 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting and Enhancing Emotional Circuits in Large Vision-Language Models via Cross-Modal Information Flow
May 21, 2026Large Vision-Language Models (LVLMs) represent a significant leap towards empathetic agents, demonstrating remarkable capabilities in emotion understanding. However, the internal mechanisms governing how LVLMs translate abstract visual stimuli into coherent emotional narratives remain largely unexplored, primarily due to the scarcity of visual counterfactuals and the diffuse nature of emotional expression. In this paper, we bridge this gap by introducing a steering-vector-based causal attribution framework tailored for descriptive emotional reasoning. To this end, we construct a specialized dataset to demystify the emotional circuits underlying the three-stage ``Adapt-Aggregate-Execute'' mechanism. Crucially, we discover a functional decoupling: visual emotional cues are aggregated in middle layers via sentiment-specific attention heads, but are subsequently translated into narrative generation in deep layers through emotion-general pathways. Guided by these insights, we regulate the emotional information routing to strengthen attention flow and amplify the semantic activation to consolidate expression. Extensive experiments on the comprehensive MER-UniBench demonstrate that our methods significantly improve performance via inference-time intervention, effectively mitigating emotional hallucinations and corroborating the causal fidelity of the discovered circuits.
Prefill-Time Intervention for Mitigating Hallucination in Large Vision-Language Models
Apr 28, 2026Large Vision-Language Models (LVLMs) have achieved remarkable progress in visual-textual understanding, yet their reliability is critically undermined by hallucinations, i.e., the generation of factually incorrect or inconsistent responses. While recent studies using steering vectors demonstrated promise in reducing hallucinations, a notable challenge remains: they inadvertently amplify the severity of residual hallucinations. We attribute this to their exclusive focus on the decoding stage, where errors accumulate autoregressively and progressively worsen subsequent hallucinatory outputs. To address this, we propose Prefill-Time Intervention (PTI), a novel steering paradigm that intervenes only once during the prefill stage, enhancing the initial Key-Value (KV) cache before error accumulation occurs. Specifically, PTI is modality-aware, deriving distinct directions for visual and textual representations. This intervention is decoupled to steer keys toward visually-grounded objects and values to filter background noise, correcting hallucination-prone representations at their source. Extensive experiments demonstrate PTI's significant performance in mitigating hallucinations and its generalizability across diverse decoding strategies, LVLMs, and benchmarks. Moreover, PTI is orthogonal to existing decoding-stage methods, enabling plug-and-play integration and further boosting performance. Code is available at: https://github.com/huaiyi66/PTI.
Weight Patching: Toward Source-Level Mechanistic Localization in LLMs
Apr 15, 2026Mechanistic interpretability seeks to localize model behavior to the internal components that causally realize it. Prior work has advanced activation-space localization and causal tracing, but modules that appear important in activation space may merely aggregate or amplify upstream signals rather than encode the target capability in their own parameters. To address this gap, we propose Weight Patching, a parameter-space intervention method for source-oriented analysis in paired same-architecture models that differ in how strongly they express a target capability under the inputs of interest. Given a base model and a behavior-specialized counterpart, Weight Patching replaces selected module weights from the specialized model into the base model under a fixed input. We instantiate the method on instruction following and introduce a framework centered on a vector-anchor behavioral interface that provides a shared internal criterion for whether a task-relevant control state has been formed or recovered in open-ended generation. Under this framework, the analysis reveals a hierarchy from shallow candidate source-side carriers to aggregation and routing modules, and further to downstream execution circuits. The recovered component scores can also guide mechanism-aware model merging, improving selective fusion across the evaluated expert combinations and providing additional external validation.
