 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecForge: A Flexible and Efficient Open-Source Training Framework for Speculative Decoding
Mar 19, 2026Large language models incur high inference latency due to sequential autoregressive decoding. Speculative decoding alleviates this bottleneck by using a lightweight draft model to propose multiple tokens for batched verification. However, its adoption has been limited by the lack of high-quality draft models and scalable training infrastructure. We introduce SpecForge, an open-source, production-oriented framework for training speculative decoding models with full support for EAGLE-3. SpecForge incorporates target-draft decoupling, hybrid parallelism, optimized training kernels, and integration with production-grade inference engines, enabling up to 9.9x faster EAGLE-3 training for Qwen3-235B-A22B. In addition, we release SpecBundle, a suite of production-grade EAGLE-3 draft models trained with SpecForge for mainstream open-source LLMs. Through a systematic study of speculative decoding training recipes, SpecBundle addresses the scarcity of high-quality drafts in the community, and our draft models achieve up to 4.48x end-to-end inference speedup on SGLang, establishing SpecForge as a practical foundation for real-world speculative decoding deployment.
MeshMimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction
Feb 17, 2026Humanoid motion control has witnessed significant breakthroughs in recent years, with deep reinforcement learning (RL) emerging as a primary catalyst for achieving complex, human-like behaviors. However, the high dimensionality and intricate dynamics of humanoid robots make manual motion design impractical, leading to a heavy reliance on expensive motion capture (MoCap) data. These datasets are not only costly to acquire but also frequently lack the necessary geometric context of the surrounding physical environment. Consequently, existing motion synthesis frameworks often suffer from a decoupling of motion and scene, resulting in physical inconsistencies such as contact slippage or mesh penetration during terrain-aware tasks. In this work, we present MeshMimic, an innovative framework that bridges 3D scene reconstruction and embodied intelligence to enable humanoid robots to learn coupled "motion-terrain" interactions directly from video. By leveraging state-of-the-art 3D vision models, our framework precisely segments and reconstructs both human trajectories and the underlying 3D geometry of terrains and objects. We introduce an optimization algorithm based on kinematic consistency to extract high-quality motion data from noisy visual reconstructions, alongside a contact-invariant retargeting method that transfers human-environment interaction features to the humanoid agent. Experimental results demonstrate that MeshMimic achieves robust, highly dynamic performance across diverse and challenging terrains. Our approach proves that a low-cost pipeline utilizing only consumer-grade monocular sensors can facilitate the training of complex physical interactions, offering a scalable path toward the autonomous evolution of humanoid robots in unstructured environments.
Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots
Jul 27, 2025Humanoid robot technology is advancing rapidly, with manufacturers introducing diverse heterogeneous visual perception modules tailored to specific scenarios. Among various perception paradigms, occupancy-based representation has become widely recognized as particularly suitable for humanoid robots, as it provides both rich semantic and 3D geometric information essential for comprehensive environmental understanding. In this work, we present Humanoid Occupancy, a generalized multimodal occupancy perception system that integrates hardware and software components, data acquisition devices, and a dedicated annotation pipeline. Our framework employs advanced multi-modal fusion techniques to generate grid-based occupancy outputs encoding both occupancy status and semantic labels, thereby enabling holistic environmental understanding for downstream tasks such as task planning and navigation. To address the unique challenges of humanoid robots, we overcome issues such as kinematic interference and occlusion, and establish an effective sensor layout strategy. Furthermore, we have developed the first panoramic occupancy dataset specifically for humanoid robots, offering a valuable benchmark and resource for future research and development in this domain. The network architecture incorporates multi-modal feature fusion and temporal information integration to ensure robust perception. Overall, Humanoid Occupancy delivers effective environmental perception for humanoid robots and establishes a technical foundation for standardizing universal visual modules, paving the way for the widespread deployment of humanoid robots in complex real-world scenarios.
