 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distilled Reinforcement Learning for Co-Evolving Agentic Recommender Systems
Apr 11, 2026Large language model-empowered agentic recommender systems (ARS) reformulate recommendation as a multi-turn interaction between a recommender agent and a user agent, enabling iterative preference elicitation and refinement beyond conventional one-shot prediction. However, existing ARS are mainly optimized in a Reflexion-style paradigm, where past interaction trajectories are stored as textual memory and retrieved as prompt context for later reasoning. Although this design allows agents to recall prior feedback and observations, the accumulated experience remains external to model parameters, leaving agents reliant on generic reasoning rather than progressively acquiring recommendation-specific decision-making ability through learning. Reinforcement learning (RL) therefore provides a natural way to internalize such interaction experience into parameters. Yet existing RL methods for ARS still suffer from two key limitations. First, they fail to capture the interactive nature of ARS, in which the recommender agent and the user agent continuously influence each other and can naturally generate endogenous supervision through interaction feedback. Second, they reduce a rich multi-turn interaction process to final outcomes, overlooking the dense supervision embedded throughout the trajectory. To this end, we propose CoARS, a self-distilled reinforcement learning framework for co-evolving agentic recommender systems. CoARS introduces two complementary learning schemes: interaction reward, which derives coupled task-level supervision for the recommender agent and the user agent from the same interaction trajectory, and self-distilled credit assignment, which converts historical trajectories into token-level credit signals under teacher-student conditioning. Experiments on multiple datasets show that CoARS outperforms representative ARS baselines in recommendation performance and user alignment.
Generative Recall, Dense Reranking: Learning Multi-View Semantic IDs for Efficient Text-to-Video Retrieval
Jan 29, 2026Text-to-Video Retrieval (TVR) is essential in video platforms. Dense retrieval with dual-modality encoders leads in accuracy, but its computation and storage scale poorly with corpus size. Thus, real-time large-scale applications adopt two-stage retrieval, where a fast recall model gathers a small candidate pool, which is reranked by an advanced dense retriever. Due to hugely reduced candidates, the reranking model can use any off-the-shelf dense retriever without hurting efficiency, meaning the recall model bounds two-stage TVR performance. Recently, generative retrieval (GR) replaces dense video embeddings with discrete semantic IDs and retrieves by decoding text queries into ID tokens. GR offers near-constant inference and storage complexity, and its semantic IDs capture high-level video features via quantization, making it ideal for quickly eliminating irrelevant candidates during recall. However, as a recall model in two-stage TVR, GR suffers from (i) semantic ambiguity, where each video satisfies diverse queries but is forced into one semantic ID; and (ii) cross-modal misalignment, as semantic IDs are solely derived from visual features without text supervision. We propose Generative Recall and Dense Reranking (GRDR), designing a novel GR method to uplift recalled candidate quality. GRDR assigns multiple semantic IDs to each video using a query-guided multi-view tokenizer exposing diverse semantic access paths, and jointly trains the tokenizer and generative retriever via a shared codebook to cast semantic IDs as the semantic bridge between texts and videos. At inference, trie-constrained decoding generates a compact candidate set reranked by a dense model for fine-grained matching. Experiments on TVR benchmarks show GRDR matches strong dense retrievers in accuracy while reducing index storage by an order of magnitude and accelerating up to 300$\times$ in full-corpus retrieval.
When Graph Contrastive Learning Backfires: Spectral Vulnerability and Defense in Recommendation
Jul 10, 2025Graph Contrastive Learning (GCL) has demonstrated substantial promise in enhancing the robustness and generalization of recommender systems, particularly by enabling models to leverage large-scale unlabeled data for improved representation learning. However, in this paper, we reveal an unexpected vulnerability: the integration of GCL inadvertently increases the susceptibility of a recommender to targeted promotion attacks. Through both theoretical investigation and empirical validation, we identify the root cause as the spectral smoothing effect induced by contrastive optimization, which disperses item embeddings across the representation space and unintentionally enhances the exposure of target items. Building on this insight, we introduce CLeaR, a bi-level optimization attack method that deliberately amplifies spectral smoothness, enabling a systematic investigation of the susceptibility of GCL-based recommendation models to targeted promotion attacks. Our findings highlight the urgent need for robust countermeasures; in response, we further propose SIM, a spectral irregularity mitigation framework designed to accurately detect and suppress targeted items without compromising model performance. Extensive experiments on multiple benchmark datasets demonstrate that, compared to existing targeted promotion attacks, GCL-based recommendation models exhibit greater susceptibility when evaluated with CLeaR, while SIM effectively mitigates these vulnerabilities.
