 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableFusion: Continual Video Retrieval via Frame Adaptation
Paper and Code
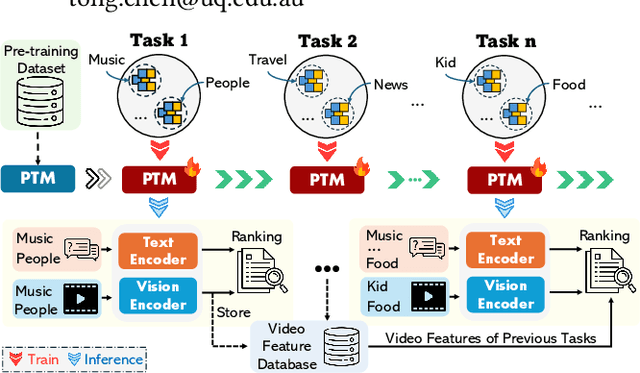
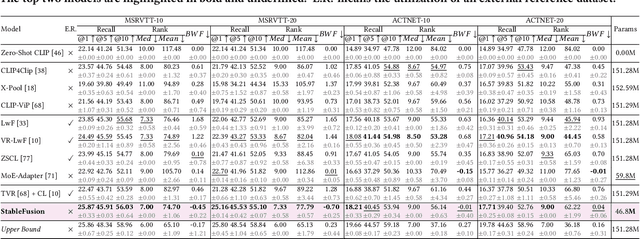
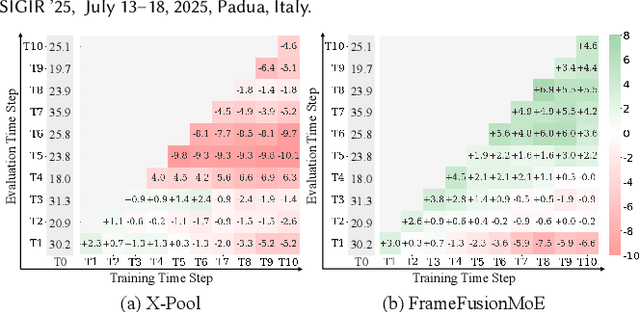
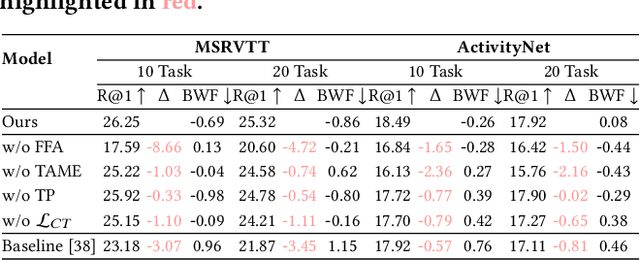
Text-to-Video Retrieval (TVR) aims to match videos with corresponding textual queries, yet the continual influx of new video content poses a significant challenge for maintaining system performance over time. In this work, we introduce the first benchmark for Continual Text-to-Video Retrieval (CTVR) to overcome these limitations. Our analysis reveals that current TVR methods based on pre-trained models struggle to retain plasticity when adapting to new tasks, while existing continual learning approaches experience catastrophic forgetting, resulting in semantic misalignment between historical queries and stored video features. To address these challenges, we propose StableFusion, a novel CTVR framework comprising two main components: the Frame Fusion Adapter (FFA), which captures temporal dynamics in video content while preserving model flexibility, and the Task-Aware Mixture-of-Experts (TAME), which maintains consistent semantic alignment between queries across tasks and the stored video features. Comprehensive evaluations on two benchmark datasets under various task settings demonstrate that StableFusion outperforms existing continual learning and TVR methods, achieving superior retrieval performance with minimal degradation on earlier tasks in the context of continuous video streams. Our code is available at: https://github.com/JasonCodeMaker/CTVR