 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaseCal: Unsupervised Confidence Calibration via Base Model Signals
Jan 08, 2026Reliable confidence is essential for trusting the outputs of LLMs, yet widely deployed post-trained LLMs (PoLLMs) typically compromise this trust with severe overconfidence. In contrast, we observe that their corresponding base LLMs often remain well-calibrated. This naturally motivates us to calibrate PoLLM confidence using the base LLM as a reference. This work proposes two ways to achieve this. A straightforward solution, BaseCal-ReEval, evaluates PoLLM's responses by feeding them into the base LLM to get average probabilities as confidence. While effective, this approach introduces additional inference overhead. To address this, we propose BaseCal-Proj, which trains a lightweight projection to map the final-layer hidden states of PoLLMs back to those of their base LLMs. These projected states are then processed by the base LLM's output layer to derive base-calibrated confidence for PoLLM's responses. Notably, BaseCal is an unsupervised, plug-and-play solution that operates without human labels or LLM modifications. Experiments across five datasets and three LLM families demonstrate the effectiveness of BaseCal, reducing Expected Calibration Error (ECE) by an average of 42.90\% compared to the best unsupervised baselines.
Less is More: On the Importance of Data Quality for Unit Test Generation
Feb 20, 2025Unit testing is crucial for software development and maintenance. Effective unit testing ensures and improves software quality, but writing unit tests is time-consuming and labor-intensive. Recent studies have proposed deep learning (DL) techniques or large language models (LLMs) to automate unit test generation. These models are usually trained or fine-tuned on large-scale datasets. Despite growing awareness of the importance of data quality, there has been limited research on the quality of datasets used for test generation. To bridge this gap, we systematically examine the impact of noise on the performance of learning-based test generation models. We first apply the open card sorting method to analyze the most popular and largest test generation dataset, Methods2Test, to categorize eight distinct types of noise. Further, we conduct detailed interviews with 17 domain experts to validate and assess the importance, reasonableness, and correctness of the noise taxonomy. Then, we propose CleanTest, an automated noise-cleaning framework designed to improve the quality of test generation datasets. CleanTest comprises three filters: a rule-based syntax filter, a rule-based relevance filter, and a model-based coverage filter. To evaluate its effectiveness, we apply CleanTest on two widely-used test generation datasets, i.e., Methods2Test and Atlas. Our findings indicate that 43.52% and 29.65% of datasets contain noise, highlighting its prevalence. Finally, we conduct comparative experiments using four LLMs (i.e., CodeBERT, AthenaTest, StarCoder, and CodeLlama7B) to assess the impact of noise on test generation performance. The results show that filtering noise positively influences the test generation ability of the models.
Accelerated Cloud for Artificial Intelligence (ACAI)
Jan 30, 2024Training an effective Machine learning (ML) model is an iterative process that requires effort in multiple dimensions. Vertically, a single pipeline typically includes an initial ETL (Extract, Transform, Load) of raw datasets, a model training stage, and an evaluation stage where the practitioners obtain statistics of the model performance. Horizontally, many such pipelines may be required to find the best model within a search space of model configurations. Many practitioners resort to maintaining logs manually and writing simple glue code to automate the workflow. However, carrying out this process on the cloud is not a trivial task in terms of resource provisioning, data management, and bookkeeping of job histories to make sure the results are reproducible. We propose an end-to-end cloud-based machine learning platform, Accelerated Cloud for AI (ACAI), to help improve the productivity of ML practitioners. ACAI achieves this goal by enabling cloud-based storage of indexed, labeled, and searchable data, as well as automatic resource provisioning, job scheduling, and experiment tracking. Specifically, ACAI provides practitioners (1) a data lake for storing versioned datasets and their corresponding metadata, and (2) an execution engine for executing ML jobs on the cloud with automatic resource provisioning (auto-provision), logging and provenance tracking. To evaluate ACAI, we test the efficacy of our auto-provisioner on the MNIST handwritten digit classification task, and we study the usability of our system using experiments and interviews. We show that our auto-provisioner produces a 1.7x speed-up and 39% cost reduction, and our system reduces experiment time for ML scientists by 20% on typical ML use cases.
