 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPL: Depth-only Perceptive Humanoid Locomotion via Realistic Depth Synthesis and Cross-Attention Terrain Reconstruction
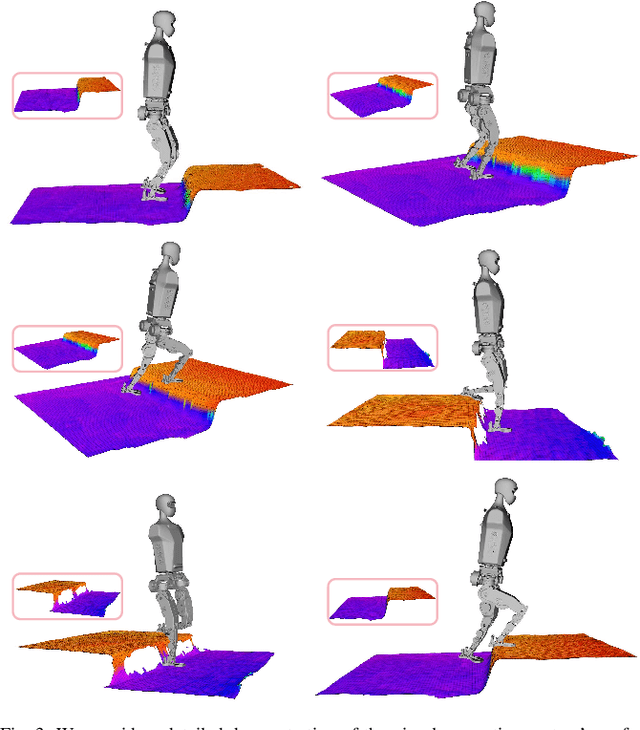
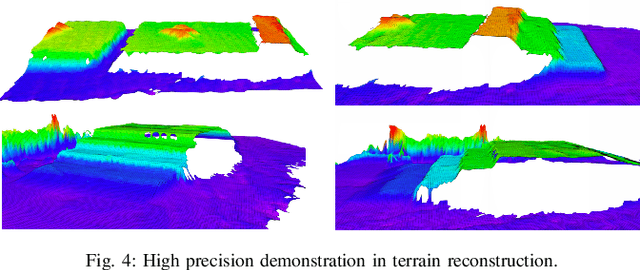
Oct 08, 2025Recent advancements in legged robot perceptive locomotion have shown promising progress. However, terrain-aware humanoid locomotion remains largely constrained to two paradigms: depth image-based end-to-end learning and elevation map-based methods. The former suffers from limited training efficiency and a significant sim-to-real gap in depth perception, while the latter depends heavily on multiple vision sensors and localization systems, resulting in latency and reduced robustness. To overcome these challenges, we propose a novel framework that tightly integrates three key components: (1) Terrain-Aware Locomotion Policy with a Blind Backbone, which leverages pre-trained elevation map-based perception to guide reinforcement learning with minimal visual input; (2) Multi-Modality Cross-Attention Transformer, which reconstructs structured terrain representations from noisy depth images; (3) Realistic Depth Images Synthetic Method, which employs self-occlusion-aware ray casting and noise-aware modeling to synthesize realistic depth observations, achieving over 30\% reduction in terrain reconstruction error. This combination enables efficient policy training with limited data and hardware resources, while preserving critical terrain features essential for generalization. We validate our framework on a full-sized humanoid robot, demonstrating agile and adaptive locomotion across diverse and challenging terrains.
Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots
Jul 27, 2025Humanoid robot technology is advancing rapidly, with manufacturers introducing diverse heterogeneous visual perception modules tailored to specific scenarios. Among various perception paradigms, occupancy-based representation has become widely recognized as particularly suitable for humanoid robots, as it provides both rich semantic and 3D geometric information essential for comprehensive environmental understanding. In this work, we present Humanoid Occupancy, a generalized multimodal occupancy perception system that integrates hardware and software components, data acquisition devices, and a dedicated annotation pipeline. Our framework employs advanced multi-modal fusion techniques to generate grid-based occupancy outputs encoding both occupancy status and semantic labels, thereby enabling holistic environmental understanding for downstream tasks such as task planning and navigation. To address the unique challenges of humanoid robots, we overcome issues such as kinematic interference and occlusion, and establish an effective sensor layout strategy. Furthermore, we have developed the first panoramic occupancy dataset specifically for humanoid robots, offering a valuable benchmark and resource for future research and development in this domain. The network architecture incorporates multi-modal feature fusion and temporal information integration to ensure robust perception. Overall, Humanoid Occupancy delivers effective environmental perception for humanoid robots and establishes a technical foundation for standardizing universal visual modules, paving the way for the widespread deployment of humanoid robots in complex real-world scenarios.
