 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Generative Adversarial Networks with Crossover Based Knowledge Distillation
Jan 27, 2021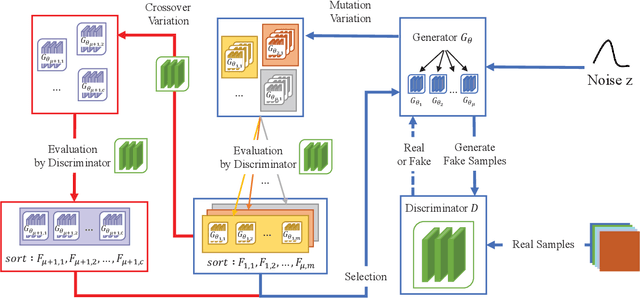

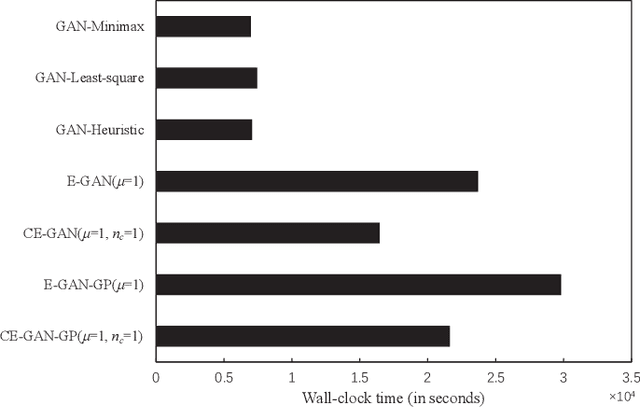
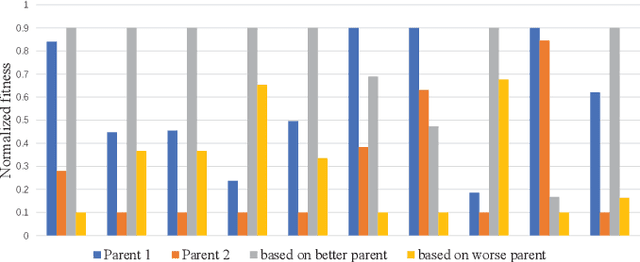
Generative Adversarial Networks (GAN) is an adversarial model, and it has been demonstrated to be effective for various generative tasks. However, GAN and its variants also suffer from many training problems, such as mode collapse and gradient vanish. In this paper, we firstly propose a general crossover operator, which can be widely applied to GANs using evolutionary strategies. Then we design an evolutionary GAN framework C-GAN based on it. And we combine the crossover operator with evolutionary generative adversarial networks (EGAN) to implement the evolutionary generative adversarial networks with crossover (CE-GAN). Under the premise that a variety of loss functions are used as mutation operators to generate mutation individuals, we evaluate the generated samples and allow the mutation individuals to learn experiences from the output in a knowledge distillation manner, imitating the best output outcome, resulting in better offspring. Then, we greedily selected the best offspring as parents for subsequent training using discriminator as evaluator. Experiments on real datasets demonstrate the effectiveness of CE-GAN and show that our method is competitive in terms of generated images quality and time efficiency.
Proximal Policy Optimization via Enhanced Exploration Efficiency
Nov 11, 2020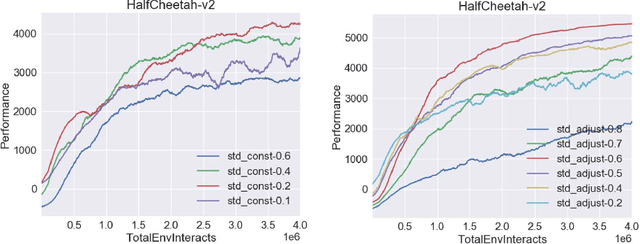

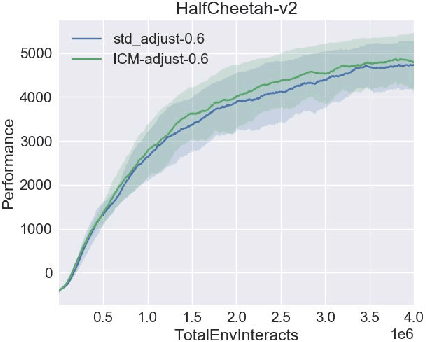
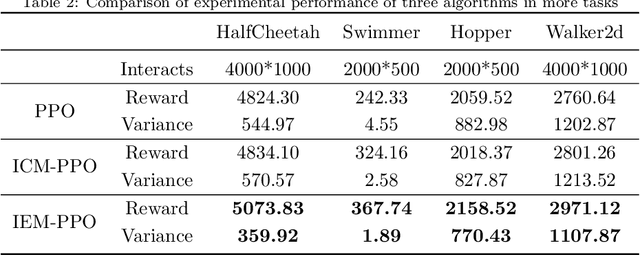
Proximal policy optimization (PPO) algorithm is a deep reinforcement learning algorithm with outstanding performance, especially in continuous control tasks. But the performance of this method is still affected by its exploration ability. For classical reinforcement learning, there are some schemes that make exploration more full and balanced with data exploitation, but they can't be applied in complex environments due to the complexity