 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillation-PPO: A Novel Two-Stage Reinforcement Learning Framework for Humanoid Robot Perceptive Locomotion
Paper and Code
Mar 11, 2025
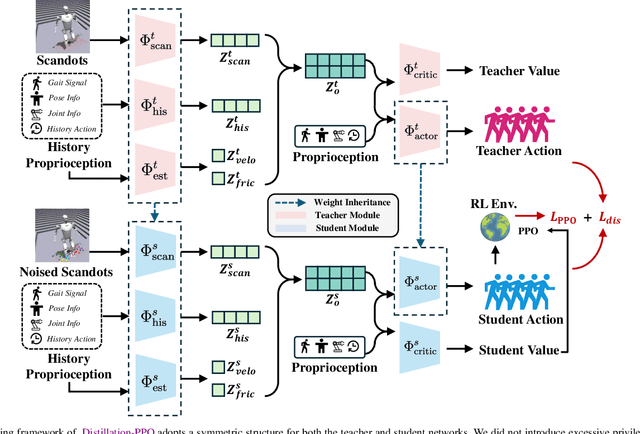
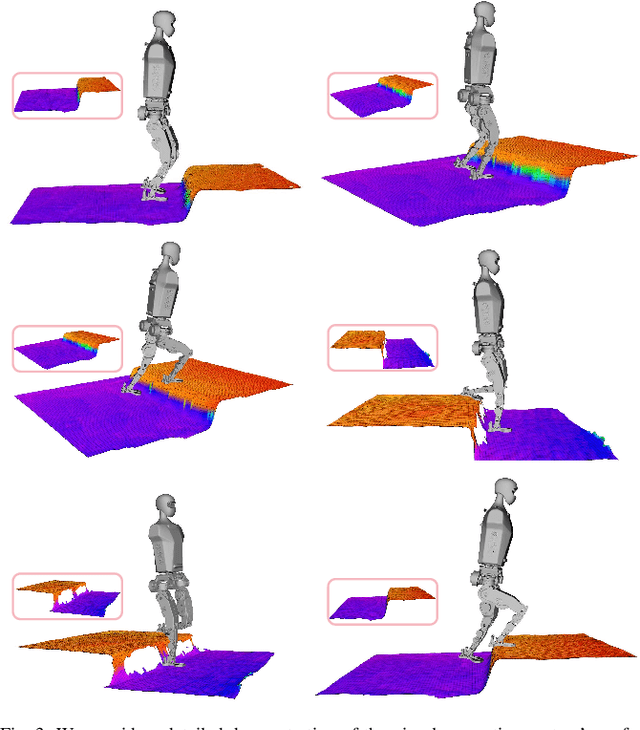
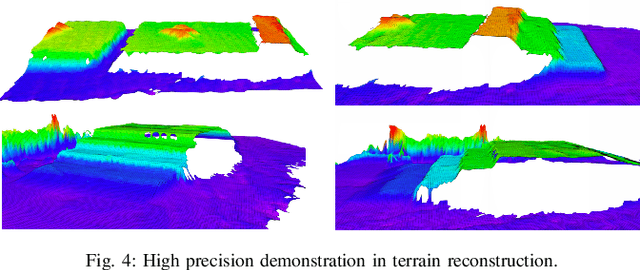
In recent years, humanoid robots have garnered significant attention from both academia and industry due to their high adaptability to environments and human-like characteristics. With the rapid advancement of reinforcement learning, substantial progress has been made in the walking control of humanoid robots. However, existing methods still face challenges when dealing with complex environments and irregular terrains. In the field of perceptive locomotion, existing approaches are generally divided into two-stage methods and end-to-end methods. Two-stage methods first train a teacher policy in a simulated environment and then use distillation techniques, such as DAgger, to transfer the privileged information learned as latent features or actions to the student policy. End-to-end methods, on the other hand, forgo the learning of privileged information and directly learn policies from a partially observable Markov decision process (POMDP) through reinforcement learning. However, due to the lack of supervision from a teacher policy, end-to-end methods often face difficulties in training and exhibit unstable performance in real-world applications. This paper proposes an innovative two-stage perceptive locomotion framework that combines the advantages of teacher policies learned in a fully observable Markov decision process (MDP) to regularize and supervise the student policy. At the same time, it leverages the characteristics of reinforcement learning to ensure that the student policy can continue to learn in a POMDP, thereby enhancing the model's upper bound. Our experimental results demonstrate that our two-stage training framework achieves higher training efficiency and stability in simulated environments, while also exhibiting better robustness and generalization capabilities in real-world applications.