 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Trajectory Prediction: A Unified Framework Harnessing Positional and Semantic Uncertainties
Mar 31, 2026Trajectory prediction seeks to forecast the future motion of dynamic entities, such as vehicles and pedestrians, given a temporal horizon of historical movement data and environmental context. A central challenge in this domain is the inherent uncertainty in real-time maps, arising from two primary sources: (1) positional inaccuracies due to sensor limitations or environmental occlusions, and (2) semantic errors stemming from misinterpretations of scene context. To address these challenges, we propose a novel unified framework that jointly models positional and semantic uncertainties and explicitly integrates them into the trajectory prediction pipeline. Our approach employs a dual-head architecture to independently estimate semantic and positional predictions in a dual-pass manner, deriving prediction variances as uncertainty indicators in an end-to-end fashion. These uncertainties are subsequently fused with the semantic and positional predictions to enhance the robustness of trajectory forecasts. We evaluate our uncertainty-aware framework on the nuScenes real-world driving dataset, conducting extensive experiments across four map estimation methods and two trajectory prediction baselines. Results verify that our method (1) effectively quantifies map uncertainties through both positional and semantic dimensions, and (2) consistently improves the performance of existing trajectory prediction models across multiple metrics, including minimum Average Displacement Error (minADE), minimum Final Displacement Error (minFDE), and Miss Rate (MR). Code will available at https://github.com/JT-Sun/UATP.
Learning to Generate and Extract: A Multi-Agent Collaboration Framework For Zero-shot Document-level Event Arguments Extraction
Mar 04, 2026Document-level event argument extraction (DEAE) is essential for knowledge acquisition, aiming to extract participants of events from documents . In the zero-shot setting, existing methods employ LLMs to generate synthetic data to address the challenge posed by the scarcity of annotated data. However, relying solely on Event-type-only prompts makes it difficult for the generated content to accurately capture the contextual and structural relationships of unseen events. Moreover, ensuring the reliability and usability of synthetic data remains a significant challenge due to the absence of quality evaluation mechanisms. To this end, we introduce a multi-agent collaboration framework for zero-shot document-level event argument extraction (ZS-DEAE), which simulates the human collaborative cognitive process of "Propose-Evaluate-Revise." Specifically, the framework comprises a generation agent and an evaluation agent. The generation agent synthesizes data for unseen events by leveraging knowledge from seen events, while the evaluation agent extracts arguments from the synthetic data and assesses their semantic consistency with the context. The evaluation results are subsequently converted into reward signals, with event structure constraints incorporated into the reward design to enable iterative optimization of both agents via reinforcement learning.In three zero-shot scenarios constructed from the RAMS and WikiEvents datasets, our method achieves improvements both in data generation quality and argument extraction performance, while the generated data also effectively enhances the zero-shot performance of other DEAE models.
The Forecast After the Forecast: A Post-Processing Shift in Time Series
Jan 28, 2026Time series forecasting has long been dominated by advances in model architecture, with recent progress driven by deep learning and hybrid statistical techniques. However, as forecasting models approach diminishing returns in accuracy, a critical yet underexplored opportunity emerges: the strategic use of post-processing. In this paper, we address the last-mile gap in time-series forecasting, which is to improve accuracy and uncertainty without retraining or modifying a deployed backbone. We propose $δ$-Adapter, a lightweight, architecture-agnostic way to boost deployed time series forecasters without retraining. $δ$-Adapter learns tiny, bounded modules at two interfaces: input nudging (soft edits to covariates) and output residual correction. We provide local descent guarantees, $O(δ)$ drift bounds, and compositional stability for combined adapters. Meanwhile, it can act as a feature selector by learning a sparse, horizon-aware mask over inputs to select important features, thereby improving interpretability. In addition, it can also be used as a distribution calibrator to measure uncertainty. Thus, we introduce a Quantile Calibrator and a Conformal Corrector that together deliver calibrated, personalized intervals with finite-sample coverage. Our experiments across diverse backbones and datasets show that $δ$-Adapter improves accuracy and calibration with negligible compute and no interface changes.