of algorithm. Based on continuous control tasks with dense reward, this paper analyzes the assumption of the original Gaussian action exploration mechanism in PPO algorithm, and clarifies the influence of exploration ability on performance. Afterward, aiming at the problem of exploration, an exploration enhancement mechanism based on uncertainty estimation is designed in this paper. Then, we apply exploration enhancement theory to PPO algorithm and propose the proximal policy optimization algorithm with intrinsic exploration module (IEM-PPO) which can be used in complex environments. In the experimental parts, we evaluate our method on multiple tasks of MuJoCo physical simulator, and compare IEM-PPO algorithm with curiosity driven exploration algorithm (ICM-PPO) and original algorithm (PPO). The experimental results demonstrate that IEM-PPO algorithm needs longer training time, but performs better in terms of sample efficiency and cumulative reward, and has stability and robustness.
Regularly Updated Deterministic Policy Gradient Algorithm
Jul 01, 2020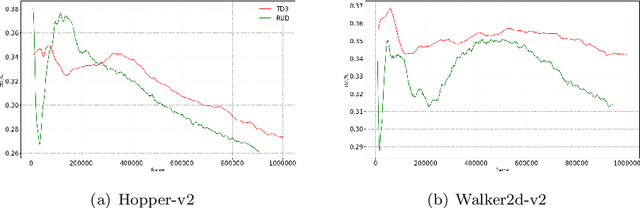
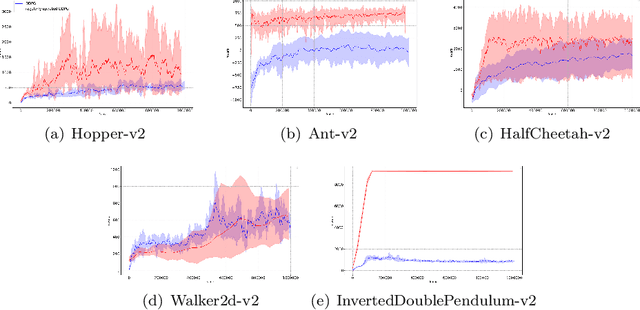
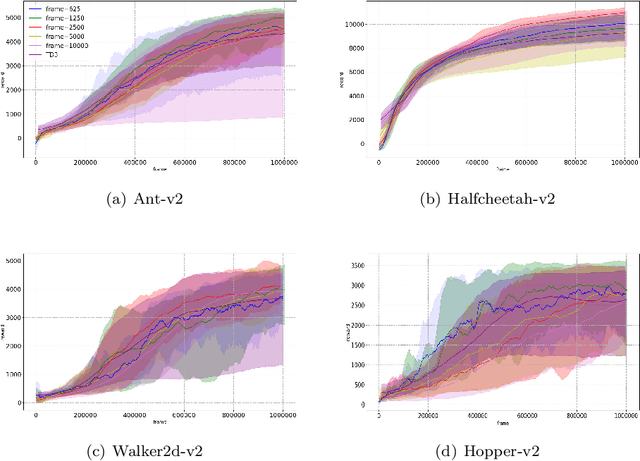
Deep Deterministic Policy Gradient (DDPG) algorithm is one of the most well-known reinforcement learning methods. However, this method is inefficient and unstable in practical applications. On the other hand, the bias and variance of the Q estimation in the target function are sometimes difficult to control. This paper proposes a Regularly Updated Deterministic (RUD) policy gradient algorithm for these problems. This paper theoretically proves that the learning procedure with RUD can make better use of new data in replay buffer than the traditional procedure. In addition, the low variance of the Q value in RUD is more suitable for the current Clipped Double Q-learning strategy. This paper has designed a comparison experiment against previous methods, an ablation experiment with the original DDPG, and other analytical experiments in Mujoco environments. The experimental results demonstrate the effectiveness and superiority of RUD.