Beyond Quantity: Trajectory Diversity Scaling for Code Agents
Feb 03, 2026As code large language models (LLMs) evolve into tool-interactive agents via the Model Context Protocol (MCP), their generalization is increasingly limited by low-quality synthetic data and the diminishing returns of quantity scaling. Moreover, quantity-centric scaling exhibits an early bottleneck that underutilizes trajectory data. We propose TDScaling, a Trajectory Diversity Scaling-based data synthesis framework for code agents that scales performance through diversity rather than raw volume. Under a fixed training budget, increasing trajectory diversity yields larger gains than adding more trajectories, improving the performance-cost trade-off for agent training. TDScaling integrates four innovations: (1) a Business Cluster mechanism that captures real-service logical dependencies; (2) a blueprint-driven multi-agent paradigm that enforces trajectory coherence; (3) an adaptive evolution mechanism that steers synthesis toward long-tail scenarios using Domain Entropy, Reasoning Mode Entropy, and Cumulative Action Complexity to prevent mode collapse; and (4) a sandboxed code tool that mitigates catastrophic forgetting of intrinsic coding capabilities. Experiments on general tool-use benchmarks (BFCL, tau^2-Bench) and code agent tasks (RebenchT, CodeCI, BIRD) demonstrate a win-win outcome: TDScaling improves both tool-use generalization and inherent coding proficiency. We plan to release the full codebase and the synthesized dataset (including 30,000+ tool clusters) upon publication.
UNSEEN: Enhancing Dataset Pruning from a Generalization Perspective
Nov 18, 2025



The growing scale of datasets in deep learning has introduced significant computational challenges. Dataset pruning addresses this challenge by constructing a compact but informative coreset from the full dataset with comparable performance. Previous approaches typically establish scoring metrics based on specific criteria to identify representative samples. However, these methods predominantly rely on sample scores obtained from the model's performance during the training (i.e., fitting) phase. As scoring models achieve near-optimal performance on training data, such fitting-centric approaches induce a dense distribution of sample scores within a narrow numerical range. This concentration reduces the distinction between samples and hinders effective selection. To address this challenge, we conduct dataset pruning from the perspective of generalization, i.e., scoring samples based on models not exposed to them during training. We propose a plug-and-play framework, UNSEEN, which can be integrated into existing dataset pruning methods. Additionally, conventional score-based methods are single-step and rely on models trained solely on the complete dataset, providing limited perspective on the importance of samples. To address this limitation, we scale UNSEEN to multi-step scenarios and propose an incremental selection technique through scoring models trained on varying coresets, and optimize the quality of the coreset dynamically. Extensive experiments demonstrate that our method significantly outperforms existing state-of-the-art (SOTA) methods on CIFAR-10, CIFAR-100, and ImageNet-1K. Notably, on ImageNet-1K, UNSEEN achieves lossless performance while reducing training data by 30\%.
HumanoidPano: Hybrid Spherical Panoramic-LiDAR Cross-Modal Perception for Humanoid Robots
Mar 13, 2025The perceptual system design for humanoid robots poses unique challenges due to inherent structural constraints that cause severe self-occlusion and limited field-of-view (FOV). We present HumanoidPano, a novel hybrid cross-modal perception framework that synergistically integrates panoramic vision and LiDAR sensing to overcome these limitations. Unlike conventional robot perception systems that rely on monocular cameras or standard multi-sensor configurations, our method establishes geometrically-aware modality alignment through a spherical vision transformer, enabling seamless fusion of 360 visual context with LiDAR's precise depth measurements. First, Spherical Geometry-aware Constraints (SGC) leverage panoramic camera ray properties to guide distortion-regularized sampling offsets for geometric alignment. Second, Spatial Deformable Attention (SDA) aggregates hierarchical 3D features via spherical offsets, enabling efficient 360{\deg}-to-BEV fusion with geometrically complete object representations. Third, Panoramic Augmentation (AUG) combines cross-view transformations and semantic alignment to enhance BEV-panoramic feature consistency during data augmentation. Extensive evaluations demonstrate state-of-the-art performance on the 360BEV-Matterport benchmark. Real-world deployment on humanoid platforms validates the system's capability to generate accurate BEV segmentation maps through panoramic-LiDAR co-perception, directly enabling downstream navigation tasks in complex environments. Our work establishes a new paradigm for embodied perception in humanoid robotics.
