 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba Policy: Towards Efficient 3D Diffusion Policy with Hybrid Selective State Models
Sep 11, 2024



Diffusion models have been widely employed in the field of 3D manipulation due to their efficient capability to learn distributions, allowing for precise prediction of action trajectories. However, diffusion models typically rely on large parameter UNet backbones as policy networks, which can be challenging to deploy on resource-constrained devices. Recently, the Mamba model has emerged as a promising solution for efficient modeling, offering low computational complexity and strong performance in sequence modeling. In this work, we propose the Mamba Policy, a lighter but stronger policy that reduces the parameter count by over 80% compared to the original policy network while achieving superior performance. Specifically, we introduce the XMamba Block, which effectively integrates input information with conditional features and leverages a combination of Mamba and Attention mechanisms for deep feature extraction. Extensive experiments demonstrate that the Mamba Policy excels on the Adroit, Dexart, and MetaWorld datasets, requiring significantly fewer computational resources. Additionally, we highlight the Mamba Policy's enhanced robustness in long-horizon scenarios compared to baseline methods and explore the performance of various Mamba variants within the Mamba Policy framework. Our project page is in https://andycao1125.github.io/mamba_policy/.
Mamba as Decision Maker: Exploring Multi-scale Sequence Modeling in Offline Reinforcement Learning
Jun 04, 2024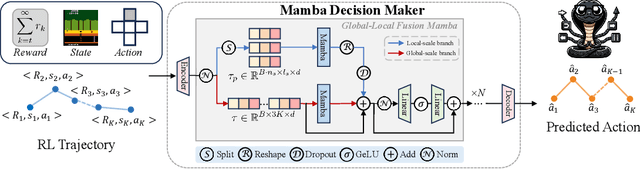
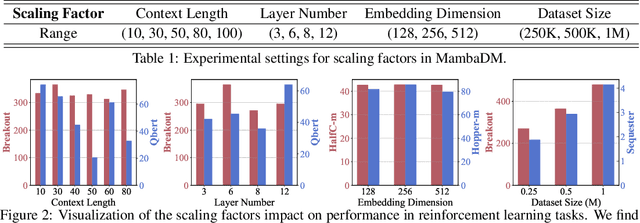

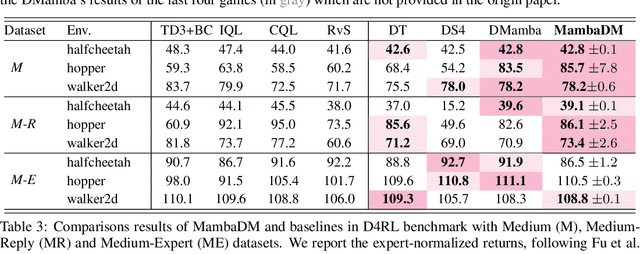
Sequential modeling has demonstrated remarkable capabilities in offline reinforcement learning (RL), with Decision Transformer (DT) being one of the most notable representatives, achieving significant success. However, RL trajectories possess unique properties to be distinguished from the conventional sequence (e.g., text or audio): (1) local correlation, where the next states in RL are theoretically determined solely by current states and actions based on the Markov Decision Process (MDP), and (2) global correlation, where each step's features are related to long-term historical information due to the time-continuous nature of trajectories. In this paper, we propose a novel action sequence predictor, named Mamba Decision Maker (MambaDM), where Mamba is expected to be a promising alternative for sequence modeling paradigms, owing to its efficient modeling of multi-scale dependencies. In particular, we introduce a novel mixer module that proficiently extracts and integrates both global and local features of the input sequence, effectively capturing interrelationships in RL datasets. Extensive experiments demonstrate that MambaDM achieves state-of-the-art performance in Atari and OpenAI Gym datasets. Furthermore, we empirically investigate the scaling laws of MambaDM, finding that increasing model size does not bring performance improvement, but scaling the dataset amount by 2x for MambaDM can obtain up to 33.7% score improvement on Atari dataset. This paper delves into the sequence modeling capabilities of MambaDM in the RL domain, paving the way for future advancements in robust and efficient decision-making systems. Our code will be available at https://github.com/AndyCao1125/MambaDM.
Learning Free Gait Transition for Quadruped Robots via Phase-Guided Controller
Jan 01, 2022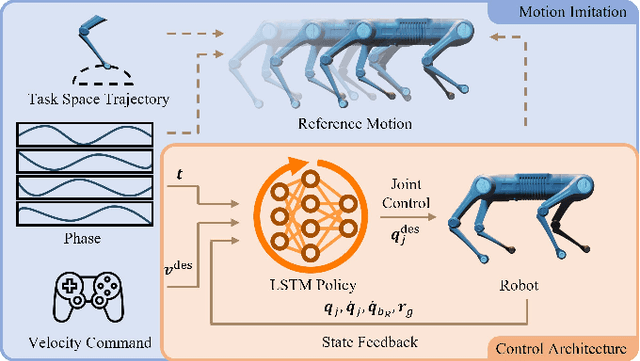

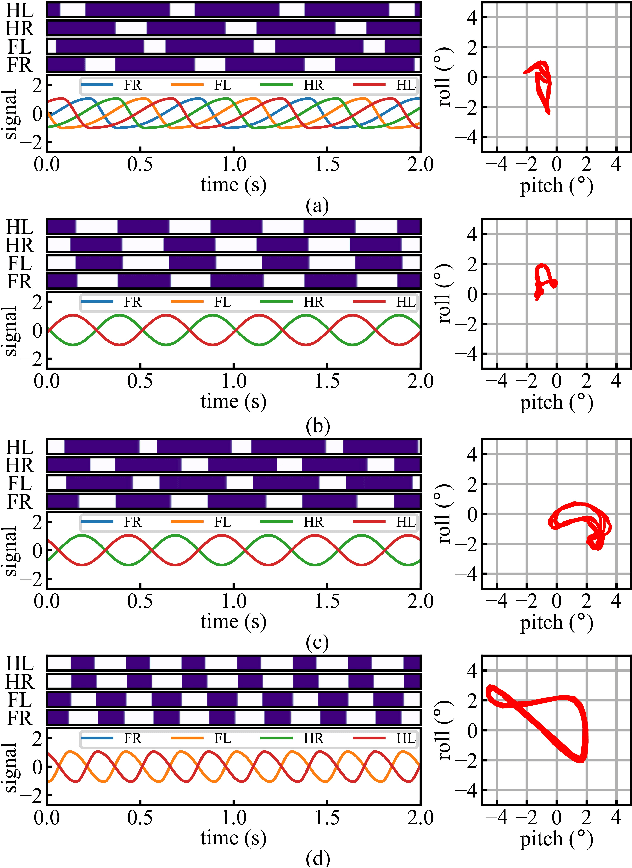
Gaits and transitions are key components in legged locomotion. For legged robots, describing and reproducing gaits as well as transitions remain longstanding challenges. Reinforcement learning has become a powerful tool to formulate controllers for legged robots. Learning multiple gaits and transitions, nevertheless, is related to the multi-task learning problems. In this work, we present a novel framework for training a simple control policy for a quadruped robot to locomote in various gaits. Four independent phases are used as the interface between the gait generator and the control policy, which characterizes the movement of four feet. Guided by the phases, the quadruped robot is able to locomote according to the generated gaits, such as walk, trot, pacing and bounding, and to make transitions among those gaits. More general phases can be used to generate complex gaits, such as mixed rhythmic dancing. With the control policy, the Black Panther robot, a medium-dog-sized quadruped robot, can perform all learned motor skills while following the velocity commands smoothly and robustly in natural environment.