NROWAN-DQN: A Stable Noisy Network with Noise Reduction and Online Weight Adjustment for Exploration
Jun 19, 2020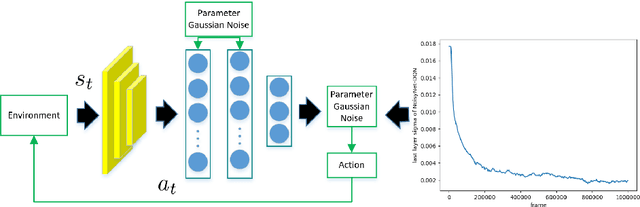
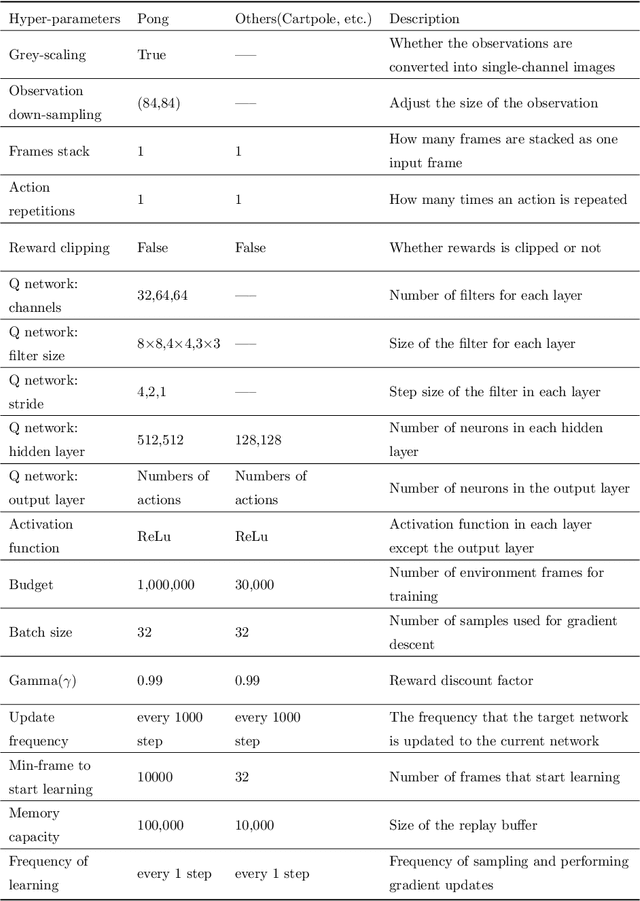
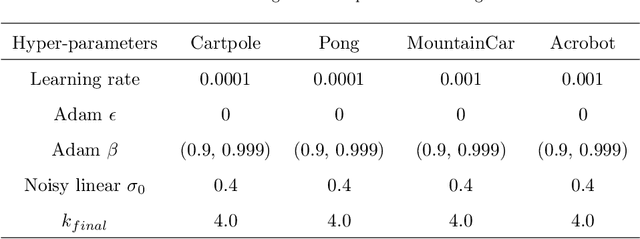
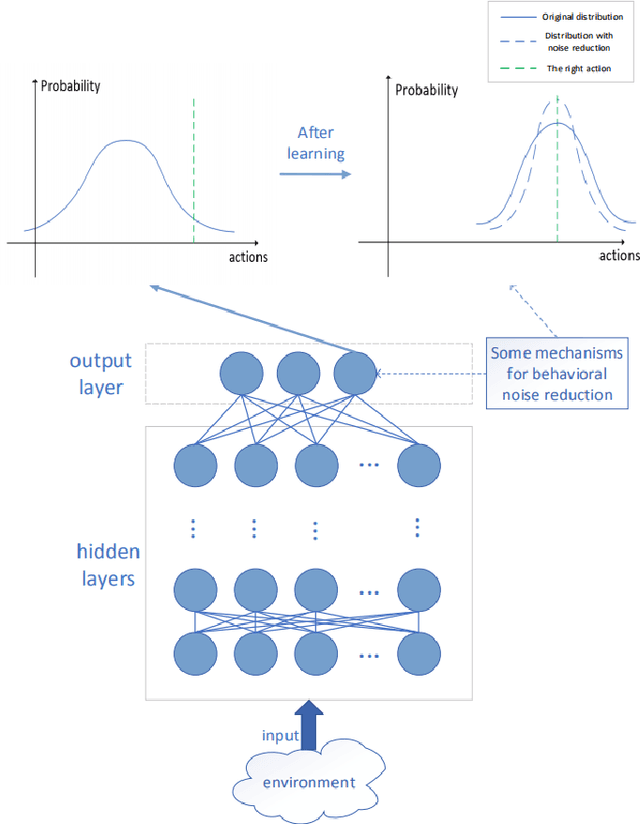
Deep reinforcement learning has been applied more and more widely nowadays, especially in various complex control tasks. Effective exploration for noisy networks is one of the most important issues in deep reinforcement learning. Noisy networks tend to produce stable outputs for agents. However, this tendency is not always enough to find a stable policy for an agent, which decreases efficiency and stability during the learning process. Based on NoisyNets, this paper proposes an algorithm called NROWAN-DQN, i.e., Noise Reduction and Online Weight Adjustment NoisyNet-DQN. Firstly, we develop a novel noise reduction method for NoisyNet-DQN to make the agent perform stable actions. Secondly, we design an online weight adjustment strategy for noise reduction, which improves stable performance and gets higher scores for the agent. Finally, we evaluate this algorithm in four standard domains and analyze properties of hyper-parameters. Our results show that NROWAN-DQN outperforms prior algorithms in all these domains. In addition, NROWAN-DQN also shows better stability. The variance of the NROWAN-DQN score is significantly reduced, especially in some action-sensitive environments. This means that in some environments where high stability is required, NROWAN-DQN will be more appropriate than NoisyNets-DQN.
