 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Policy Optimization via Enhanced Exploration Efficiency
Paper and Code
Nov 11, 2020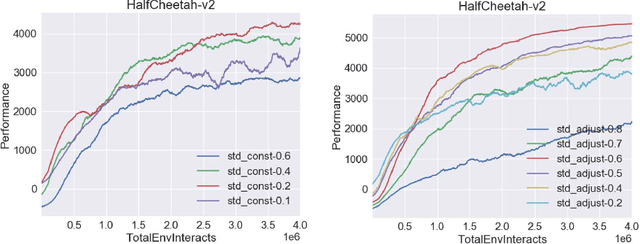

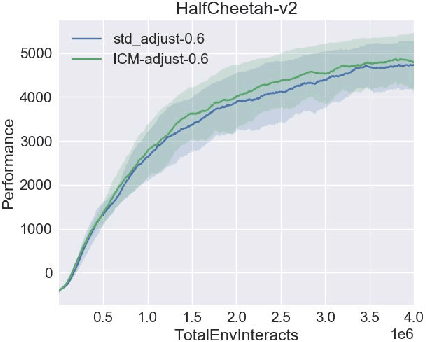
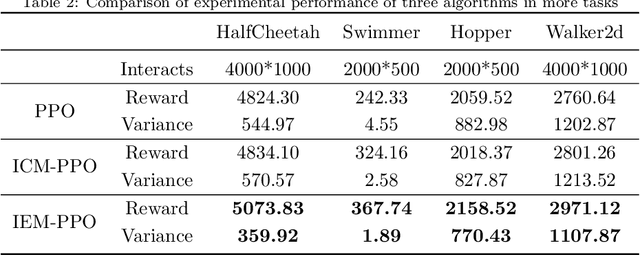
Proximal policy optimization (PPO) algorithm is a deep reinforcement learning algorithm with outstanding performance, especially in continuous control tasks. But the performance of this method is still affected by its exploration ability. For classical reinforcement learning, there are some schemes that make exploration more full and balanced with data exploitation, but they can't be applied in complex environments due to the complexity of algorithm. Based on continuous control tasks with dense reward, this paper analyzes the assumption of the original Gaussian action exploration mechanism in PPO algorithm, and clarifies the influence of exploration ability on performance. Afterward, aiming at the problem of exploration, an exploration enhancement mechanism based on uncertainty estimation is designed in this paper. Then, we apply exploration enhancement theory to PPO algorithm and propose the proximal policy optimization algorithm with intrinsic exploration module (IEM-PPO) which can be used in complex environments. In the experimental parts, we evaluate our method on multiple tasks of MuJoCo physical simulator, and compare IEM-PPO algorithm with curiosity driven exploration algorithm (ICM-PPO) and original algorithm (PPO). The experimental results demonstrate that IEM-PPO algorithm needs longer training time, but performs better in terms of sample efficiency and cumulative reward, and has stability and robustness.