Distillation-PPO: A Novel Two-Stage Reinforcement Learning Framework for Humanoid Robot Perceptive Locomotion
Mar 11, 2025
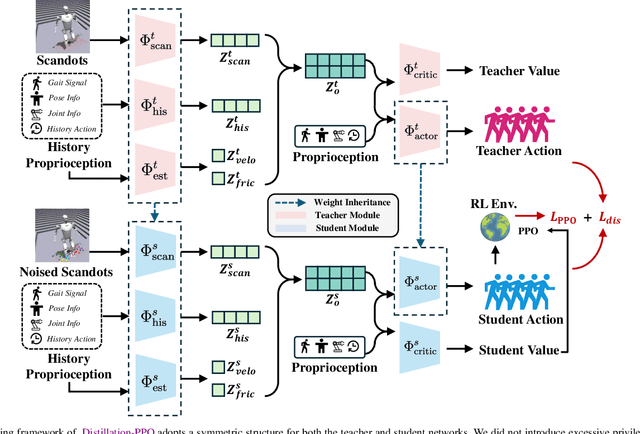
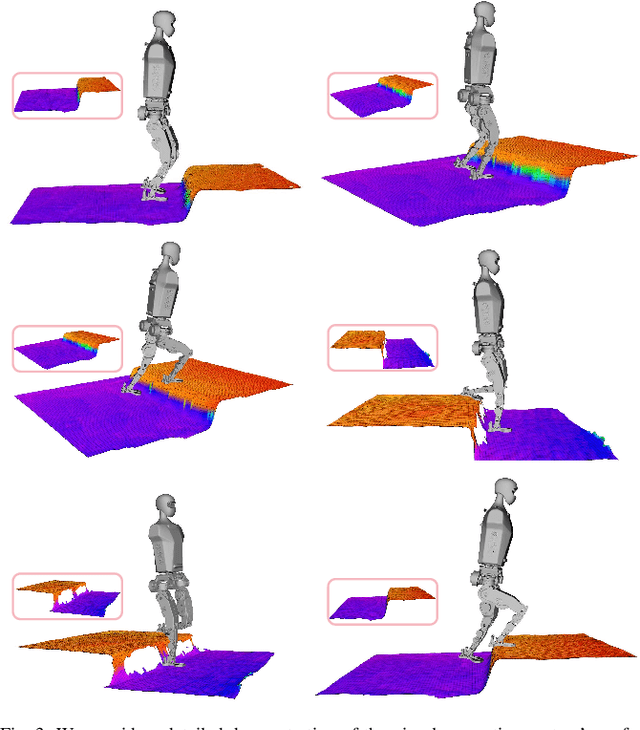
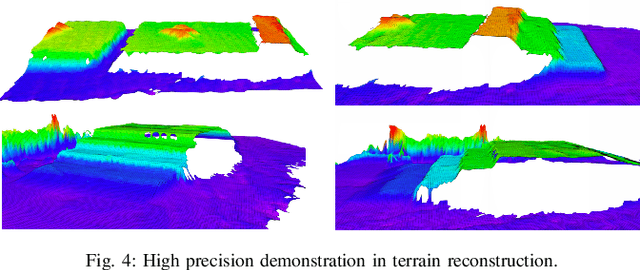
In recent years, humanoid robots have garnered significant attention from both academia and industry due to their high adaptability to environments and human-like characteristics. With the rapid advancement of reinforcement learning, substantial progress has been made in the walking control of humanoid robots. However, existing methods still face challenges when dealing with complex environments and irregular terrains. In the field of perceptive locomotion, existing approaches are generally divided into two-stage methods and end-to-end methods. Two-stage methods first train a teacher policy in a simulated environment and then use distillation techniques, such as DAgger, to transfer the privileged information learned as latent features or actions to the student policy. End-to-end methods, on the other hand, forgo the learning of privileged information and directly learn policies from a partially observable Markov decision process (POMDP) through reinforcement learning. However, due to the lack of supervision from a teacher policy, end-to-end methods often face difficulties in training and exhibit unstable performance in real-world applications. This paper proposes an innovative two-stage perceptive locomotion framework that combines the advantages of teacher policies learned in a fully observable Markov decision process (MDP) to regularize and supervise the student policy. At the same time, it leverages the characteristics of reinforcement learning to ensure that the student policy can continue to learn in a POMDP, thereby enhancing the model's upper bound. Our experimental results demonstrate that our two-stage training framework achieves higher training efficiency and stability in simulated environments, while also exhibiting better robustness and generalization capabilities in real-world applications.
