 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Recall, Dense Reranking: Learning Multi-View Semantic IDs for Efficient Text-to-Video Retrieval
Jan 29, 2026Text-to-Video Retrieval (TVR) is essential in video platforms. Dense retrieval with dual-modality encoders leads in accuracy, but its computation and storage scale poorly with corpus size. Thus, real-time large-scale applications adopt two-stage retrieval, where a fast recall model gathers a small candidate pool, which is reranked by an advanced dense retriever. Due to hugely reduced candidates, the reranking model can use any off-the-shelf dense retriever without hurting efficiency, meaning the recall model bounds two-stage TVR performance. Recently, generative retrieval (GR) replaces dense video embeddings with discrete semantic IDs and retrieves by decoding text queries into ID tokens. GR offers near-constant inference and storage complexity, and its semantic IDs capture high-level video features via quantization, making it ideal for quickly eliminating irrelevant candidates during recall. However, as a recall model in two-stage TVR, GR suffers from (i) semantic ambiguity, where each video satisfies diverse queries but is forced into one semantic ID; and (ii) cross-modal misalignment, as semantic IDs are solely derived from visual features without text supervision. We propose Generative Recall and Dense Reranking (GRDR), designing a novel GR method to uplift recalled candidate quality. GRDR assigns multiple semantic IDs to each video using a query-guided multi-view tokenizer exposing diverse semantic access paths, and jointly trains the tokenizer and generative retriever via a shared codebook to cast semantic IDs as the semantic bridge between texts and videos. At inference, trie-constrained decoding generates a compact candidate set reranked by a dense model for fine-grained matching. Experiments on TVR benchmarks show GRDR matches strong dense retrievers in accuracy while reducing index storage by an order of magnitude and accelerating up to 300$\times$ in full-corpus retrieval.
Are Synthetic Videos Useful? A Benchmark for Retrieval-Centric Evaluation of Synthetic Videos
Jul 03, 2025Text-to-video (T2V) synthesis has advanced rapidly, yet current evaluation metrics primarily capture visual quality and temporal consistency, offering limited insight into how synthetic videos perform in downstream tasks such as text-to-video retrieval (TVR). In this work, we introduce SynTVA, a new dataset and benchmark designed to evaluate the utility of synthetic videos for building retrieval models. Based on 800 diverse user queries derived from MSRVTT training split, we generate synthetic videos using state-of-the-art T2V models and annotate each video-text pair along four key semantic alignment dimensions: Object \& Scene, Action, Attribute, and Prompt Fidelity. Our evaluation framework correlates general video quality assessment (VQA) metrics with these alignment scores, and examines their predictive power for downstream TVR performance. To explore pathways of scaling up, we further develop an Auto-Evaluator to estimate alignment quality from existing metrics. Beyond benchmarking, our results show that SynTVA is a valuable asset for dataset augmentation, enabling the selection of high-utility synthetic samples that measurably improve TVR outcomes. Project page and dataset can be found at https://jasoncodemaker.github.io/SynTVA/.
StableFusion: Continual Video Retrieval via Frame Adaptation
Mar 13, 2025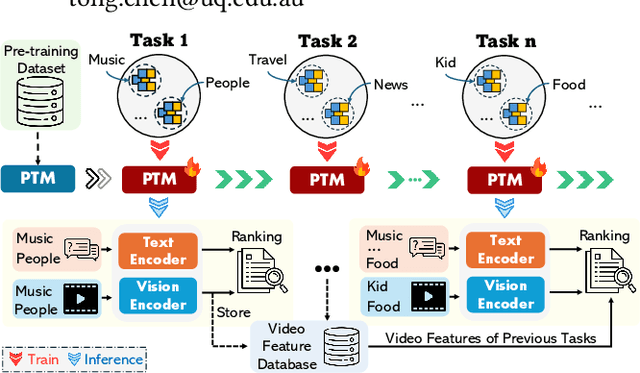
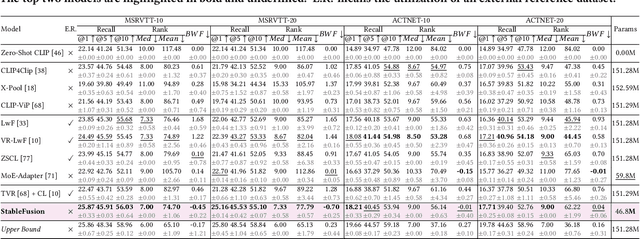
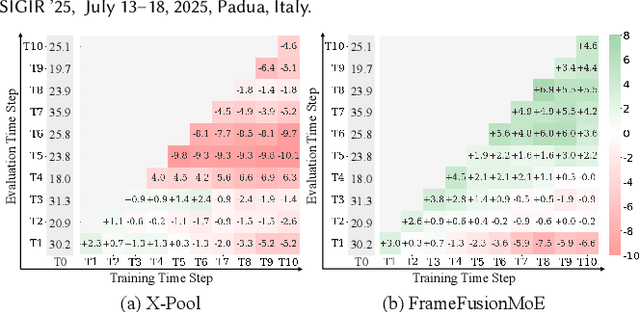
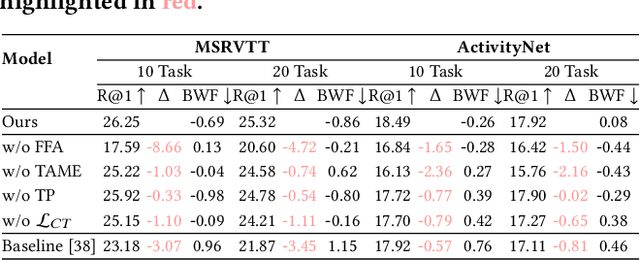
Text-to-Video Retrieval (TVR) aims to match videos with corresponding textual queries, yet the continual influx of new video content poses a significant challenge for maintaining system performance over time. In this work, we introduce the first benchmark for Continual Text-to-Video Retrieval (CTVR) to overcome these limitations. Our analysis reveals that current TVR methods based on pre-trained models struggle to retain plasticity when adapting to new tasks, while existing continual learning approaches experience catastrophic forgetting, resulting in semantic misalignment between historical queries and stored video features. To address these challenges, we propose StableFusion, a novel CTVR framework comprising two main components: the Frame Fusion Adapter (FFA), which captures temporal dynamics in video content while preserving model flexibility, and the Task-Aware Mixture-of-Experts (TAME), which maintains consistent semantic alignment between queries across tasks and the stored video features. Comprehensive evaluations on two benchmark datasets under various task settings demonstrate that StableFusion outperforms existing continual learning and TVR methods, achieving superior retrieval performance with minimal degradation on earlier tasks in the context of continuous video streams. Our code is available at: https://github.com/JasonCodeMaker/CTVR
SVIP: Semantically Contextualized Visual Patches for Zero-Shot Learning
Mar 13, 2025