Occupancy World Model for Robots
May 07, 2025Understanding and forecasting the scene evolutions deeply affect the exploration and decision of embodied agents. While traditional methods simulate scene evolutions through trajectory prediction of potential instances, current works use the occupancy world model as a generative framework for describing fine-grained overall scene dynamics. However, existing methods cluster on the outdoor structured road scenes, while ignoring the exploration of forecasting 3D occupancy scene evolutions for robots in indoor scenes. In this work, we explore a new framework for learning the scene evolutions of observed fine-grained occupancy and propose an occupancy world model based on the combined spatio-temporal receptive field and guided autoregressive transformer to forecast the scene evolutions, called RoboOccWorld. We propose the Conditional Causal State Attention (CCSA), which utilizes camera poses of next state as conditions to guide the autoregressive transformer to adapt and understand the indoor robotics scenarios. In order to effectively exploit the spatio-temporal cues from historical observations, Hybrid Spatio-Temporal Aggregation (HSTA) is proposed to obtain the combined spatio-temporal receptive field based on multi-scale spatio-temporal windows. In addition, we restructure the OccWorld-ScanNet benchmark based on local annotations to facilitate the evaluation of the indoor 3D occupancy scene evolution prediction task. Experimental results demonstrate that our RoboOccWorld outperforms state-of-the-art methods in indoor 3D occupancy scene evolution prediction task. The code will be released soon.
RoboOcc: Enhancing the Geometric and Semantic Scene Understanding for Robots
Apr 20, 20253D occupancy prediction enables the robots to obtain spatial fine-grained geometry and semantics of the surrounding scene, and has become an essential task for embodied perception. Existing methods based on 3D Gaussians instead of dense voxels do not effectively exploit the geometry and opacity properties of Gaussians, which limits the network's estimation of complex environments and also limits the description of the scene by 3D Gaussians. In this paper, we propose a 3D occupancy prediction method which enhances the geometric and semantic scene understanding for robots, dubbed RoboOcc. It utilizes the Opacity-guided Self-Encoder (OSE) to alleviate the semantic ambiguity of overlapping Gaussians and the Geometry-aware Cross-Encoder (GCE) to accomplish the fine-grained geometric modeling of the surrounding scene. We conduct extensive experiments on Occ-ScanNet and EmbodiedOcc-ScanNet datasets, and our RoboOcc achieves state-of the-art performance in both local and global camera settings. Further, in ablation studies of Gaussian parameters, the proposed RoboOcc outperforms the state-of-the-art methods by a large margin of (8.47, 6.27) in IoU and mIoU metric, respectively. The codes will be released soon.
HumanoidPano: Hybrid Spherical Panoramic-LiDAR Cross-Modal Perception for Humanoid Robots
Mar 13, 2025The perceptual system design for humanoid robots poses unique challenges due to inherent structural constraints that cause severe self-occlusion and limited field-of-view (FOV). We present HumanoidPano, a novel hybrid cross-modal perception framework that synergistically integrates panoramic vision and LiDAR sensing to overcome these limitations. Unlike conventional robot perception systems that rely on monocular cameras or standard multi-sensor configurations, our method establishes geometrically-aware modality alignment through a spherical vision transformer, enabling seamless fusion of 360 visual context with LiDAR's precise depth measurements. First, Spherical Geometry-aware Constraints (SGC) leverage panoramic camera ray properties to guide distortion-regularized sampling offsets for geometric alignment. Second, Spatial Deformable Attention (SDA) aggregates hierarchical 3D features via spherical offsets, enabling efficient 360{\deg}-to-BEV fusion with geometrically complete object representations. Third, Panoramic Augmentation (AUG) combines cross-view transformations and semantic alignment to enhance BEV-panoramic feature consistency during data augmentation. Extensive evaluations demonstrate state-of-the-art performance on the 360BEV-Matterport benchmark. Real-world deployment on humanoid platforms validates the system's capability to generate accurate BEV segmentation maps through panoramic-LiDAR co-perception, directly enabling downstream navigation tasks in complex environments. Our work establishes a new paradigm for embodied perception in humanoid robotics.
