 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboMIND 2.0: A Multimodal, Bimanual Mobile Manipulation Dataset for Generalizable Embodied Intelligence
Dec 31, 2025While data-driven imitation learning has revolutionized robotic manipulation, current approaches remain constrained by the scarcity of large-scale, diverse real-world demonstrations. Consequently, the ability of existing models to generalize across long-horizon bimanual tasks and mobile manipulation in unstructured environments remains limited. To bridge this gap, we present RoboMIND 2.0, a comprehensive real-world dataset comprising over 310K dual-arm manipulation trajectories collected across six distinct robot embodiments and 739 complex tasks. Crucially, to support research in contact-rich and spatially extended tasks, the dataset incorporates 12K tactile-enhanced episodes and 20K mobile manipulation trajectories. Complementing this physical data, we construct high-fidelity digital twins of our real-world environments, releasing an additional 20K-trajectory simulated dataset to facilitate robust sim-to-real transfer. To fully exploit the potential of RoboMIND 2.0, we propose MIND-2 system, a hierarchical dual-system frame-work optimized via offline reinforcement learning. MIND-2 integrates a high-level semantic planner (MIND-2-VLM) to decompose abstract natural language instructions into grounded subgoals, coupled with a low-level Vision-Language-Action executor (MIND-2-VLA), which generates precise, proprioception-aware motor actions.
Real-world Reinforcement Learning from Suboptimal Interventions
Dec 30, 2025Real-world reinforcement learning (RL) offers a promising approach to training precise and dexterous robotic manipulation policies in an online manner, enabling robots to learn from their own experience while gradually reducing human labor. However, prior real-world RL methods often assume that human interventions are optimal across the entire state space, overlooking the fact that even expert operators cannot consistently provide optimal actions in all states or completely avoid mistakes. Indiscriminately mixing intervention data with robot-collected data inherits the sample inefficiency of RL, while purely imitating intervention data can ultimately degrade the final performance achievable by RL. The question of how to leverage potentially suboptimal and noisy human interventions to accelerate learning without being constrained by them thus remains open. To address this challenge, we propose SiLRI, a state-wise Lagrangian reinforcement learning algorithm for real-world robot manipulation tasks. Specifically, we formulate the online manipulation problem as a constrained RL optimization, where the constraint bound at each state is determined by the uncertainty of human interventions. We then introduce a state-wise Lagrange multiplier and solve the problem via a min-max optimization, jointly optimizing the policy and the Lagrange multiplier to reach a saddle point. Built upon a human-as-copilot teleoperation system, our algorithm is evaluated through real-world experiments on diverse manipulation tasks. Experimental results show that SiLRI effectively exploits human suboptimal interventions, reducing the time required to reach a 90% success rate by at least 50% compared with the state-of-the-art RL method HIL-SERL, and achieving a 100% success rate on long-horizon manipulation tasks where other RL methods struggle to succeed. Project website: https://silri-rl.github.io/.