Occupancy World Model for Robots
May 07, 2025Understanding and forecasting the scene evolutions deeply affect the exploration and decision of embodied agents. While traditional methods simulate scene evolutions through trajectory prediction of potential instances, current works use the occupancy world model as a generative framework for describing fine-grained overall scene dynamics. However, existing methods cluster on the outdoor structured road scenes, while ignoring the exploration of forecasting 3D occupancy scene evolutions for robots in indoor scenes. In this work, we explore a new framework for learning the scene evolutions of observed fine-grained occupancy and propose an occupancy world model based on the combined spatio-temporal receptive field and guided autoregressive transformer to forecast the scene evolutions, called RoboOccWorld. We propose the Conditional Causal State Attention (CCSA), which utilizes camera poses of next state as conditions to guide the autoregressive transformer to adapt and understand the indoor robotics scenarios. In order to effectively exploit the spatio-temporal cues from historical observations, Hybrid Spatio-Temporal Aggregation (HSTA) is proposed to obtain the combined spatio-temporal receptive field based on multi-scale spatio-temporal windows. In addition, we restructure the OccWorld-ScanNet benchmark based on local annotations to facilitate the evaluation of the indoor 3D occupancy scene evolution prediction task. Experimental results demonstrate that our RoboOccWorld outperforms state-of-the-art methods in indoor 3D occupancy scene evolution prediction task. The code will be released soon.
RoboOcc: Enhancing the Geometric and Semantic Scene Understanding for Robots
Apr 20, 20253D occupancy prediction enables the robots to obtain spatial fine-grained geometry and semantics of the surrounding scene, and has become an essential task for embodied perception. Existing methods based on 3D Gaussians instead of dense voxels do not effectively exploit the geometry and opacity properties of Gaussians, which limits the network's estimation of complex environments and also limits the description of the scene by 3D Gaussians. In this paper, we propose a 3D occupancy prediction method which enhances the geometric and semantic scene understanding for robots, dubbed RoboOcc. It utilizes the Opacity-guided Self-Encoder (OSE) to alleviate the semantic ambiguity of overlapping Gaussians and the Geometry-aware Cross-Encoder (GCE) to accomplish the fine-grained geometric modeling of the surrounding scene. We conduct extensive experiments on Occ-ScanNet and EmbodiedOcc-ScanNet datasets, and our RoboOcc achieves state-of the-art performance in both local and global camera settings. Further, in ablation studies of Gaussian parameters, the proposed RoboOcc outperforms the state-of-the-art methods by a large margin of (8.47, 6.27) in IoU and mIoU metric, respectively. The codes will be released soon.
VMambaCC: A Visual State Space Model for Crowd Counting
