 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny3DAvatar: Fast and High-Quality Full-Head 3D Avatar Reconstruction from Single Portrait Image
Apr 15, 2026Reconstructing a complete 3D head from a single portrait remains challenging because existing methods still face a sharp quality-speed trade-off: high-fidelity pipelines often rely on multi-stage processing and per-subject optimization, while fast feed-forward models struggle with complete geometry and fine appearance details. To bridge this gap, we propose Any3DAvatar, a fast and high-quality method for single-image 3D Gaussian head avatar generation, whose fastest setting reconstructs a full head in under one second while preserving high-fidelity geometry and texture. First, we build AnyHead, a unified data suite that combines identity diversity, dense multi-view supervision, and realistic accessories, filling the main gaps of existing head data in coverage, full-head geometry, and complex appearance. Second, rather than sampling unstructured noise, we initialize from a Plücker-aware structured 3D Gaussian scaffold and perform one-step conditional denoising, formulating full-head reconstruction into a single forward pass while retaining high fidelity. Third, we introduce auxiliary view-conditioned appearance supervision on the same latent tokens alongside 3D Gaussian reconstruction, improving novel-view texture details at zero extra inference cost. Experiments show that Any3DAvatar outperforms prior single-image full-head reconstruction methods in rendering fidelity while remaining substantially faster.
VehicleMemBench: An Executable Benchmark for Multi-User Long-Term Memory in In-Vehicle Agents
Mar 25, 2026With the growing demand for intelligent in-vehicle experiences, vehicle-based agents are evolving from simple assistants to long-term companions. This evolution requires agents to continuously model multi-user preferences and make reliable decisions in the face of inter-user preference conflicts and changing habits over time. However, existing benchmarks are largely limited to single-user, static question-answer settings, failing to capture the temporal evolution of preferences and the multi-user, tool-interactive nature of real vehicle environments. To address this gap, we introduce VehicleMemBench, a multi-user long-context memory benchmark built on an executable in-vehicle simulation environment. The benchmark evaluates tool use and memory by comparing the post-action environment state with a predefined target state, enabling objective and reproducible evaluation without LLM-based or human scoring. VehicleMemBench includes 23 tool modules, and each sample contains over 80 historical memory events. Experiments show that powerful models perform well on direct instruction tasks but struggle in scenarios involving memory evolution, particularly when user preferences change dynamically. Even advanced memory systems struggle to handle domain-specific memory requirements in this environment. These findings highlight the need for more robust and specialized memory management mechanisms to support long-term adaptive decision-making in real-world in-vehicle systems. To facilitate future research, we release the data and code.
The Renaissance of Expert Systems: Optical Recognition of Printed Chinese Jianpu Musical Scores with Lyrics
Dec 15, 2025Large-scale optical music recognition (OMR) research has focused mainly on Western staff notation, leaving Chinese Jianpu (numbered notation) and its rich lyric resources underexplored. We present a modular expert-system pipeline that converts printed Jianpu scores with lyrics into machine-readable MusicXML and MIDI, without requiring massive annotated training data. Our approach adopts a top-down expert-system design, leveraging traditional computer-vision techniques (e.g., phrase correlation, skeleton analysis) to capitalize on prior knowledge, while integrating unsupervised deep-learning modules for image feature embeddings. This hybrid strategy strikes a balance between interpretability and accuracy. Evaluated on The Anthology of Chinese Folk Songs, our system massively digitizes (i) a melody-only collection of more than 5,000 songs (> 300,000 notes) and (ii) a curated subset with lyrics comprising over 1,400 songs (> 100,000 notes). The system achieves high-precision recognition on both melody (note-wise F1 = 0.951) and aligned lyrics (character-wise F1 = 0.931).