MLA: A Multisensory Language-Action Model for Multimodal Understanding and Forecasting in Robotic Manipulation
Sep 30, 2025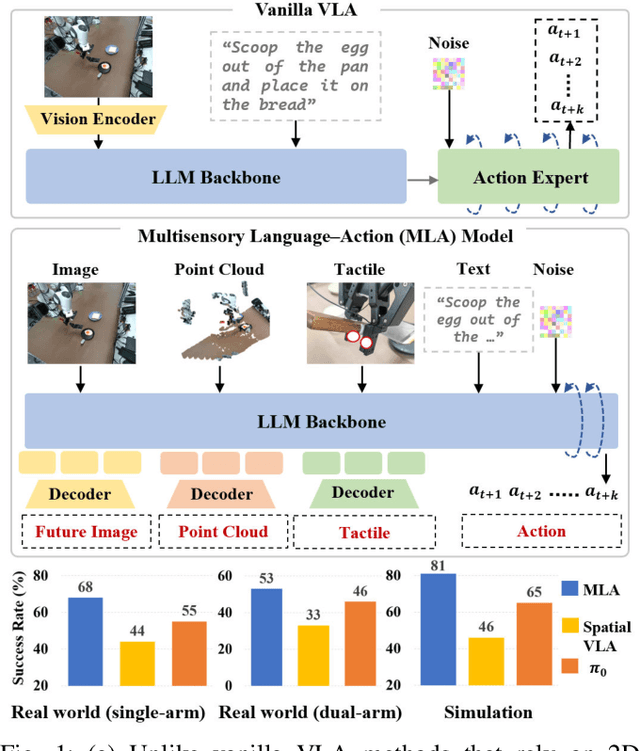
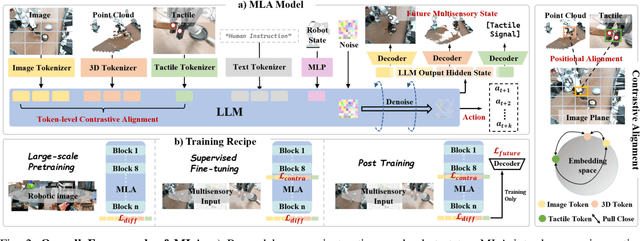
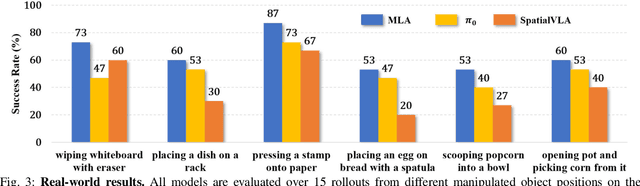

Vision-language-action models (VLAs) have shown generalization capabilities in robotic manipulation tasks by inheriting from vision-language models (VLMs) and learning action generation. Most VLA models focus on interpreting vision and language to generate actions, whereas robots must perceive and interact within the spatial-physical world. This gap highlights the need for a comprehensive understanding of robotic-specific multisensory information, which is crucial for achieving complex and contact-rich control. To this end, we introduce a multisensory language-action (MLA) model that collaboratively perceives heterogeneous sensory modalities and predicts future multisensory objectives to facilitate physical world modeling. Specifically, to enhance perceptual representations, we propose an encoder-free multimodal alignment scheme that innovatively repurposes the large language model itself as a perception module, directly interpreting multimodal cues by aligning 2D images, 3D point clouds, and tactile tokens through positional correspondence. To further enhance MLA's understanding of physical dynamics, we design a future multisensory generation post-training strategy that enables MLA to reason about semantic, geometric, and interaction information, providing more robust conditions for action generation. For evaluation, the MLA model outperforms the previous state-of-the-art 2D and 3D VLA methods by 12% and 24% in complex, contact-rich real-world tasks, respectively, while also demonstrating improved generalization to unseen configurations. Project website: https://sites.google.com/view/open-mla
Self-Supervised Multi-Part Articulated Objects Modeling via Deformable Gaussian Splatting and Progressive Primitive Segmentation
Jun 11, 2025Articulated objects are ubiquitous in everyday life, and accurate 3D representations of their geometry and motion are critical for numerous applications. However, in the absence of human annotation, existing approaches still struggle to build a unified representation for objects that contain multiple movable parts. We introduce DeGSS, a unified framework that encodes articulated objects as deformable 3D Gaussian fields, embedding geometry, appearance, and motion in one compact representation. Each interaction state is modeled as a smooth deformation of a shared field, and the resulting deformation trajectories guide a progressive coarse-to-fine part segmentation that identifies distinct rigid components, all in an unsupervised manner. The refined field provides a spatially continuous, fully decoupled description of every part, supporting part-level reconstruction and precise modeling of their kinematic relationships. To evaluate generalization and realism, we enlarge the synthetic PartNet-Mobility benchmark and release RS-Art, a real-to-sim dataset that pairs RGB captures with accurately reverse-engineered 3D models. Extensive experiments demonstrate that our method outperforms existing methods in both accuracy and stability.
