 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Pose Transfer with Disentangled Feature Consistency
Aug 06, 2021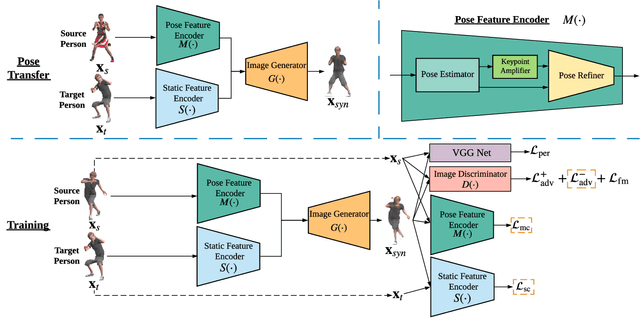



Deep generative models have made great progress in synthesizing images with arbitrary human poses and transferring poses of one person to others. However, most existing approaches explicitly leverage the pose information extracted from the source images as a conditional input for the generative networks. Meanwhile, they usually focus on the visual fidelity of the synthesized images but neglect the inherent consistency, which further confines their performance of pose transfer. To alleviate the current limitations and improve the quality of the synthesized images, we propose a pose transfer network with Disentangled Feature Consistency (DFC-Net) to facilitate human pose transfer. Given a pair of images containing the source and target person, DFC-Net extracts pose and static information from the source and target respectively, then synthesizes an image of the target person with the desired pose from the source. Moreover, DFC-Net leverages disentangled feature consistency losses in the adversarial training to strengthen the transfer coherence and integrates the keypoint amplifier to enhance the pose feature extraction. Additionally, an unpaired support dataset Mixamo-Sup providing more extra pose information has been further utilized during the training to improve the generality and robustness of DFC-Net. Extensive experimental results on Mixamo-Pose and EDN-10k have demonstrated DFC-Net achieves state-of-the-art performance on pose transfer.