 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoDCL: Informative Noise Enhanced Diffusion Based Contrastive Learning
Dec 18, 2025Contrastive learning has demonstrated promising potential in recommender systems. Existing methods typically construct sparser views by randomly perturbing the original interaction graph, as they have no idea about the authentic user preferences. Owing to the sparse nature of recommendation data, this paradigm can only capture insufficient semantic information. To address the issue, we propose InfoDCL, a novel diffusion-based contrastive learning framework for recommendation. Rather than injecting randomly sampled Gaussian noise, we employ a single-step diffusion process that integrates noise with auxiliary semantic information to generate signals and feed them to the standard diffusion process to generate authentic user preferences as contrastive views. Besides, based on a comprehensive analysis of the mutual influence between generation and preference learning in InfoDCL, we build a collaborative training objective strategy to transform the interference between them into mutual collaboration. Additionally, we employ multiple GCN layers only during inference stage to incorporate higher-order co-occurrence information while maintaining training efficiency. Extensive experiments on five real-world datasets demonstrate that InfoDCL significantly outperforms state-of-the-art methods. Our InfoDCL offers an effective solution for enhancing recommendation performance and suggests a novel paradigm for applying diffusion method in contrastive learning frameworks.
Task-Aware 3D Affordance Segmentation via 2D Guidance and Geometric Refinement
Nov 12, 2025Understanding 3D scene-level affordances from natural language instructions is essential for enabling embodied agents to interact meaningfully in complex environments. However, this task remains challenging due to the need for semantic reasoning and spatial grounding. Existing methods mainly focus on object-level affordances or merely lift 2D predictions to 3D, neglecting rich geometric structure information in point clouds and incurring high computational costs. To address these limitations, we introduce Task-Aware 3D Scene-level Affordance segmentation (TASA), a novel geometry-optimized framework that jointly leverages 2D semantic cues and 3D geometric reasoning in a coarse-to-fine manner. To improve the affordance detection efficiency, TASA features a task-aware 2D affordance detection module to identify manipulable points from language and visual inputs, guiding the selection of task-relevant views. To fully exploit 3D geometric information, a 3D affordance refinement module is proposed to integrate 2D semantic priors with local 3D geometry, resulting in accurate and spatially coherent 3D affordance masks. Experiments on SceneFun3D demonstrate that TASA significantly outperforms the baselines in both accuracy and efficiency in scene-level affordance segmentation.
Echo Planning for Autonomous Driving: From Current Observations to Future Trajectories and Back
May 25, 2025Modern end-to-end autonomous driving systems suffer from a critical limitation: their planners lack mechanisms to enforce temporal consistency between predicted trajectories and evolving scene dynamics. This absence of self-supervision allows early prediction errors to compound catastrophically over time. We introduce Echo Planning, a novel self-correcting framework that establishes a closed-loop Current - Future - Current (CFC) cycle to harmonize trajectory prediction with scene coherence. Our key insight is that plausible future trajectories must be bi-directionally consistent, ie, not only generated from current observations but also capable of reconstructing them. The CFC mechanism first predicts future trajectories from the Bird's-Eye-View (BEV) scene representation, then inversely maps these trajectories back to estimate the current BEV state. By enforcing consistency between the original and reconstructed BEV representations through a cycle loss, the framework intrinsically penalizes physically implausible or misaligned trajectories. Experiments on nuScenes demonstrate state-of-the-art performance, reducing L2 error by 0.04 m and collision rate by 0.12% compared to one-shot planners. Crucially, our method requires no additional supervision, leveraging the CFC cycle as an inductive bias for robust planning. This work offers a deployable solution for safety-critical autonomous systems.
From Data Deluge to Data Curation: A Filtering-WoRA Paradigm for Efficient Text-based Person Search
Apr 16, 2024In text-based person search endeavors, data generation has emerged as a prevailing practice, addressing concerns over privacy preservation and the arduous task of manual annotation. Although the number of synthesized data can be infinite in theory, the scientific conundrum persists that how much generated data optimally fuels subsequent model training. We observe that only a subset of the data in these constructed datasets plays a decisive role. Therefore, we introduce a new Filtering-WoRA paradigm, which contains a filtering algorithm to identify this crucial data subset and WoRA (Weighted Low-Rank Adaptation) learning strategy for light fine-tuning. The filtering algorithm is based on the cross-modality relevance to remove the lots of coarse matching synthesis pairs. As the number of data decreases, we do not need to fine-tune the entire model. Therefore, we propose a WoRA learning strategy to efficiently update a minimal portion of model parameters. WoRA streamlines the learning process, enabling heightened efficiency in extracting knowledge from fewer, yet potent, data instances. Extensive experimentation validates the efficacy of pretraining, where our model achieves advanced and efficient retrieval performance on challenging real-world benchmarks. Notably, on the CUHK-PEDES dataset, we have achieved a competitive mAP of 67.02% while reducing model training time by 19.82%.
Human Pose Transfer with Disentangled Feature Consistency
Aug 06, 2021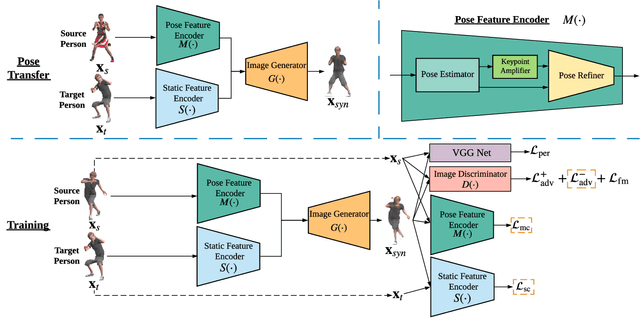



Deep generative models have made great progress in synthesizing images with arbitrary human poses and transferring poses of one person to others. However, most existing approaches explicitly leverage the pose information extracted from the source images as a conditional input for the generative networks. Meanwhile, they usually focus on the visual fidelity of the synthesized images but neglect the inherent consistency, which further confines their performance of pose transfer. To alleviate the current limitations and improve the quality of the synthesized images, we propose a pose transfer network with Disentangled Feature Consistency (DFC-Net) to facilitate human pose transfer. Given a pair of images containing the source and target person, DFC-Net extracts pose and static information from the source and target respectively, then synthesizes an image of the target person with the desired pose from the source. Moreover, DFC-Net leverages disentangled feature consistency losses in the adversarial training to strengthen the transfer coherence and integrates the keypoint amplifier to enhance the pose feature extraction. Additionally, an unpaired support dataset Mixamo-Sup providing more extra pose information has been further utilized during the training to improve the generality and robustness of DFC-Net. Extensive experimental results on Mixamo-Pose and EDN-10k have demonstrated DFC-Net achieves state-of-the-art performance on pose transfer.