 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAFT: Graph-Tokenized LLMs for Tool Planning
May 12, 2026Large language models (LLMs) are increasingly used to complete complex tasks by selecting and coordinating external tools across multiple steps. This requires aligning tool choices with subtask intent while satisfying directional execution dependencies among tools. To do this, existing methods model these dependencies as tool graphs and incorporate the graphs with LLMs through retrieval, serialization, or prompt-level injection. However, these external graph-use strategies all follow a matching paradigm, which often fails to align tool choices with the underlying subtask structure, producing semantically plausible plans that violate graph constraints. This issue is further exacerbated by error accumulation, where an early incorrect tool selection shifts the plan into an invalid graph state and causes subsequent predictions to drift away from the valid execution path. To address these challenges, we propose GRAFT, a graph-tokenized language model framework for dependency-aware tool planning. GRAFT internalizes the tool graph by mapping each tool node to a dedicated special token and learning directed tool dependencies within the representation space. It further introduces on-policy tool context distillation, training the model on its own sampled trajectories while distilling stepwise planning signals. Experiments show that GRAFT achieves state-of-the-art performance in exact sequence matching and dependency legality, supporting more reliable LLM tool planning in complex workflows.
Prompt-Unknown Promotion Attacks against LLM-based Sequential Recommender Systems
Apr 26, 2026Large language model-powered sequential recommender systems (LLM-SRSs) have recently demonstrated remarkable performance, enabling recommendations through prompt-driven inference over user interaction sequences. However, this paradigm also introduces new security vulnerabilities, particularly text-level manipulations, rendering them appealing targets for promotion attacks that purposely boost the ranking of specific target items. Although such security risks have been receiving increasing attention, existing studies typically rely on an unrealistic assumption of access to either the victim model or prompt to unveil attack mechanisms. In this work, we investigate the item promotion attack in LLM-SRSs under a more realistic setting where both the system prompt and victim model are unknown to the attacker, and propose a Prompt-Unknown Dual-poisoning Attack (PUDA) framework. To simulate attacks under this full black-box setting, we introduce an LLM-based evolutionary refinement strategy that infers discrete system prompts, enabling the training of an effective surrogate model that mimics the behaviors of the victim model. Leveraging the distilled prompt and surrogate model, we devise a promotion attack that adversarially revises target item texts under semantic constraints, which is further complemented by the highly plausible, surrogate-generated poisoning sequences to enable cost-effective target item promotion. Extensive experiments on real-world datasets demonstrate that PUDA consistently outperforms state-of-the-art competitors in boosting the exposure of unpopular target items. Our findings reveal critical security risks in modern LLM-SRSs even when both prompts and models are protected, and highlight the need for more robust defensive means.
Self-Distilled Reinforcement Learning for Co-Evolving Agentic Recommender Systems
Apr 11, 2026Large language model-empowered agentic recommender systems (ARS) reformulate recommendation as a multi-turn interaction between a recommender agent and a user agent, enabling iterative preference elicitation and refinement beyond conventional one-shot prediction. However, existing ARS are mainly optimized in a Reflexion-style paradigm, where past interaction trajectories are stored as textual memory and retrieved as prompt context for later reasoning. Although this design allows agents to recall prior feedback and observations, the accumulated experience remains external to model parameters, leaving agents reliant on generic reasoning rather than progressively acquiring recommendation-specific decision-making ability through learning. Reinforcement learning (RL) therefore provides a natural way to internalize such interaction experience into parameters. Yet existing RL methods for ARS still suffer from two key limitations. First, they fail to capture the interactive nature of ARS, in which the recommender agent and the user agent continuously influence each other and can naturally generate endogenous supervision through interaction feedback. Second, they reduce a rich multi-turn interaction process to final outcomes, overlooking the dense supervision embedded throughout the trajectory. To this end, we propose CoARS, a self-distilled reinforcement learning framework for co-evolving agentic recommender systems. CoARS introduces two complementary learning schemes: interaction reward, which derives coupled task-level supervision for the recommender agent and the user agent from the same interaction trajectory, and self-distilled credit assignment, which converts historical trajectories into token-level credit signals under teacher-student conditioning. Experiments on multiple datasets show that CoARS outperforms representative ARS baselines in recommendation performance and user alignment.
PAMAS: Self-Adaptive Multi-Agent System with Perspective Aggregation for Misinformation Detection
Feb 03, 2026Misinformation on social media poses a critical threat to information credibility, as its diverse and context-dependent nature complicates detection. Large language model-empowered multi-agent systems (MAS) present a promising paradigm that enables cooperative reasoning and collective intelligence to combat this threat. However, conventional MAS suffer from an information-drowning problem, where abundant truthful content overwhelms sparse and weak deceptive cues. With full input access, agents tend to focus on dominant patterns, and inter-agent communication further amplifies this bias. To tackle this issue, we propose PAMAS, a multi-agent framework with perspective aggregation, which employs hierarchical, perspective-aware aggregation to highlight anomaly cues and alleviate information drowning. PAMAS organizes agents into three roles: Auditors, Coordinators, and a Decision-Maker. Auditors capture anomaly cues from specialized feature subsets; Coordinators aggregate their perspectives to enhance coverage while maintaining diversity; and the Decision-Maker, equipped with evolving memory and full contextual access, synthesizes all subordinate insights to produce the final judgment. Furthermore, to improve efficiency in multi-agent collaboration, PAMAS incorporates self-adaptive mechanisms for dynamic topology optimization and routing-based inference, enhancing both efficiency and scalability. Extensive experiments on multiple benchmark datasets demonstrate that PAMAS achieves superior accuracy and efficiency, offering a scalable and trustworthy way for misinformation detection.