PointCA: Evaluating the Robustness of 3D Point Cloud Completion Models Against Adversarial Examples
Dec 01, 2022Point cloud completion, as the upstream procedure of 3D recognition and segmentation, has become an essential part of many tasks such as navigation and scene understanding. While various point cloud completion models have demonstrated their powerful capabilities, their robustness against adversarial attacks, which have been proven to be fatally malicious towards deep neural networks, remains unknown. In addition, existing attack approaches towards point cloud classifiers cannot be applied to the completion models due to different output forms and attack purposes. In order to evaluate the robustness of the completion models, we propose PointCA, the first adversarial attack against 3D point cloud completion models. PointCA can generate adversarial point clouds that maintain high similarity with the original ones, while being completed as another object with totally different semantic information. Specifically, we minimize the representation discrepancy between the adversarial example and the target point set to jointly explore the adversarial point clouds in the geometry space and the feature space. Furthermore, to launch a stealthier attack, we innovatively employ the neighbourhood density information to tailor the perturbation constraint, leading to geometry-aware and distribution-adaptive modifications for each point. Extensive experiments against different premier point cloud completion networks show that PointCA can cause a performance degradation from 77.9% to 16.7%, with the structure chamfer distance kept below 0.01. We conclude that existing completion models are severely vulnerable to adversarial examples, and state-of-the-art defenses for point cloud classification will be partially invalid when applied to incomplete and uneven point cloud data.
Double-Scale Self-Supervised Hypergraph Learning for Group Recommendation
Sep 09, 2021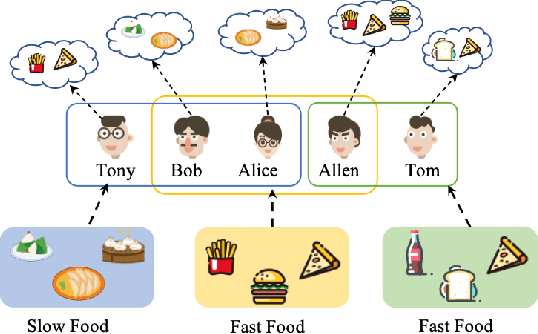
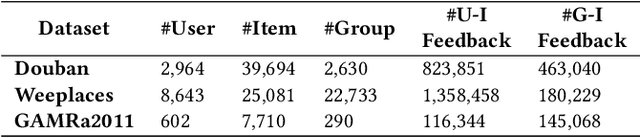
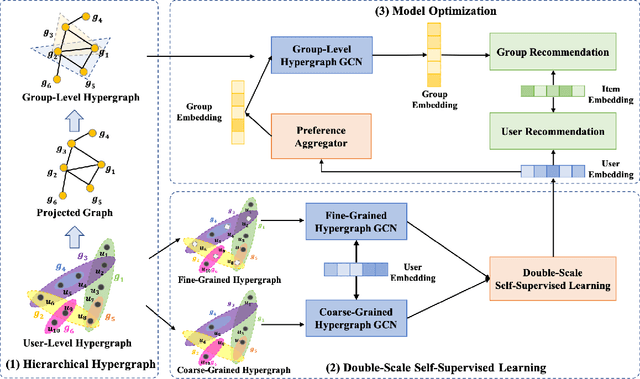
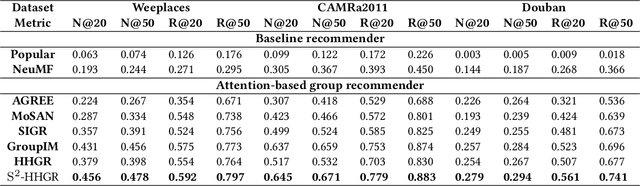
With the prevalence of social media, there has recently been a proliferation of recommenders that shift their focus from individual modeling to group recommendation. Since the group preference is a mixture of various predilections from group members, the fundamental challenge of group recommendation is to model the correlations among members. Existing methods mostly adopt heuristic or attention-based preference aggregation strategies to synthesize group preferences. However, these models mainly focus on the pairwise connections of users and ignore the complex high-order interactions within and beyond groups. Besides, group recommendation suffers seriously from the problem of data sparsity due to severely sparse group-item interactions. In this paper, we propose a self-supervised hypergraph learning framework for group recommendation to achieve two goals: (1) capturing the intra- and inter-group interactions among users; (2) alleviating the data sparsity issue with the raw data itself. Technically, for (1), a hierarchical hypergraph convolutional network based on the user- and group-level hypergraphs is developed to model the complex tuplewise correlations among users within and beyond groups. For (2), we design a double-scale node dropout strategy to create self-supervision signals that can regularize user representations with different granularities against the sparsity issue. The experimental analysis on multiple benchmark datasets demonstrates the superiority of the proposed model and also elucidates the rationality of the hypergraph modeling and the double-scale self-supervision.