FreqPolicy: Efficient Flow-based Visuomotor Policy via Frequency Consistency
Jun 10, 2025Generative modeling-based visuomotor policies have been widely adopted in robotic manipulation attributed to their ability to model multimodal action distributions. However, the high inference cost of multi-step sampling limits their applicability in real-time robotic systems. To address this issue, existing approaches accelerate the sampling process in generative modeling-based visuomotor policies by adapting acceleration techniques originally developed for image generation. Despite this progress, a major distinction remains: image generation typically involves producing independent samples without temporal dependencies, whereas robotic manipulation involves generating time-series action trajectories that require continuity and temporal coherence. To effectively exploit temporal information in robotic manipulation, we propose FreqPolicy, a novel approach that first imposes frequency consistency constraints on flow-based visuomotor policies. Our work enables the action model to capture temporal structure effectively while supporting efficient, high-quality one-step action generation. We introduce a frequency consistency constraint that enforces alignment of frequency-domain action features across different timesteps along the flow, thereby promoting convergence of one-step action generation toward the target distribution. In addition, we design an adaptive consistency loss to capture structural temporal variations inherent in robotic manipulation tasks. We assess FreqPolicy on 53 tasks across 3 simulation benchmarks, proving its superiority over existing one-step action generators. We further integrate FreqPolicy into the vision-language-action (VLA) model and achieve acceleration without performance degradation on the 40 tasks of Libero. Besides, we show efficiency and effectiveness in real-world robotic scenarios with an inference frequency 93.5Hz. The code will be publicly available.
RoboPARA: Dual-Arm Robot Planning with Parallel Allocation and Recomposition Across Tasks
Jun 07, 2025Dual-arm robots play a crucial role in improving efficiency and flexibility in complex multitasking scenarios. While existing methods have achieved promising results in task planning, they often fail to fully optimize task parallelism, limiting the potential of dual-arm collaboration. To address this issue, we propose RoboPARA, a novel large language model (LLM)-driven framework for dual-arm task parallelism planning. RoboPARA employs a two-stage process: (1) Dependency Graph-based Planning Candidates Generation, which constructs directed acyclic graphs (DAGs) to model task dependencies and eliminate redundancy, and (2) Graph Re-Traversal-based Dual-Arm Parallel Planning, which optimizes DAG traversal to maximize parallelism while maintaining task coherence. In addition, we introduce the Cross-Scenario Dual-Arm Parallel Task dataset (X-DAPT dataset), the first dataset specifically designed to evaluate dual-arm task parallelism across diverse scenarios and difficulty levels. Extensive experiments on the X-DAPT dataset demonstrate that RoboPARA significantly outperforms existing methods, achieving higher efficiency and reliability, particularly in complex task combinations. The code and dataset will be released upon acceptance.
ArtVIP: Articulated Digital Assets of Visual Realism, Modular Interaction, and Physical Fidelity for Robot Learning
Jun 06, 2025Robot learning increasingly relies on simulation to advance complex ability such as dexterous manipulations and precise interactions, necessitating high-quality digital assets to bridge the sim-to-real gap. However, existing open-source articulated-object datasets for simulation are limited by insufficient visual realism and low physical fidelity, which hinder their utility for training models mastering robotic tasks in real world. To address these challenges, we introduce ArtVIP, a comprehensive open-source dataset comprising high-quality digital-twin articulated objects, accompanied by indoor-scene assets. Crafted by professional 3D modelers adhering to unified standards, ArtVIP ensures visual realism through precise geometric meshes and high-resolution textures, while physical fidelity is achieved via fine-tuned dynamic parameters. Meanwhile, the dataset pioneers embedded modular interaction behaviors within assets and pixel-level affordance annotations. Feature-map visualization and optical motion capture are employed to quantitatively demonstrate ArtVIP's visual and physical fidelity, with its applicability validated across imitation learning and reinforcement learning experiments. Provided in USD format with detailed production guidelines, ArtVIP is fully open-source, benefiting the research community and advancing robot learning research. Our project is at https://x-humanoid-artvip.github.io/ .