Are Synthetic Videos Useful? A Benchmark for Retrieval-Centric Evaluation of Synthetic Videos
Jul 03, 2025Text-to-video (T2V) synthesis has advanced rapidly, yet current evaluation metrics primarily capture visual quality and temporal consistency, offering limited insight into how synthetic videos perform in downstream tasks such as text-to-video retrieval (TVR). In this work, we introduce SynTVA, a new dataset and benchmark designed to evaluate the utility of synthetic videos for building retrieval models. Based on 800 diverse user queries derived from MSRVTT training split, we generate synthetic videos using state-of-the-art T2V models and annotate each video-text pair along four key semantic alignment dimensions: Object \& Scene, Action, Attribute, and Prompt Fidelity. Our evaluation framework correlates general video quality assessment (VQA) metrics with these alignment scores, and examines their predictive power for downstream TVR performance. To explore pathways of scaling up, we further develop an Auto-Evaluator to estimate alignment quality from existing metrics. Beyond benchmarking, our results show that SynTVA is a valuable asset for dataset augmentation, enabling the selection of high-utility synthetic samples that measurably improve TVR outcomes. Project page and dataset can be found at https://jasoncodemaker.github.io/SynTVA/.
How Do Experts Make Sense of Integrated Process Models?
May 28, 2025A range of integrated modeling approaches have been developed to enable a holistic representation of business process logic together with all relevant business rules. These approaches address inherent problems with separate documentation of business process models and business rules. In this study, we explore how expert process workers make sense of the information provided through such integrated modeling approaches. To do so, we complement verbal protocol analysis with eye-tracking metrics to reveal nuanced user behaviours involved in the main phases of sensemaking, namely information foraging and information processing. By studying expert process workers engaged in tasks based on integrated modeling of business processes and rules, we provide insights that pave the way for a better understanding of sensemaking practices and improved development of business process and business rule integration approaches. Our research underscores the importance of offering personalized support mechanisms that increase the efficacy and efficiency of sensemaking practices for process knowledge workers.
Enhancing Treatment Effect Estimation via Active Learning: A Counterfactual Covering Perspective
May 08, 2025Although numerous complex algorithms for treatment effect estimation have been developed in recent years, their effectiveness remains limited when handling insufficiently labeled training sets due to the high cost of labeling the effect after treatment, e.g., expensive tumor imaging or biopsy procedures needed to evaluate treatment effects. Therefore, it becomes essential to actively incorporate more high-quality labeled data, all while adhering to a constrained labeling budget. To enable data-efficient treatment effect estimation, we formalize the problem through rigorous theoretical analysis within the active learning context, where the derived key measures -- \textit{factual} and \textit{counterfactual covering radius} determine the risk upper bound. To reduce the bound, we propose a greedy radius reduction algorithm, which excels under an idealized, balanced data distribution. To generalize to more realistic data distributions, we further propose FCCM, which transforms the optimization objective into the \textit{Factual} and \textit{Counterfactual Coverage Maximization} to ensure effective radius reduction during data acquisition. Furthermore, benchmarking FCCM against other baselines demonstrates its superiority across both fully synthetic and semi-synthetic datasets.
LLM-based Semantic Augmentation for Harmful Content Detection
Apr 22, 2025



Recent advances in large language models (LLMs) have demonstrated strong performance on simple text classification tasks, frequently under zero-shot settings. However, their efficacy declines when tackling complex social media challenges such as propaganda detection, hateful meme classification, and toxicity identification. Much of the existing work has focused on using LLMs to generate synthetic training data, overlooking the potential of LLM-based text preprocessing and semantic augmentation. In this paper, we introduce an approach that prompts LLMs to clean noisy text and provide context-rich explanations, thereby enhancing training sets without substantial increases in data volume. We systematically evaluate on the SemEval 2024 multi-label Persuasive Meme dataset and further validate on the Google Jigsaw toxic comments and Facebook hateful memes datasets to assess generalizability. Our results reveal that zero-shot LLM classification underperforms on these high-context tasks compared to supervised models. In contrast, integrating LLM-based semantic augmentation yields performance on par with approaches that rely on human-annotated data, at a fraction of the cost. These findings underscore the importance of strategically incorporating LLMs into machine learning (ML) pipeline for social media classification tasks, offering broad implications for combating harmful content online.
RuleAgent: Discovering Rules for Recommendation Denoising with Autonomous Language Agents
Mar 30, 2025The implicit feedback (e.g., clicks) in real-world recommender systems is often prone to severe noise caused by unintentional interactions, such as misclicks or curiosity-driven behavior. A common approach to denoising this feedback is manually crafting rules based on observations of training loss patterns. However, this approach is labor-intensive and the resulting rules often lack generalization across diverse scenarios. To overcome these limitations, we introduce RuleAgent, a language agent based framework which mimics real-world data experts to autonomously discover rules for recommendation denoising. Unlike the high-cost process of manual rule mining, RuleAgent offers rapid and dynamic rule discovery, ensuring adaptability to evolving data and varying scenarios. To achieve this, RuleAgent is equipped with tailored profile, memory, planning, and action modules and leverages reflection mechanisms to enhance its reasoning capabilities for rule discovery. Furthermore, to avoid the frequent retraining in rule discovery, we propose LossEraser-an unlearning strategy that streamlines training without compromising denoising performance. Experiments on benchmark datasets demonstrate that, compared with existing denoising methods, RuleAgent not only derives the optimal recommendation performance but also produces generalizable denoising rules, assisting researchers in efficient data cleaning.