ES-Parkour: Advanced Robot Parkour with Bio-inspired Event Camera and Spiking Neural Network
Mar 13, 2025In recent years, quadruped robotics has advanced significantly, particularly in perception and motion control via reinforcement learning, enabling complex motions in challenging environments. Visual sensors like depth cameras enhance stability and robustness but face limitations, such as low operating frequencies relative to joint control and sensitivity to lighting, which hinder outdoor deployment. Additionally, deep neural networks in sensor and control systems increase computational demands. To address these issues, we introduce spiking neural networks (SNNs) and event cameras to perform a challenging quadruped parkour task. Event cameras capture dynamic visual data, while SNNs efficiently process spike sequences, mimicking biological perception. Experimental results demonstrate that this approach significantly outperforms traditional models, achieving excellent parkour performance with just 11.7% of the energy consumption of an artificial neural network (ANN)-based model, yielding an 88.3% energy reduction. By integrating event cameras with SNNs, our work advances robotic reinforcement learning and opens new possibilities for applications in demanding environments.
Trinity: A Modular Humanoid Robot AI System
Mar 11, 2025In recent years, research on humanoid robots has garnered increasing attention. With breakthroughs in various types of artificial intelligence algorithms, embodied intelligence, exemplified by humanoid robots, has been highly anticipated. The advancements in reinforcement learning (RL) algorithms have significantly improved the motion control and generalization capabilities of humanoid robots. Simultaneously, the groundbreaking progress in large language models (LLM) and visual language models (VLM) has brought more possibilities and imagination to humanoid robots. LLM enables humanoid robots to understand complex tasks from language instructions and perform long-term task planning, while VLM greatly enhances the robots' understanding and interaction with their environment. This paper introduces \textcolor{magenta}{Trinity}, a novel AI system for humanoid robots that integrates RL, LLM, and VLM. By combining these technologies, Trinity enables efficient control of humanoid robots in complex environments. This innovative approach not only enhances the capabilities but also opens new avenues for future research and applications of humanoid robotics.
Distillation-PPO: A Novel Two-Stage Reinforcement Learning Framework for Humanoid Robot Perceptive Locomotion
Mar 11, 2025
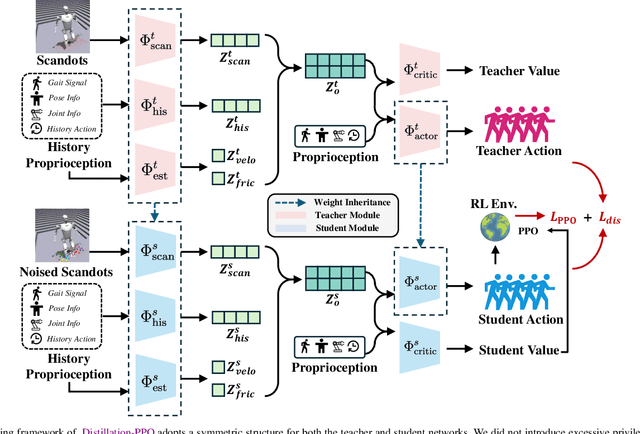
In recent years, humanoid robots have garnered significant attention from both academia and industry due to their high adaptability to environments and human-like characteristics. With the rapid advancement of reinforcement learning, substantial progress has been made in the walking control of humanoid robots. However, existing methods still face challenges when dealing with complex environments and irregular terrains. In the field of perceptive locomotion, existing approaches are generally divided into two-stage methods and end-to-end methods. Two-stage methods first train a teacher policy in a simulated environment and then use distillation techniques, such as DAgger, to transfer the privileged information learned as latent features or actions to the student policy. End-to-end methods, on the other hand, forgo the learning of privileged information and directly learn policies from a partially observable Markov decision process (POMDP) through reinforcement learning. However, due to the lack of supervision from a teacher policy, end-to-end methods often face difficulties in training and exhibit unstable performance in real-world applications. This paper proposes an innovative two-stage perceptive locomotion framework that combines the advantages of teacher policies learned in a fully observable Markov decision process (MDP) to regularize and supervise the student policy. At the same time, it leverages the characteristics of reinforcement learning to ensure that the student policy can continue to learn in a POMDP, thereby enhancing the model's upper bound. Our experimental results demonstrate that our two-stage training framework achieves higher training efficiency and stability in simulated environments, while also exhibiting better robustness and generalization capabilities in real-world applications.