HQ-SVC: Towards High-Quality Zero-Shot Singing Voice Conversion in Low-Resource Scenarios
Nov 15, 2025Zero-shot singing voice conversion (SVC) transforms a source singer's timbre to an unseen target speaker's voice while preserving melodic content without fine-tuning. Existing methods model speaker timbre and vocal content separately, losing essential acoustic information that degrades output quality while requiring significant computational resources. To overcome these limitations, we propose HQ-SVC, an efficient framework for high-quality zero-shot SVC. HQ-SVC first extracts jointly content and speaker features using a decoupled codec. It then enhances fidelity through pitch and volume modeling, preserving critical acoustic information typically lost in separate modeling approaches, and progressively refines outputs via differentiable signal processing and diffusion techniques. Evaluations confirm HQ-SVC significantly outperforms state-of-the-art zero-shot SVC methods in conversion quality and efficiency. Beyond voice conversion, HQ-SVC achieves superior voice naturalness compared to specialized audio super-resolution methods while natively supporting voice super-resolution tasks.
SynParaSpeech: Automated Synthesis of Paralinguistic Datasets for Speech Generation and Understanding
Sep 18, 2025



Paralinguistic sounds, like laughter and sighs, are crucial for synthesizing more realistic and engaging speech. However, existing methods typically depend on proprietary datasets, while publicly available resources often suffer from incomplete speech, inaccurate or missing timestamps, and limited real-world relevance. To address these problems, we propose an automated framework for generating large-scale paralinguistic data and apply it to construct the SynParaSpeech dataset. The dataset comprises 6 paralinguistic categories with 118.75 hours of data and precise timestamps, all derived from natural conversational speech. Our contributions lie in introducing the first automated method for constructing large-scale paralinguistic datasets and releasing the SynParaSpeech corpus, which advances speech generation through more natural paralinguistic synthesis and enhances speech understanding by improving paralinguistic event detection. The dataset and audio samples are available at https://github.com/ShawnPi233/SynParaSpeech.
ViRefSAM: Visual Reference-Guided Segment Anything Model for Remote Sensing Segmentation
Jul 03, 2025The Segment Anything Model (SAM), with its prompt-driven paradigm, exhibits strong generalization in generic segmentation tasks. However, applying SAM to remote sensing (RS) images still faces two major challenges. First, manually constructing precise prompts for each image (e.g., points or boxes) is labor-intensive and inefficient, especially in RS scenarios with dense small objects or spatially fragmented distributions. Second, SAM lacks domain adaptability, as it is pre-trained primarily on natural images and struggles to capture RS-specific semantics and spatial characteristics, especially when segmenting novel or unseen classes. To address these issues, inspired by few-shot learning, we propose ViRefSAM, a novel framework that guides SAM utilizing only a few annotated reference images that contain class-specific objects. Without requiring manual prompts, ViRefSAM enables automatic segmentation of class-consistent objects across RS images. Specifically, ViRefSAM introduces two key components while keeping SAM's original architecture intact: (1) a Visual Contextual Prompt Encoder that extracts class-specific semantic clues from reference images and generates object-aware prompts via contextual interaction with target images; and (2) a Dynamic Target Alignment Adapter, integrated into SAM's image encoder, which mitigates the domain gap by injecting class-specific semantics into target image features, enabling SAM to dynamically focus on task-relevant regions. Extensive experiments on three few-shot segmentation benchmarks, including iSAID-5$^i$, LoveDA-2$^i$, and COCO-20$^i$, demonstrate that ViRefSAM enables accurate and automatic segmentation of unseen classes by leveraging only a few reference images and consistently outperforms existing few-shot segmentation methods across diverse datasets.