* 30 Pages
MDMLP-EIA: Multi-domain Dynamic MLPs with Energy Invariant Attention for Time Series Forecasting
Nov 13, 2025Time series forecasting is essential across diverse domains. While MLP-based methods have gained attention for achieving Transformer-comparable performance with fewer parameters and better robustness, they face critical limitations including loss of weak seasonal signals, capacity constraints in weight-sharing MLPs, and insufficient channel fusion in channel-independent strategies. To address these challenges, we propose MDMLP-EIA (Multi-domain Dynamic MLPs with Energy Invariant Attention) with three key innovations. First, we develop an adaptive fused dual-domain seasonal MLP that categorizes seasonal signals into strong and weak components. It employs an adaptive zero-initialized channel fusion strategy to minimize noise interference while effectively integrating predictions. Second, we introduce an energy invariant attention mechanism that adaptively focuses on different feature channels within trend and seasonal predictions across time steps. This mechanism maintains constant total signal energy to align with the decomposition-prediction-reconstruction framework and enhance robustness against disturbances. Third, we propose a dynamic capacity adjustment mechanism for channel-independent MLPs. This mechanism scales neuron count with the square root of channel count, ensuring sufficient capacity as channels increase. Extensive experiments across nine benchmark datasets demonstrate that MDMLP-EIA achieves state-of-the-art performance in both prediction accuracy and computational efficiency.
AnomalyLMM: Bridging Generative Knowledge and Discriminative Retrieval for Text-Based Person Anomaly Search
Sep 04, 2025With growing public safety demands, text-based person anomaly search has emerged as a critical task, aiming to retrieve individuals with abnormal behaviors via natural language descriptions. Unlike conventional person search, this task presents two unique challenges: (1) fine-grained cross-modal alignment between textual anomalies and visual behaviors, and (2) anomaly recognition under sparse real-world samples. While Large Multi-modal Models (LMMs) excel in multi-modal understanding, their potential for fine-grained anomaly retrieval remains underexplored, hindered by: (1) a domain gap between generative knowledge and discriminative retrieval, and (2) the absence of efficient adaptation strategies for deployment. In this work, we propose AnomalyLMM, the first framework that harnesses LMMs for text-based person anomaly search. Our key contributions are: (1) A novel coarse-to-fine pipeline integrating LMMs to bridge generative world knowledge with retrieval-centric anomaly detection; (2) A training-free adaptation cookbook featuring masked cross-modal prompting, behavioral saliency prediction, and knowledge-aware re-ranking, enabling zero-shot focus on subtle anomaly cues. As the first study to explore LMMs for this task, we conduct a rigorous evaluation on the PAB dataset, the only publicly available benchmark for text-based person anomaly search, with its curated real-world anomalies covering diverse scenarios (e.g., falling, collision, and being hit). Experiments show the effectiveness of the proposed method, surpassing the competitive baseline by +0.96% Recall@1 accuracy. Notably, our method reveals interpretable alignment between textual anomalies and visual behaviors, validated via qualitative analysis. Our code and models will be released for future research.
Ultra3D: Efficient and High-Fidelity 3D Generation with Part Attention
Jul 23, 2025



Recent advances in sparse voxel representations have significantly improved the quality of 3D content generation, enabling high-resolution modeling with fine-grained geometry. However, existing frameworks suffer from severe computational inefficiencies due to the quadratic complexity of attention mechanisms in their two-stage diffusion pipelines. In this work, we propose Ultra3D, an efficient 3D generation framework that significantly accelerates sparse voxel modeling without compromising quality. Our method leverages the compact VecSet representation to efficiently generate a coarse object layout in the first stage, reducing token count and accelerating voxel coordinate prediction. To refine per-voxel latent features in the second stage, we introduce Part Attention, a geometry-aware localized attention mechanism that restricts attention computation within semantically consistent part regions. This design preserves structural continuity while avoiding unnecessary global attention, achieving up to 6.7x speed-up in latent generation. To support this mechanism, we construct a scalable part annotation pipeline that converts raw meshes into part-labeled sparse voxels. Extensive experiments demonstrate that Ultra3D supports high-resolution 3D generation at 1024 resolution and achieves state-of-the-art performance in both visual fidelity and user preference.