Recruitment-imitation Mechanism for Evolutionary Reinforcement Learning
Dec 13, 2019
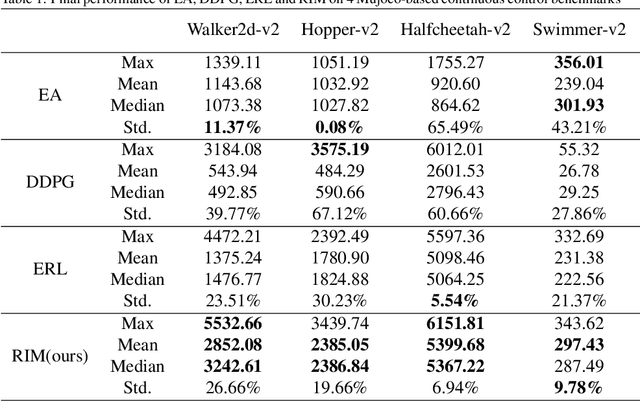

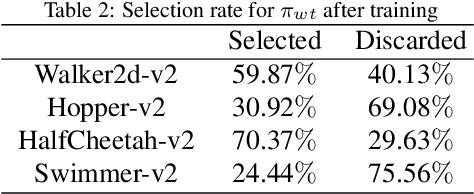
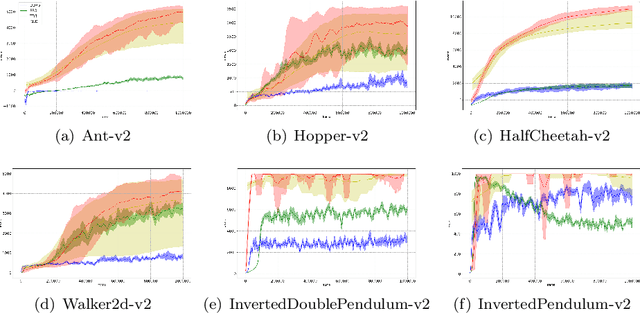
Reinforcement learning, evolutionary algorithms and imitation learning are three principal methods to deal with continuous control tasks. Reinforcement learning is sample efficient, yet sensitive to hyper-parameters setting and needs efficient exploration; Evolutionary algorithms are stable, but with low sample efficiency; Imitation learning is both sample efficient and stable, however it requires the guidance of expert data. In this paper, we propose Recruitment-imitation Mechanism (RIM) for evolutionary reinforcement learning, a scalable framework that combines advantages of the three methods mentioned above. The core of this framework is a dual-actors and single critic reinforcement learning agent. This agent can recruit high-fitness actors from the population of evolutionary algorithms, which instructs itself to learn from experience replay buffer. At the same time, low-fitness actors in the evolutionary population can imitate behavior patterns of the reinforcement learning agent and improve their adaptability. Reinforcement and imitation learners in this framework can be replaced with any off-policy actor-critic reinforcement learner or data-driven imitation learner. We evaluate RIM on a series of benchmarks for continuous control tasks in Mujoco. The experimental results show that RIM outperforms prior evolutionary or reinforcement learning methods. The performance of RIM's components is significantly better than components of previous evolutionary reinforcement learning algorithm, and the recruitment using soft update enables reinforcement learning agent to learn faster than that using hard update.