.
BLOS-BEV: Navigation Map Enhanced Lane Segmentation Network, Beyond Line of Sight
Jul 11, 2024



Bird's-eye-view (BEV) representation is crucial for the perception function in autonomous driving tasks. It is difficult to balance the accuracy, efficiency and range of BEV representation. The existing works are restricted to a limited perception range within 50 meters. Extending the BEV representation range can greatly benefit downstream tasks such as topology reasoning, scene understanding, and planning by offering more comprehensive information and reaction time. The Standard-Definition (SD) navigation maps can provide a lightweight representation of road structure topology, characterized by ease of acquisition and low maintenance costs. An intuitive idea is to combine the close-range visual information from onboard cameras with the beyond line-of-sight (BLOS) environmental priors from SD maps to realize expanded perceptual capabilities. In this paper, we propose BLOS-BEV, a novel BEV segmentation model that incorporates SD maps for accurate beyond line-of-sight perception, up to 200m. Our approach is applicable to common BEV architectures and can achieve excellent results by incorporating information derived from SD maps. We explore various feature fusion schemes to effectively integrate the visual BEV representations and semantic features from the SD map, aiming to leverage the complementary information from both sources optimally. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in BEV segmentation on nuScenes and Argoverse benchmark. Through multi-modal inputs, BEV segmentation is significantly enhanced at close ranges below 50m, while also demonstrating superior performance in long-range scenarios, surpassing other methods by over 20% mIoU at distances ranging from 50-200m.
EffiVED:Efficient Video Editing via Text-instruction Diffusion Models
Mar 18, 2024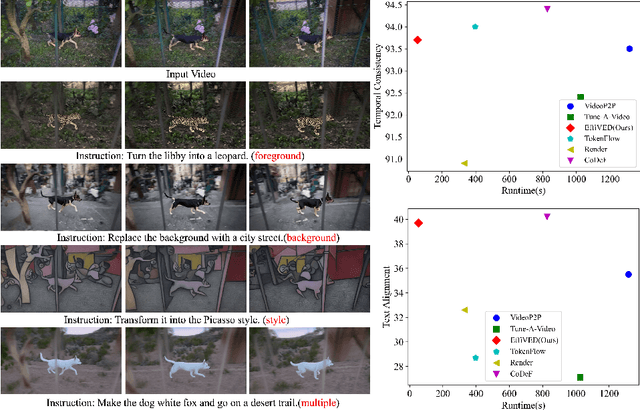
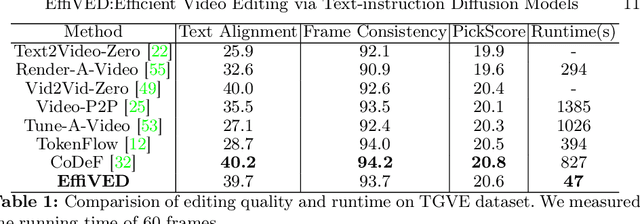
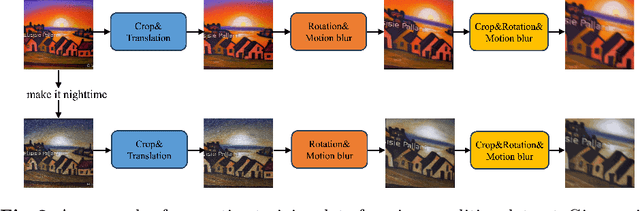
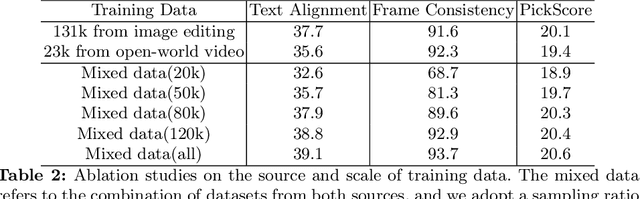
Large-scale text-to-video models have shown remarkable abilities, but their direct application in video editing remains challenging due to limited available datasets. Current video editing methods commonly require per-video fine-tuning of diffusion models or specific inversion optimization to ensure high-fidelity edits. In this paper, we introduce EffiVED, an efficient diffusion-based model that directly supports instruction-guided video editing. To achieve this, we present two efficient workflows to gather video editing pairs, utilizing augmentation and fundamental vision-language techniques. These workflows transform vast image editing datasets and open-world videos into a high-quality dataset for training EffiVED. Experimental results reveal that EffiVED not only generates high-quality editing videos but also executes rapidly. Finally, we demonstrate that our data collection method significantly improves editing performance and can potentially tackle the scarcity of video editing data. The datasets will be made publicly available upon publication.