MGFF-TDNN: A Multi-Granularity Feature Fusion TDNN Model with Depth-Wise Separable Module for Speaker Verification
May 06, 2025In speaker verification, traditional models often emphasize modeling long-term contextual features to capture global speaker characteristics. However, this approach can neglect fine-grained voiceprint information, which contains highly discriminative features essential for robust speaker embeddings. This paper introduces a novel model architecture, termed MGFF-TDNN, based on multi-granularity feature fusion. The MGFF-TDNN leverages a two-dimensional depth-wise separable convolution module, enhanced with local feature modeling, as a front-end feature extractor to effectively capture time-frequency domain features. To achieve comprehensive multi-granularity feature fusion, we propose the M-TDNN structure, which integrates global contextual modeling with fine-grained feature extraction by combining time-delay neural networks and phoneme-level feature pooling. Experiments on the VoxCeleb dataset demonstrate that the MGFF-TDNN achieves outstanding performance in speaker verification while remaining efficient in terms of parameters and computational resources.
Psy-Insight: Explainable Multi-turn Bilingual Dataset for Mental Health Counseling
Mar 05, 2025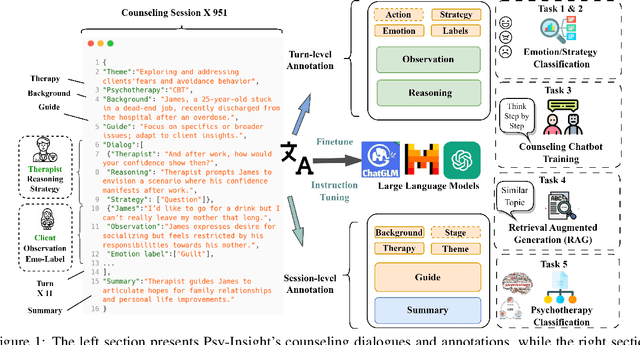
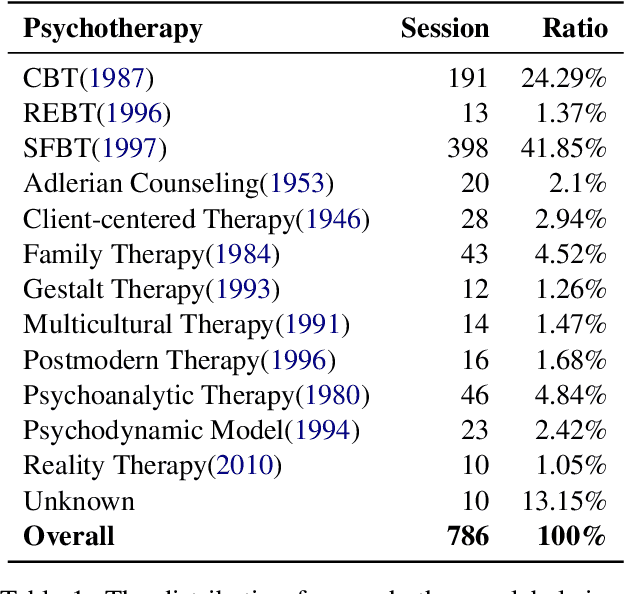
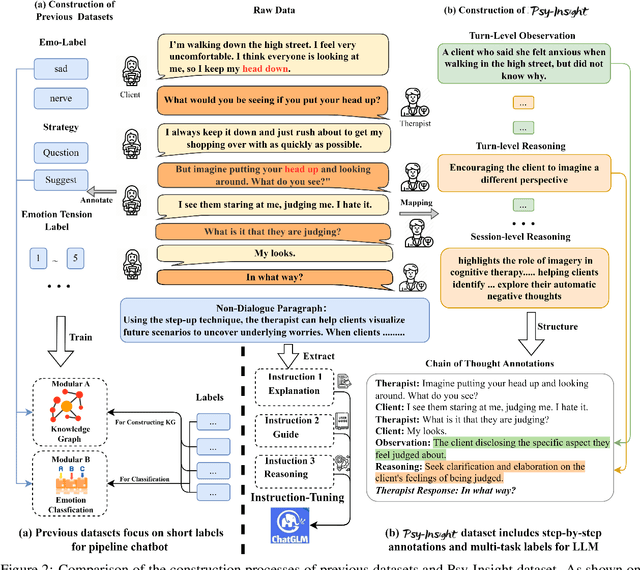
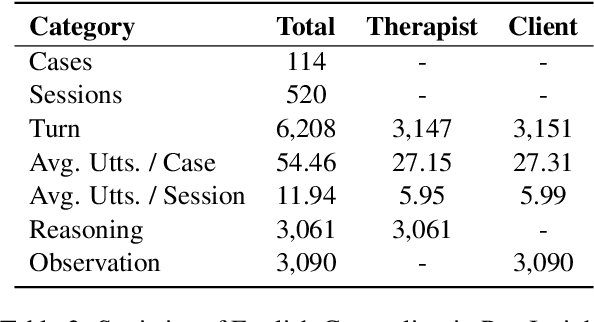
The in-context learning capabilities of large language models (LLMs) show great potential in mental health support. However, the lack of counseling datasets, particularly in Chinese corpora, restricts their application in this field. To address this, we constructed Psy-Insight, the first mental health-oriented explainable multi-task bilingual dataset. We collected face-to-face multi-turn counseling dialogues, which are annotated with multi-task labels and conversation process explanations. Our annotations include psychotherapy, emotion, strategy, and topic labels, as well as turn-level reasoning and session-level guidance. Psy-Insight is not only suitable for tasks such as label recognition but also meets the need for training LLMs to act as empathetic counselors through logical reasoning. Experiments show that training LLMs on Psy-Insight enables the models to not only mimic the conversation style but also understand the underlying strategies and reasoning of counseling.
Psy-Copilot: Visual Chain of Thought for Counseling
Mar 05, 2025