Evolutionary Generative Adversarial Networks with Crossover Based Knowledge Distillation
Jan 27, 2021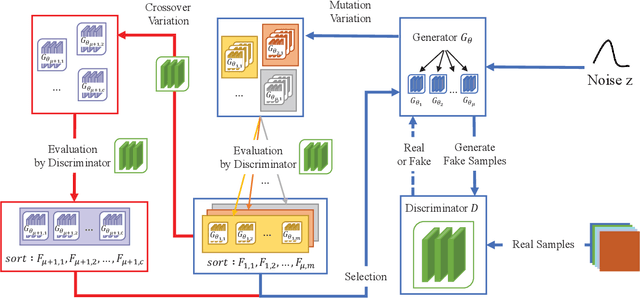

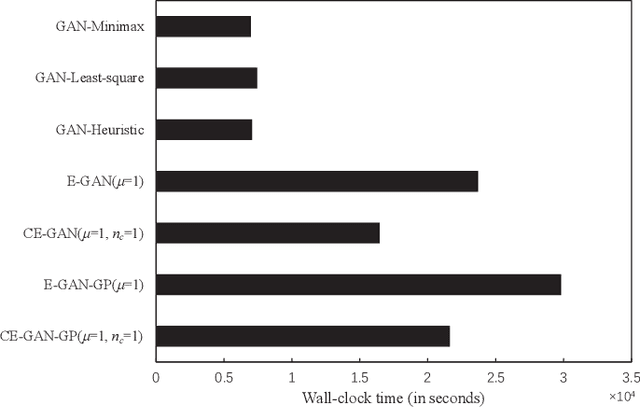
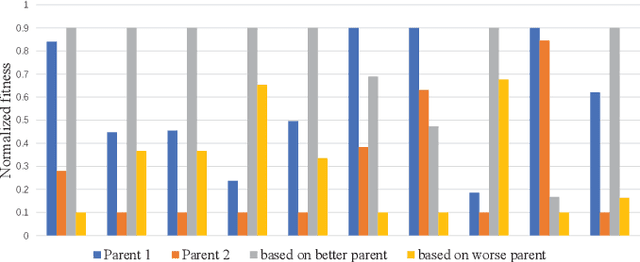
Generative Adversarial Networks (GAN) is an adversarial model, and it has been demonstrated to be effective for various generative tasks. However, GAN and its variants also suffer from many training problems, such as mode collapse and gradient vanish. In this paper, we firstly propose a general crossover operator, which can be widely applied to GANs using evolutionary strategies. Then we design an evolutionary GAN framework C-GAN based on it. And we combine the crossover operator with evolutionary generative adversarial networks (EGAN) to implement the evolutionary generative adversarial networks with crossover (CE-GAN). Under the premise that a variety of loss functions are used as mutation operators to generate mutation individuals, we evaluate the generated samples and allow the mutation individuals to learn experiences from the output in a knowledge distillation manner, imitating the best output outcome, resulting in better offspring. Then, we greedily selected the best offspring as parents for subsequent training using discriminator as evaluator. Experiments on real datasets demonstrate the effectiveness of CE-GAN and show that our method is competitive in terms of generated images quality and time efficiency.