LiPS: Large-Scale Humanoid Robot Reinforcement Learning with Parallel-Series Structures
Mar 11, 2025In recent years, research on humanoid robots has garnered significant attention, particularly in reinforcement learning based control algorithms, which have achieved major breakthroughs. Compared to traditional model-based control algorithms, reinforcement learning based algorithms demonstrate substantial advantages in handling complex tasks. Leveraging the large-scale parallel computing capabilities of GPUs, contemporary humanoid robots can undergo extensive parallel training in simulated environments. A physical simulation platform capable of large-scale parallel training is crucial for the development of humanoid robots. As one of the most complex robot forms, humanoid robots typically possess intricate mechanical structures, encompassing numerous series and parallel mechanisms. However, many reinforcement learning based humanoid robot control algorithms currently employ open-loop topologies during training, deferring the conversion to series-parallel structures until the sim2real phase. This approach is primarily due to the limitations of physics engines, as current GPU-based physics engines often only support open-loop topologies or have limited capabilities in simulating multi-rigid-body closed-loop topologies. For enabling reinforcement learning-based humanoid robot control algorithms to train in large-scale parallel environments, we propose a novel training method LiPS. By incorporating multi-rigid-body dynamics modeling in the simulation environment, we significantly reduce the sim2real gap and the difficulty of converting to parallel structures during model deployment, thereby robustly supporting large-scale reinforcement learning for humanoid robots.
E2H: A Two-Stage Non-Invasive Neural Signal Driven Humanoid Robotic Whole-Body Control Framework
Oct 03, 2024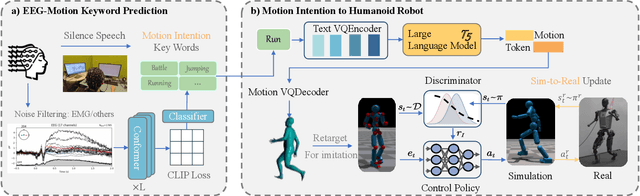

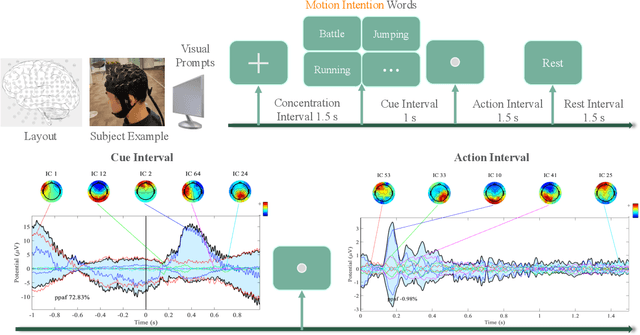
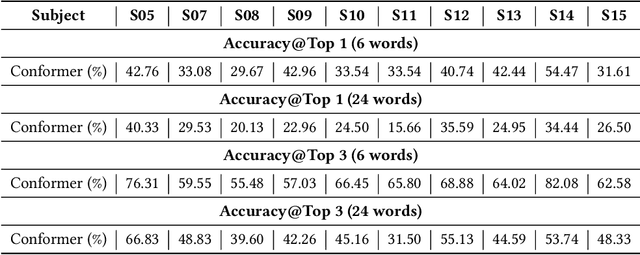
Recent advancements in humanoid robotics, including the integration of hierarchical reinforcement learning-based control and the utilization of LLM planning, have significantly enhanced the ability of robots to perform complex tasks. In contrast to the highly developed humanoid robots, the human factors involved remain relatively unexplored. Directly controlling humanoid robots with the brain has already appeared in many science fiction novels, such as Pacific Rim and Gundam. In this work, we present E2H (EEG-to-Humanoid), an innovative framework that pioneers the control of humanoid robots using high-frequency non-invasive neural signals. As the none-invasive signal quality remains low in decoding precise spatial trajectory, we decompose the E2H framework in an innovative two-stage formation: 1) decoding neural signals (EEG) into semantic motion keywords, 2) utilizing LLM facilitated motion generation with a precise motion imitation control policy to realize humanoid robotics control. The method of directly driving robots with brainwave commands offers a novel approach to human-machine collaboration, especially in situations where verbal commands are impractical, such as in cases of speech impairments, space exploration, or underwater exploration, unlocking significant potential. E2H offers an exciting glimpse into the future, holding immense potential for human-computer interaction.