Occupancy World Model for Robots
May 07, 2025Understanding and forecasting the scene evolutions deeply affect the exploration and decision of embodied agents. While traditional methods simulate scene evolutions through trajectory prediction of potential instances, current works use the occupancy world model as a generative framework for describing fine-grained overall scene dynamics. However, existing methods cluster on the outdoor structured road scenes, while ignoring the exploration of forecasting 3D occupancy scene evolutions for robots in indoor scenes. In this work, we explore a new framework for learning the scene evolutions of observed fine-grained occupancy and propose an occupancy world model based on the combined spatio-temporal receptive field and guided autoregressive transformer to forecast the scene evolutions, called RoboOccWorld. We propose the Conditional Causal State Attention (CCSA), which utilizes camera poses of next state as conditions to guide the autoregressive transformer to adapt and understand the indoor robotics scenarios. In order to effectively exploit the spatio-temporal cues from historical observations, Hybrid Spatio-Temporal Aggregation (HSTA) is proposed to obtain the combined spatio-temporal receptive field based on multi-scale spatio-temporal windows. In addition, we restructure the OccWorld-ScanNet benchmark based on local annotations to facilitate the evaluation of the indoor 3D occupancy scene evolution prediction task. Experimental results demonstrate that our RoboOccWorld outperforms state-of-the-art methods in indoor 3D occupancy scene evolution prediction task. The code will be released soon.
HACTS: a Human-As-Copilot Teleoperation System for Robot Learning
Mar 31, 2025Teleoperation is essential for autonomous robot learning, especially in manipulation tasks that require human demonstrations or corrections. However, most existing systems only offer unilateral robot control and lack the ability to synchronize the robot's status with the teleoperation hardware, preventing real-time, flexible intervention. In this work, we introduce HACTS (Human-As-Copilot Teleoperation System), a novel system that establishes bilateral, real-time joint synchronization between a robot arm and teleoperation hardware. This simple yet effective feedback mechanism, akin to a steering wheel in autonomous vehicles, enables the human copilot to intervene seamlessly while collecting action-correction data for future learning. Implemented using 3D-printed components and low-cost, off-the-shelf motors, HACTS is both accessible and scalable. Our experiments show that HACTS significantly enhances performance in imitation learning (IL) and reinforcement learning (RL) tasks, boosting IL recovery capabilities and data efficiency, and facilitating human-in-the-loop RL. HACTS paves the way for more effective and interactive human-robot collaboration and data-collection, advancing the capabilities of robot manipulation.
ACL-QL: Adaptive Conservative Level in Q-Learning for Offline Reinforcement Learning
Dec 22, 2024Offline Reinforcement Learning (RL), which operates solely on static datasets without further interactions with the environment, provides an appealing alternative to learning a safe and promising control policy. The prevailing methods typically learn a conservative policy to mitigate the problem of Q-value overestimation, but it is prone to overdo it, leading to an overly conservative policy. Moreover, they optimize all samples equally with fixed constraints, lacking the nuanced ability to control conservative levels in a fine-grained manner. Consequently, this limitation results in a performance decline. To address the above two challenges in a united way, we propose a framework, Adaptive Conservative Level in Q-Learning (ACL-QL), which limits the Q-values in a mild range and enables adaptive control on the conservative level over each state-action pair, i.e., lifting the Q-values more for good transitions and less for bad transitions. We theoretically analyze the conditions under which the conservative level of the learned Q-function can be limited in a mild range and how to optimize each transition adaptively. Motivated by the theoretical analysis, we propose a novel algorithm, ACL-QL, which uses two learnable adaptive weight functions to control the conservative level over each transition. Subsequently, we design a monotonicity loss and surrogate losses to train the adaptive weight functions, Q-function, and policy network alternatively. We evaluate ACL-QL on the commonly used D4RL benchmark and conduct extensive ablation studies to illustrate the effectiveness and state-of-the-art performance compared to existing offline DRL baselines.