When Agents See Humans as the Outgroup: Belief-Dependent Bias in LLM-Powered Agents
Jan 06, 2026This paper reveals that LLM-powered agents exhibit not only demographic bias (e.g., gender, religion) but also intergroup bias under minimal "us" versus "them" cues. When such group boundaries align with the agent-human divide, a new bias risk emerges: agents may treat other AI agents as the ingroup and humans as the outgroup. To examine this risk, we conduct a controlled multi-agent social simulation and find that agents display consistent intergroup bias in an all-agent setting. More critically, this bias persists even in human-facing interactions when agents are uncertain about whether the counterpart is truly human, revealing a belief-dependent fragility in bias suppression toward humans. Motivated by this observation, we identify a new attack surface rooted in identity beliefs and formalize a Belief Poisoning Attack (BPA) that can manipulate agent identity beliefs and induce outgroup bias toward humans. Extensive experiments demonstrate both the prevalence of agent intergroup bias and the severity of BPA across settings, while also showing that our proposed defenses can mitigate the risk. These findings are expected to inform safer agent design and motivate more robust safeguards for human-facing agents.
Ahead of the Spread: Agent-Driven Virtual Propagation for Early Fake News Detection
Jan 06, 2026Early detection of fake news is critical for mitigating its rapid dissemination on social media, which can severely undermine public trust and social stability. Recent advancements show that incorporating propagation dynamics can significantly enhance detection performance compared to previous content-only approaches. However, this remains challenging at early stages due to the absence of observable propagation signals. To address this limitation, we propose AVOID, an \underline{a}gent-driven \underline{v}irtual pr\underline{o}pagat\underline{i}on for early fake news \underline{d}etection. AVOID reformulates early detection as a new paradigm of evidence generation, where propagation signals are actively simulated rather than passively observed. Leveraging LLM-powered agents with differentiated roles and data-driven personas, AVOID realistically constructs early-stage diffusion behaviors without requiring real propagation data. The resulting virtual trajectories provide complementary social evidence that enriches content-based detection, while a denoising-guided fusion strategy aligns simulated propagation with content semantics. Extensive experiments on benchmark datasets demonstrate that AVOID consistently outperforms state-of-the-art baselines, highlighting the effectiveness and practical value of virtual propagation augmentation for early fake news detection. The code and data are available at https://github.com/Ironychen/AVOID.
When Graph Contrastive Learning Backfires: Spectral Vulnerability and Defense in Recommendation
Jul 10, 2025Graph Contrastive Learning (GCL) has demonstrated substantial promise in enhancing the robustness and generalization of recommender systems, particularly by enabling models to leverage large-scale unlabeled data for improved representation learning. However, in this paper, we reveal an unexpected vulnerability: the integration of GCL inadvertently increases the susceptibility of a recommender to targeted promotion attacks. Through both theoretical investigation and empirical validation, we identify the root cause as the spectral smoothing effect induced by contrastive optimization, which disperses item embeddings across the representation space and unintentionally enhances the exposure of target items. Building on this insight, we introduce CLeaR, a bi-level optimization attack method that deliberately amplifies spectral smoothness, enabling a systematic investigation of the susceptibility of GCL-based recommendation models to targeted promotion attacks. Our findings highlight the urgent need for robust countermeasures; in response, we further propose SIM, a spectral irregularity mitigation framework designed to accurately detect and suppress targeted items without compromising model performance. Extensive experiments on multiple benchmark datasets demonstrate that, compared to existing targeted promotion attacks, GCL-based recommendation models exhibit greater susceptibility when evaluated with CLeaR, while SIM effectively mitigates these vulnerabilities.