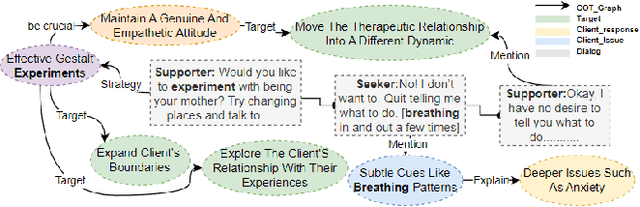

Large language models (LLMs) are becoming increasingly popular in the field of psychological counseling. However, when human therapists work with LLMs in therapy sessions, it is hard to understand how the model gives the answers. To address this, we have constructed Psy-COT, a graph designed to visualize the thought processes of LLMs during therapy sessions. The Psy-COT graph presents semi-structured counseling conversations alongside step-by-step annotations that capture the reasoning and insights of therapists. Moreover, we have developed Psy-Copilot, which is a conversational AI assistant designed to assist human psychological therapists in their consultations. It can offer traceable psycho-information based on retrieval, including response candidates, similar dialogue sessions, related strategies, and visual traces of results. We have also built an interactive platform for AI-assisted counseling. It has an interface that displays the relevant parts of the retrieval sub-graph. The Psy-Copilot is designed not to replace psychotherapists but to foster collaboration between AI and human therapists, thereby promoting mental health development. Our code and demo are both open-sourced and available for use.
Mel-Refine: A Plug-and-Play Approach to Refine Mel-Spectrogram in Audio Generation
Dec 11, 2024Text-to-audio (TTA) model is capable of generating diverse audio from textual prompts. However, most mainstream TTA models, which predominantly rely on Mel-spectrograms, still face challenges in producing audio with rich content. The intricate details and texture required in Mel-spectrograms for such audio often surpass the models' capacity, leading to outputs that are blurred or lack coherence. In this paper, we begin by investigating the critical role of U-Net in Mel-spectrogram generation. Our analysis shows that in U-Net structure, high-frequency components in skip-connections and the backbone influence texture and detail, while low-frequency components in the backbone are critical for the diffusion denoising process. We further propose ``Mel-Refine'', a plug-and-play approach that enhances Mel-spectrogram texture and detail by adjusting different component weights during inference. Our method requires no additional training or fine-tuning and is fully compatible with any diffusion-based TTA architecture. Experimental results show that our approach boosts performance metrics of the latest TTA model Tango2 by 25\%, demonstrating its effectiveness.