Proximal Policy Optimization via Enhanced Exploration Efficiency
Nov 11, 2020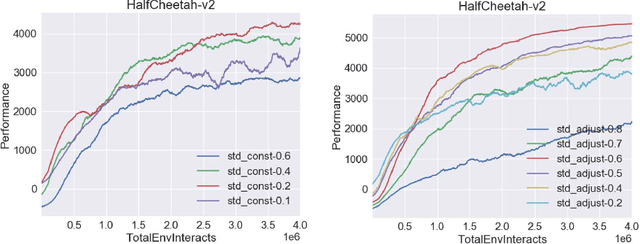

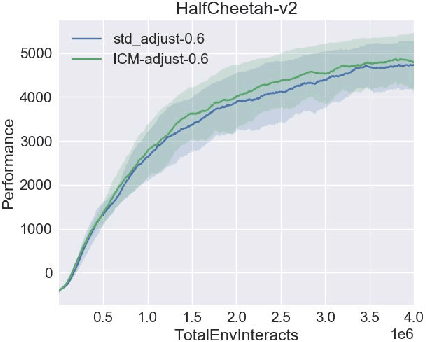
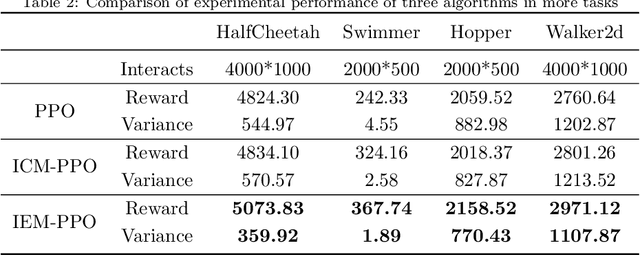
Proximal policy optimization (PPO) algorithm is a deep reinforcement learning algorithm with outstanding performance, especially in continuous control tasks. But the performance of this method is still affected by its exploration ability. For classical reinforcement learning, there are some schemes that make exploration more full and balanced with data exploitation, but they can't be applied in complex environments due to the complexity of algorithm. Based on continuous control tasks with dense reward, this paper analyzes the assumption of the original Gaussian action exploration mechanism in PPO algorithm, and clarifies the influence of exploration ability on performance. Afterward, aiming at the problem of exploration, an exploration enhancement mechanism based on uncertainty estimation is designed in this paper. Then, we apply exploration enhancement theory to PPO algorithm and propose the proximal policy optimization algorithm with intrinsic exploration module (IEM-PPO) which can be used in complex environments. In the experimental parts, we evaluate our method on multiple tasks of MuJoCo physical simulator, and compare IEM-PPO algorithm with curiosity driven exploration algorithm (ICM-PPO) and original algorithm (PPO). The experimental results demonstrate that IEM-PPO algorithm needs longer training time, but performs better in terms of sample efficiency and cumulative reward, and has stability and robustness.
Recommender Systems Based on Generative Adversarial Networks: A Problem-Driven Perspective
Mar 05, 2020

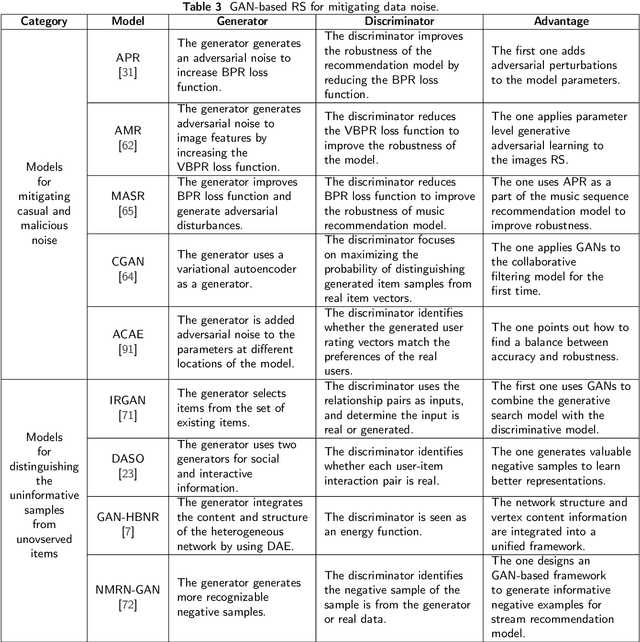

Recommender systems (RS) play a very important role in various aspects of people's online life. Many companies leverage RS to help users discover new and favored items. Despite their empirical success, these systems still suffer from two main problems: data noise and data sparsity. In recent years, Generative Adversarial Networks (GANs) have received a surge of interests in many fields because of their great potential to learn complex real data distribution, and they also provide new means to mitigate the aforementioned problems of RS. Particularly, owing to adversarial learning, the problem of data noise can be handled by adding adversarial perturbations or forcing discriminators to tell the informative and uninformative data examples apart. As for the mitigation of data sparsity issue, the GAN-based models are able to replicate the real distribution of the user-item interactions and augment the available data. To gain a comprehensive understanding of these GAN-based recommendation models, we provide a retrospective of these studies and organize them from a problem-driven perspective. Specifically, we propose a taxonomy of these models, along with a detailed description of them and their advantages. Finally, we elaborate on several open issues and expand on current trends in the GAN-based RS.