Dataset Distillation with Neural Characteristic Function: A Minmax Perspective
Feb 28, 2025Dataset distillation has emerged as a powerful approach for reducing data requirements in deep learning. Among various methods, distribution matching-based approaches stand out for their balance of computational efficiency and strong performance. However, existing distance metrics used in distribution matching often fail to accurately capture distributional differences, leading to unreliable measures of discrepancy. In this paper, we reformulate dataset distillation as a minmax optimization problem and introduce Neural Characteristic Function Discrepancy (NCFD), a comprehensive and theoretically grounded metric for measuring distributional differences. NCFD leverages the Characteristic Function (CF) to encapsulate full distributional information, employing a neural network to optimize the sampling strategy for the CF's frequency arguments, thereby maximizing the discrepancy to enhance distance estimation. Simultaneously, we minimize the difference between real and synthetic data under this optimized NCFD measure. Our approach, termed Neural Characteristic Function Matching (\mymethod{}), inherently aligns the phase and amplitude of neural features in the complex plane for both real and synthetic data, achieving a balance between realism and diversity in synthetic samples. Experiments demonstrate that our method achieves significant performance gains over state-of-the-art methods on both low- and high-resolution datasets. Notably, we achieve a 20.5\% accuracy boost on ImageSquawk. Our method also reduces GPU memory usage by over 300$\times$ and achieves 20$\times$ faster processing speeds compared to state-of-the-art methods. To the best of our knowledge, this is the first work to achieve lossless compression of CIFAR-100 on a single NVIDIA 2080 Ti GPU using only 2.3 GB of memory.
* Accepted by CVPR 2025, 11 pages, 7 figures
DRUPI: Dataset Reduction Using Privileged Information
Oct 02, 2024



Dataset reduction (DR) seeks to select or distill samples from large datasets into smaller subsets while preserving performance on target tasks. Existing methods primarily focus on pruning or synthesizing data in the same format as the original dataset, typically the input data and corresponding labels. However, in DR settings, we find it is possible to synthesize more information beyond the data-label pair as an additional learning target to facilitate model training. In this paper, we introduce Dataset Reduction Using Privileged Information (DRUPI), which enriches DR by synthesizing privileged information alongside the reduced dataset. This privileged information can take the form of feature labels or attention labels, providing auxiliary supervision to improve model learning. Our findings reveal that effective feature labels must balance between being overly discriminative and excessively diverse, with a moderate level proving optimal for improving the reduced dataset's efficacy. Extensive experiments on ImageNet, CIFAR-10/100, and Tiny ImageNet demonstrate that DRUPI integrates seamlessly with existing dataset reduction methods, offering significant performance gains.
Towards Lightweight Black-Box Attacks against Deep Neural Networks
Oct 11, 2022

Black-box attacks can generate adversarial examples without accessing the parameters of target model, largely exacerbating the threats of deployed deep neural networks (DNNs). However, previous works state that black-box attacks fail to mislead target models when their training data and outputs are inaccessible. In this work, we argue that black-box attacks can pose practical attacks in this extremely restrictive scenario where only several test samples are available. Specifically, we find that attacking the shallow layers of DNNs trained on a few test samples can generate powerful adversarial examples. As only a few samples are required, we refer to these attacks as lightweight black-box attacks. The main challenge to promoting lightweight attacks is to mitigate the adverse impact caused by the approximation error of shallow layers. As it is hard to mitigate the approximation error with few available samples, we propose Error TransFormer (ETF) for lightweight attacks. Namely, ETF transforms the approximation error in the parameter space into a perturbation in the feature space and alleviates the error by disturbing features. In experiments, lightweight black-box attacks with the proposed ETF achieve surprising results. For example, even if only 1 sample per category available, the attack success rate in lightweight black-box attacks is only about 3% lower than that of the black-box attacks with complete training data.