Zero-shot learning (ZSL) aims to recognize unseen classes without labeled training examples by leveraging class-level semantic descriptors such as attributes. A fundamental challenge in ZSL is semantic misalignment, where semantic-unrelated information involved in visual features introduce ambiguity to visual-semantic interaction. Unlike existing methods that suppress semantic-unrelated information post hoc either in the feature space or the model space, we propose addressing this issue at the input stage, preventing semantic-unrelated patches from propagating through the network. To this end, we introduce Semantically contextualized VIsual Patches (SVIP) for ZSL, a transformer-based framework designed to enhance visual-semantic alignment. Specifically, we propose a self-supervised patch selection mechanism that preemptively learns to identify semantic-unrelated patches in the input space. This is trained with the supervision from aggregated attention scores across all transformer layers, which estimate each patch's semantic score. As removing semantic-unrelated patches from the input sequence may disrupt object structure, we replace them with learnable patch embeddings. With initialization from word embeddings, we can ensure they remain semantically meaningful throughout feature extraction. Extensive experiments on ZSL benchmarks demonstrate that SVIP achieves state-of-the-art performance results while providing more interpretable and semantically rich feature representations.
CF-PRNet: Coarse-to-Fine Prototype Refining Network for Point Cloud Completion and Reconstruction
Sep 13, 2024



In modern agriculture, precise monitoring of plants and fruits is crucial for tasks such as high-throughput phenotyping and automated harvesting. This paper addresses the challenge of reconstructing accurate 3D shapes of fruits from partial views, which is common in agricultural settings. We introduce CF-PRNet, a coarse-to-fine prototype refining network, leverages high-resolution 3D data during the training phase but requires only a single RGB-D image for real-time inference. Our approach begins by extracting the incomplete point cloud data that constructed from a partial view of a fruit with a series of convolutional blocks. The extracted features inform the generation of scaling vectors that refine two sequentially constructed 3D mesh prototypes - one coarse and one fine-grained. This progressive refinement facilitates the detailed completion of the final point clouds, achieving detailed and accurate reconstructions. CF-PRNet demonstrates excellent performance metrics with a Chamfer Distance of 3.78, an F1 Score of 66.76%, a Precision of 56.56%, and a Recall of 85.31%, and win the first place in the Shape Completion and Reconstruction of Sweet Peppers Challenge.
FastEdit: Fast Text-Guided Single-Image Editing via Semantic-Aware Diffusion Fine-Tuning
Aug 06, 2024



Conventional Text-guided single-image editing approaches require a two-step process, including fine-tuning the target text embedding for over 1K iterations and the generative model for another 1.5K iterations. Although it ensures that the resulting image closely aligns with both the input image and the target text, this process often requires 7 minutes per image, posing a challenge for practical application due to its time-intensive nature. To address this bottleneck, we introduce FastEdit, a fast text-guided single-image editing method with semantic-aware diffusion fine-tuning, dramatically accelerating the editing process to only 17 seconds. FastEdit streamlines the generative model's fine-tuning phase, reducing it from 1.5K to a mere 50 iterations. For diffusion fine-tuning, we adopt certain time step values based on the semantic discrepancy between the input image and target text. Furthermore, FastEdit circumvents the initial fine-tuning step by utilizing an image-to-image model that conditions on the feature space, rather than the text embedding space. It can effectively align the target text prompt and input image within the same feature space and save substantial processing time. Additionally, we apply the parameter-efficient fine-tuning technique LoRA to U-net. With LoRA, FastEdit minimizes the model's trainable parameters to only 0.37\% of the original size. At the same time, we can achieve comparable editing outcomes with significantly reduced computational overhead. We conduct extensive experiments to validate the editing performance of our approach and show promising editing capabilities, including content addition, style transfer, background replacement, and posture manipulation, etc.