Uncertainty-o: One Model-agnostic Framework for Unveiling Uncertainty in Large Multimodal Models
Jun 09, 2025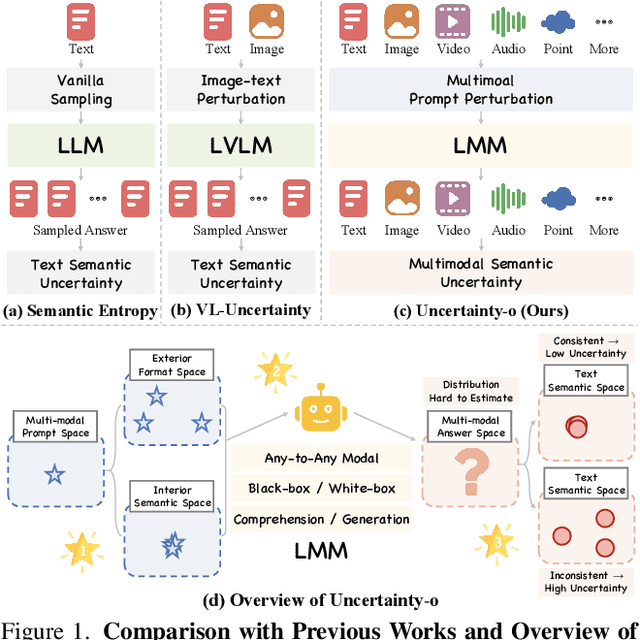
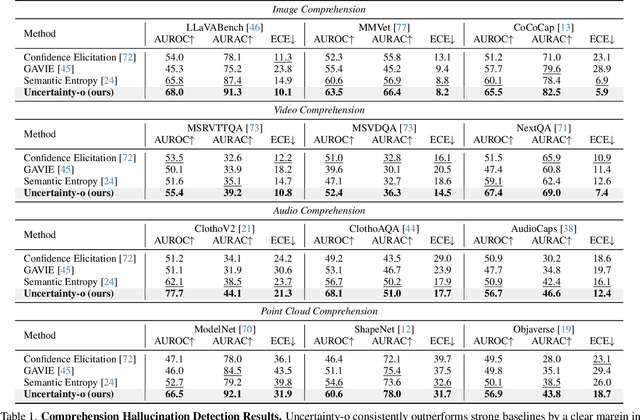
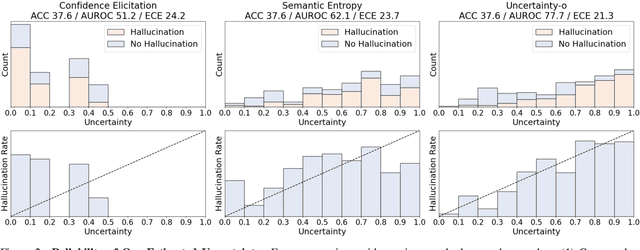

Large Multimodal Models (LMMs), harnessing the complementarity among diverse modalities, are often considered more robust than pure Language Large Models (LLMs); yet do LMMs know what they do not know? There are three key open questions remaining: (1) how to evaluate the uncertainty of diverse LMMs in a unified manner, (2) how to prompt LMMs to show its uncertainty, and (3) how to quantify uncertainty for downstream tasks. In an attempt to address these challenges, we introduce Uncertainty-o: (1) a model-agnostic framework designed to reveal uncertainty in LMMs regardless of their modalities, architectures, or capabilities, (2) an empirical exploration of multimodal prompt perturbations to uncover LMM uncertainty, offering insights and findings, and (3) derive the formulation of multimodal semantic uncertainty, which enables quantifying uncertainty from multimodal responses. Experiments across 18 benchmarks spanning various modalities and 10 LMMs (both open- and closed-source) demonstrate the effectiveness of Uncertainty-o in reliably estimating LMM uncertainty, thereby enhancing downstream tasks such as hallucination detection, hallucination mitigation, and uncertainty-aware Chain-of-Thought reasoning.