Spotting Persuasion: A Low-cost Model for Persuasion Detection in Political Ads on Social Media
Mar 18, 2025



In the realm of political advertising, persuasion operates as a pivotal element within the broader framework of propaganda, exerting profound influences on public opinion and electoral outcomes. In this paper, we (1) introduce a lightweight model for persuasive text detection that achieves state-of-the-art performance in Subtask 3 of SemEval 2023 Task 3, while significantly reducing the computational resource requirements; and (2) leverage the proposed model to gain insights into political campaigning strategies on social media platforms by applying it to a real-world dataset we curated, consisting of Facebook political ads from the 2022 Australian Federal election campaign. Our study shows how subtleties can be found in persuasive political advertisements and presents a pragmatic approach to detect and analyze such strategies with limited resources, enhancing transparency in social media political campaigns.
StableFusion: Continual Video Retrieval via Frame Adaptation
Mar 13, 2025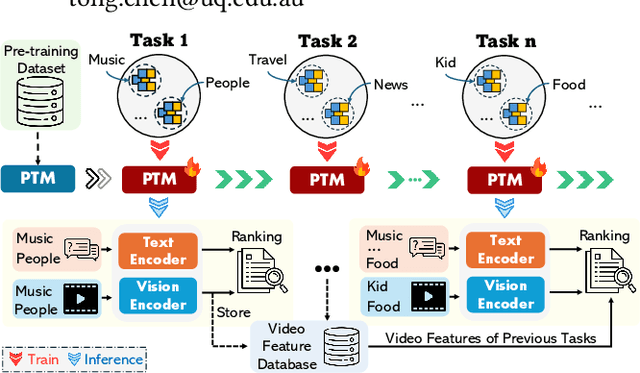
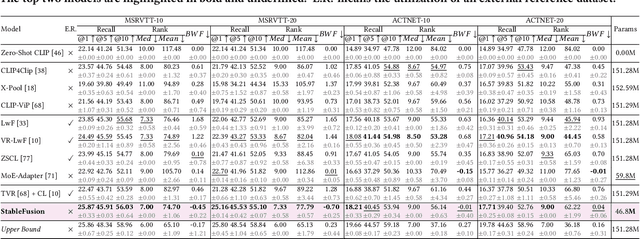
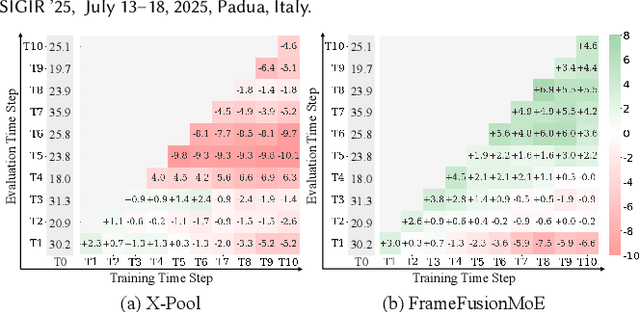
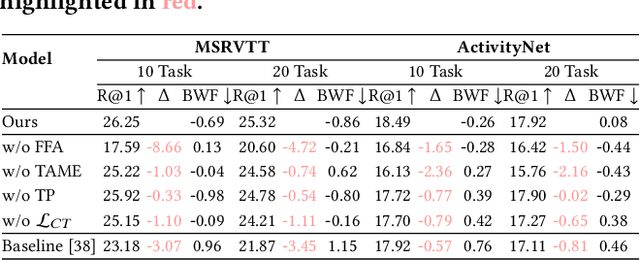
Text-to-Video Retrieval (TVR) aims to match videos with corresponding textual queries, yet the continual influx of new video content poses a significant challenge for maintaining system performance over time. In this work, we introduce the first benchmark for Continual Text-to-Video Retrieval (CTVR) to overcome these limitations. Our analysis reveals that current TVR methods based on pre-trained models struggle to retain plasticity when adapting to new tasks, while existing continual learning approaches experience catastrophic forgetting, resulting in semantic misalignment between historical queries and stored video features. To address these challenges, we propose StableFusion, a novel CTVR framework comprising two main components: the Frame Fusion Adapter (FFA), which captures temporal dynamics in video content while preserving model flexibility, and the Task-Aware Mixture-of-Experts (TAME), which maintains consistent semantic alignment between queries across tasks and the stored video features. Comprehensive evaluations on two benchmark datasets under various task settings demonstrate that StableFusion outperforms existing continual learning and TVR methods, achieving superior retrieval performance with minimal degradation on earlier tasks in the context of continuous video streams. Our code is available at: https://github.com/JasonCodeMaker/CTVR