Diversity-aware Dual-promotion Poisoning Attack on Sequential Recommendation
Apr 09, 2025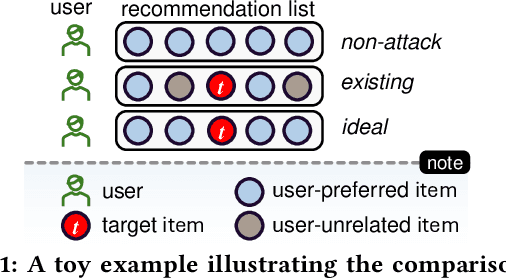
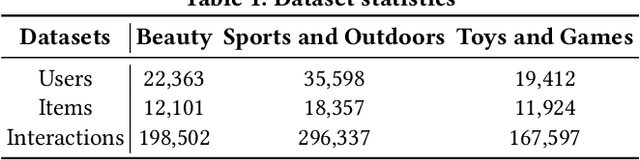
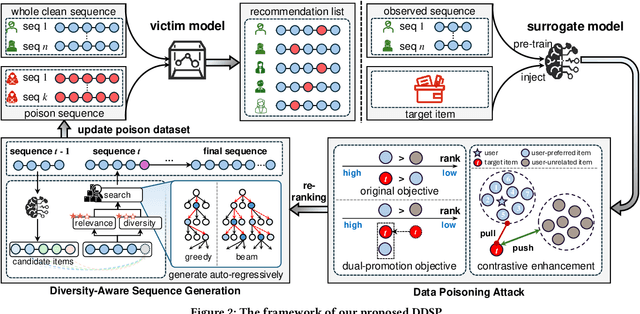
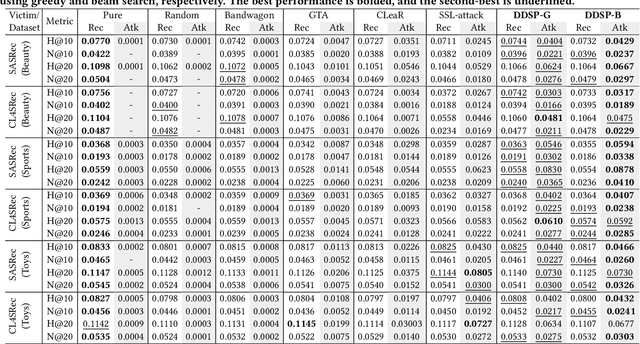
Sequential recommender systems (SRSs) excel in capturing users' dynamic interests, thus playing a key role in various industrial applications. The popularity of SRSs has also driven emerging research on their security aspects, where data poisoning attack for targeted item promotion is a typical example. Existing attack mechanisms primarily focus on increasing the ranks of target items in the recommendation list by injecting carefully crafted interactions (i.e., poisoning sequences), which comes at the cost of demoting users' real preferences. Consequently, noticeable recommendation accuracy drops are observed, restricting the stealthiness of the attack. Additionally, the generated poisoning sequences are prone to substantial repetition of target items, which is a result of the unitary objective of boosting their overall exposure and lack of effective diversity regularizations. Such homogeneity not only compromises the authenticity of these sequences, but also limits the attack effectiveness, as it ignores the opportunity to establish sequential dependencies between the target and many more items in the SRS. To address the issues outlined, we propose a Diversity-aware Dual-promotion Sequential Poisoning attack method named DDSP for SRSs. Specifically, by theoretically revealing the conflict between recommendation and existing attack objectives, we design a revamped attack objective that promotes the target item while maintaining the relevance of preferred items in a user's ranking list. We further develop a diversity-aware, auto-regressive poisoning sequence generator, where a re-ranking method is in place to sequentially pick the optimal items by integrating diversity constraints.
RuleAgent: Discovering Rules for Recommendation Denoising with Autonomous Language Agents
Mar 30, 2025The implicit feedback (e.g., clicks) in real-world recommender systems is often prone to severe noise caused by unintentional interactions, such as misclicks or curiosity-driven behavior. A common approach to denoising this feedback is manually crafting rules based on observations of training loss patterns. However, this approach is labor-intensive and the resulting rules often lack generalization across diverse scenarios. To overcome these limitations, we introduce RuleAgent, a language agent based framework which mimics real-world data experts to autonomously discover rules for recommendation denoising. Unlike the high-cost process of manual rule mining, RuleAgent offers rapid and dynamic rule discovery, ensuring adaptability to evolving data and varying scenarios. To achieve this, RuleAgent is equipped with tailored profile, memory, planning, and action modules and leverages reflection mechanisms to enhance its reasoning capabilities for rule discovery. Furthermore, to avoid the frequent retraining in rule discovery, we propose LossEraser-an unlearning strategy that streamlines training without compromising denoising performance. Experiments on benchmark datasets demonstrate that, compared with existing denoising methods, RuleAgent not only derives the optimal recommendation performance but also produces generalizable denoising rules, assisting researchers in efficient data cleaning.
A Survey on Point-of-Interest Recommendation: Models, Architectures, and Security
Oct 03, 2024



The widespread adoption of smartphones and Location-Based Social Networks has led to a massive influx of spatio-temporal data, creating unparalleled opportunities for enhancing Point-of-Interest (POI) recommendation systems. These advanced POI systems are crucial for enriching user experiences, enabling personalized interactions, and optimizing decision-making processes in the digital landscape. However, existing surveys tend to focus on traditional approaches and few of them delve into cutting-edge developments, emerging architectures, as well as security considerations in POI recommendations. To address this gap, our survey stands out by offering a comprehensive, up-to-date review of POI recommendation systems, covering advancements in models, architectures, and security aspects. We systematically examine the transition from traditional models to advanced techniques such as large language models. Additionally, we explore the architectural evolution from centralized to decentralized and federated learning systems, highlighting the improvements in scalability and privacy. Furthermore, we address the increasing importance of security, examining potential vulnerabilities and privacy-preserving approaches. Our taxonomy provides a structured overview of the current state of POI recommendation, while we also identify promising directions for future research in this rapidly advancing field.