Recruitment-imitation Mechanism for Evolutionary Reinforcement Learning
Dec 13, 2019
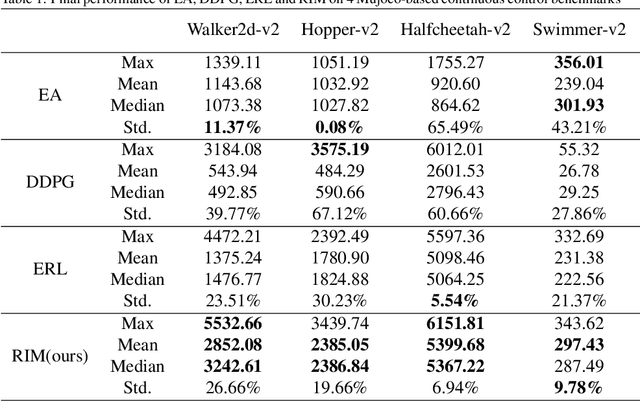

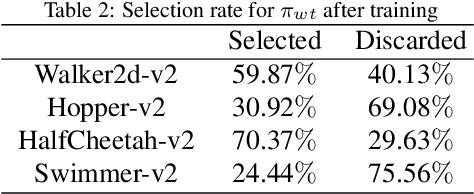
Reinforcement learning, evolutionary algorithms and imitation learning are three principal methods to deal with continuous control tasks. Reinforcement learning is sample efficient, yet sensitive to hyper-parameters setting and needs efficient exploration; Evolutionary algorithms are stable, but with low sample efficiency; Imitation learning is both sample efficient and stable, however it requires the guidance of expert data. In this paper, we propose Recruitment-imitation Mechanism (RIM) for evolutionary reinforcement learning, a scalable framework that combines advantages of the three methods mentioned above. The core of this framework is a dual-actors and single critic reinforcement learning agent. This agent can recruit high-fitness actors from the population of evolutionary algorithms, which instructs itself to learn from experience replay buffer. At the same time, low-fitness actors in the evolutionary population can imitate behavior patterns of the reinforcement learning agent and improve their adaptability. Reinforcement and imitation learners in this framework can be replaced with any off-policy actor-critic reinforcement learner or data-driven imitation learner. We evaluate RIM on a series of benchmarks for continuous control tasks in Mujoco. The experimental results show that RIM outperforms prior evolutionary or reinforcement learning methods. The performance of RIM's components is significantly better than components of previous evolutionary reinforcement learning algorithm, and the recruitment using soft update enables reinforcement learning agent to learn faster than that using hard update.
ScenarioSA: A Large Scale Conversational Database for Interactive Sentiment Analysis
Jul 12, 2019
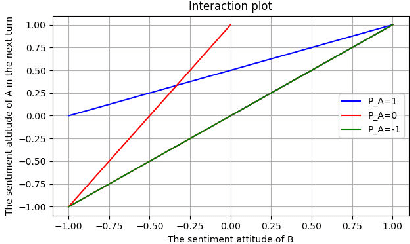

Interactive sentiment analysis is an emerging, yet challenging, subtask of the sentiment analysis problem. It aims to discover the affective state and sentimental change of each person in a conversation. Existing sentiment analysis approaches are insufficient in modelling the interactions among people. However, the development of new approaches are critically limited by the lack of labelled interactive sentiment datasets. In this paper, we present a new conversational emotion database that we have created and made publically available, namely ScenarioSA. We manually label 2,214 multi-turn English conversations collected from natural contexts. In comparison with existing sentiment datasets, ScenarioSA (1) covers a wide range of scenarios; (2) describes the interactions between two speakers; and (3) reflects the sentimental evolution of each speaker over the course of a conversation. Finally, we evaluate various state-of-the-art algorithms on ScenarioSA, demonstrating the need of novel interactive sentiment analysis models and the potential of ScenarioSA to facilitate the development of such models.