Echo Planning for Autonomous Driving: From Current Observations to Future Trajectories and Back
May 25, 2025Modern end-to-end autonomous driving systems suffer from a critical limitation: their planners lack mechanisms to enforce temporal consistency between predicted trajectories and evolving scene dynamics. This absence of self-supervision allows early prediction errors to compound catastrophically over time. We introduce Echo Planning, a novel self-correcting framework that establishes a closed-loop Current - Future - Current (CFC) cycle to harmonize trajectory prediction with scene coherence. Our key insight is that plausible future trajectories must be bi-directionally consistent, ie, not only generated from current observations but also capable of reconstructing them. The CFC mechanism first predicts future trajectories from the Bird's-Eye-View (BEV) scene representation, then inversely maps these trajectories back to estimate the current BEV state. By enforcing consistency between the original and reconstructed BEV representations through a cycle loss, the framework intrinsically penalizes physically implausible or misaligned trajectories. Experiments on nuScenes demonstrate state-of-the-art performance, reducing L2 error by 0.04 m and collision rate by 0.12% compared to one-shot planners. Crucially, our method requires no additional supervision, leveraging the CFC cycle as an inductive bias for robust planning. This work offers a deployable solution for safety-critical autonomous systems.
VL-Uncertainty: Detecting Hallucination in Large Vision-Language Model via Uncertainty Estimation
Nov 18, 2024



Given the higher information load processed by large vision-language models (LVLMs) compared to single-modal LLMs, detecting LVLM hallucinations requires more human and time expense, and thus rise a wider safety concerns. In this paper, we introduce VL-Uncertainty, the first uncertainty-based framework for detecting hallucinations in LVLMs. Different from most existing methods that require ground-truth or pseudo annotations, VL-Uncertainty utilizes uncertainty as an intrinsic metric. We measure uncertainty by analyzing the prediction variance across semantically equivalent but perturbed prompts, including visual and textual data. When LVLMs are highly confident, they provide consistent responses to semantically equivalent queries. However, when uncertain, the responses of the target LVLM become more random. Considering semantically similar answers with different wordings, we cluster LVLM responses based on their semantic content and then calculate the cluster distribution entropy as the uncertainty measure to detect hallucination. Our extensive experiments on 10 LVLMs across four benchmarks, covering both free-form and multi-choice tasks, show that VL-Uncertainty significantly outperforms strong baseline methods in hallucination detection.
CF-PRNet: Coarse-to-Fine Prototype Refining Network for Point Cloud Completion and Reconstruction
Sep 13, 2024



In modern agriculture, precise monitoring of plants and fruits is crucial for tasks such as high-throughput phenotyping and automated harvesting. This paper addresses the challenge of reconstructing accurate 3D shapes of fruits from partial views, which is common in agricultural settings. We introduce CF-PRNet, a coarse-to-fine prototype refining network, leverages high-resolution 3D data during the training phase but requires only a single RGB-D image for real-time inference. Our approach begins by extracting the incomplete point cloud data that constructed from a partial view of a fruit with a series of convolutional blocks. The extracted features inform the generation of scaling vectors that refine two sequentially constructed 3D mesh prototypes - one coarse and one fine-grained. This progressive refinement facilitates the detailed completion of the final point clouds, achieving detailed and accurate reconstructions. CF-PRNet demonstrates excellent performance metrics with a Chamfer Distance of 3.78, an F1 Score of 66.76%, a Precision of 56.56%, and a Recall of 85.31%, and win the first place in the Shape Completion and Reconstruction of Sweet Peppers Challenge.