May 07, 2024As a deep learning model, Visual Mamba (VMamba) has a low computational complexity and a global receptive field, which has been successful applied to image classification and detection. To extend its applications, we apply VMamba to crowd counting and propose a novel VMambaCC (VMamba Crowd Counting) model. Naturally, VMambaCC inherits the merits of VMamba, or global modeling for images and low computational cost. Additionally, we design a Multi-head High-level Feature (MHF) attention mechanism for VMambaCC. MHF is a new attention mechanism that leverages high-level semantic features to augment low-level semantic features, thereby enhancing spatial feature representation with greater precision. Building upon MHF, we further present a High-level Semantic Supervised Feature Pyramid Network (HS2PFN) that progressively integrates and enhances high-level semantic information with low-level semantic information. Extensive experimental results on five public datasets validate the efficacy of our approach. For example, our method achieves a mean absolute error of 51.87 and a mean squared error of 81.3 on the ShangHaiTech\_PartA dataset. Our code is coming soon.
Towards V2I Age-aware Fairness Access: A DQN Based Intelligent Vehicular Node Training and Test Method
Aug 02, 2022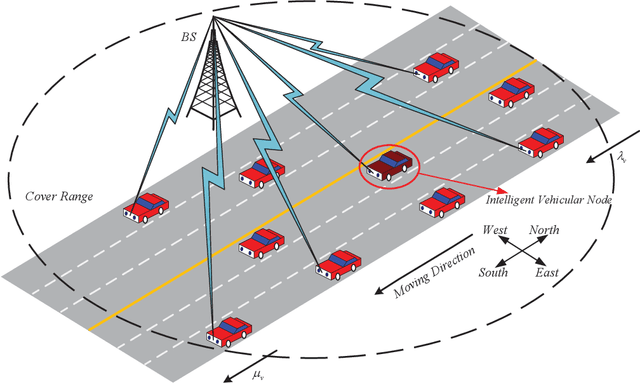
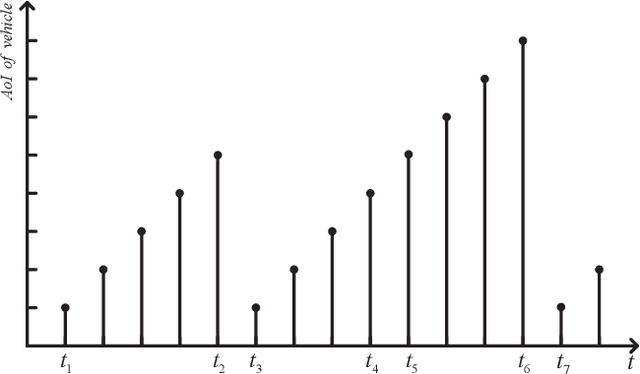
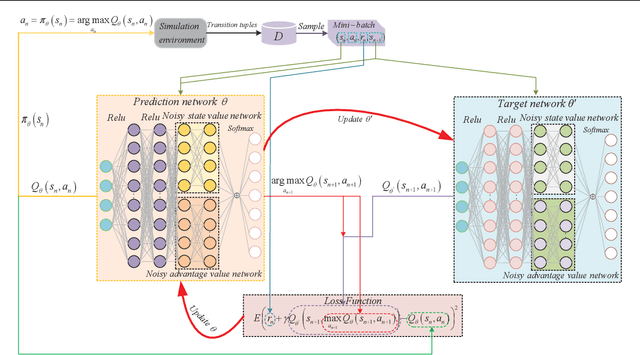
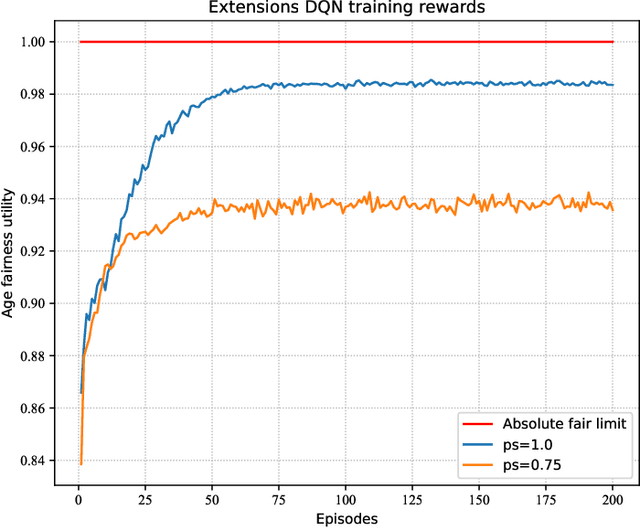
Vehicles on the road exchange data with base station (BS) frequently through vehicle to infrastructure (V2I) communications to ensure the normal use of vehicular applications, where the IEEE 802.11 distributed coordination function (DCF) is employed to allocate a minimum contention window (MCW) for channel access. Each vehicle may change its MCW to achieve more access opportunities at the expense of others, which results in unfair communication performance. Moreover, the key access parameters MCW is the privacy information and each vehicle are not willing to share it with other vehicles. In this uncertain setting, age of information (AoI) is an important communication metric to measure the freshness of data, we design an intelligent vehicular node to learn the dynamic environment and predict the optimal MCW which can make it achieve age fairness. In order to allocate the optimal MCW for the vehicular node, we employ a learning algorithm to make a desirable decision by learning from replay history data. In particular, the algorithm is proposed by extending the traditional DQN training and testing method. Finally, by comparing with other methods, it is proved that the proposed DQN method can significantly improve the age fairness of the intelligent node.
Dog nose print matching with dual global descriptor based on Contrastive Learning
Jun 01, 2022

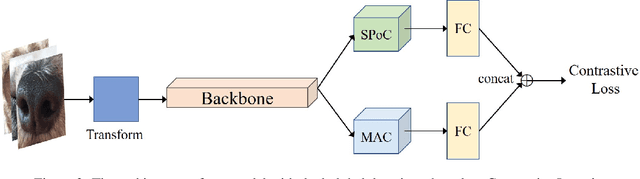

Recent studies in biometric-based identification tasks have shown that deep learning methods can achieve better performance. These methods generally extract the global features as descriptor to represent the original image. Nonetheless, it does not perform well for biometric identification under fine-grained tasks. The main reason is that the single image descriptor contains insufficient information to represent image. In this paper, we present a dual global descriptor model, which combines multiple global descriptors to exploit multi level image features. Moreover, we utilize a contrastive loss to enlarge the distance between image representations of confusing classes. The proposed framework achieves the top2 on the CVPR2022 Biometrics Workshop Pet Biometric Challenge. The source code and trained models are publicly available at: https://github.com/flyingsheepbin/pet-biometrics