 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHQ-SVC: Towards High-Quality Zero-Shot Singing Voice Conversion in Low-Resource Scenarios
Nov 15, 2025Zero-shot singing voice conversion (SVC) transforms a source singer's timbre to an unseen target speaker's voice while preserving melodic content without fine-tuning. Existing methods model speaker timbre and vocal content separately, losing essential acoustic information that degrades output quality while requiring significant computational resources. To overcome these limitations, we propose HQ-SVC, an efficient framework for high-quality zero-shot SVC. HQ-SVC first extracts jointly content and speaker features using a decoupled codec. It then enhances fidelity through pitch and volume modeling, preserving critical acoustic information typically lost in separate modeling approaches, and progressively refines outputs via differentiable signal processing and diffusion techniques. Evaluations confirm HQ-SVC significantly outperforms state-of-the-art zero-shot SVC methods in conversion quality and efficiency. Beyond voice conversion, HQ-SVC achieves superior voice naturalness compared to specialized audio super-resolution methods while natively supporting voice super-resolution tasks.
SynParaSpeech: Automated Synthesis of Paralinguistic Datasets for Speech Generation and Understanding
Sep 18, 2025



Paralinguistic sounds, like laughter and sighs, are crucial for synthesizing more realistic and engaging speech. However, existing methods typically depend on proprietary datasets, while publicly available resources often suffer from incomplete speech, inaccurate or missing timestamps, and limited real-world relevance. To address these problems, we propose an automated framework for generating large-scale paralinguistic data and apply it to construct the SynParaSpeech dataset. The dataset comprises 6 paralinguistic categories with 118.75 hours of data and precise timestamps, all derived from natural conversational speech. Our contributions lie in introducing the first automated method for constructing large-scale paralinguistic datasets and releasing the SynParaSpeech corpus, which advances speech generation through more natural paralinguistic synthesis and enhances speech understanding by improving paralinguistic event detection. The dataset and audio samples are available at https://github.com/ShawnPi233/SynParaSpeech.
Psy-Insight: Explainable Multi-turn Bilingual Dataset for Mental Health Counseling
Mar 05, 2025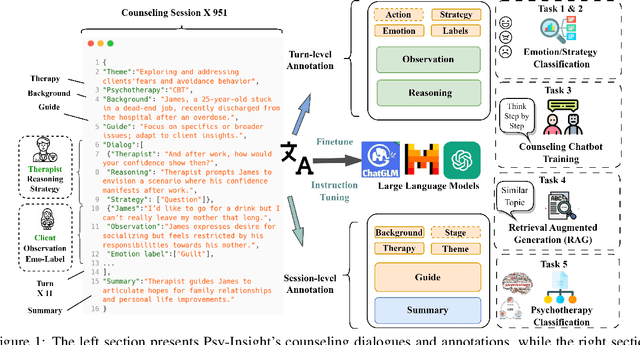
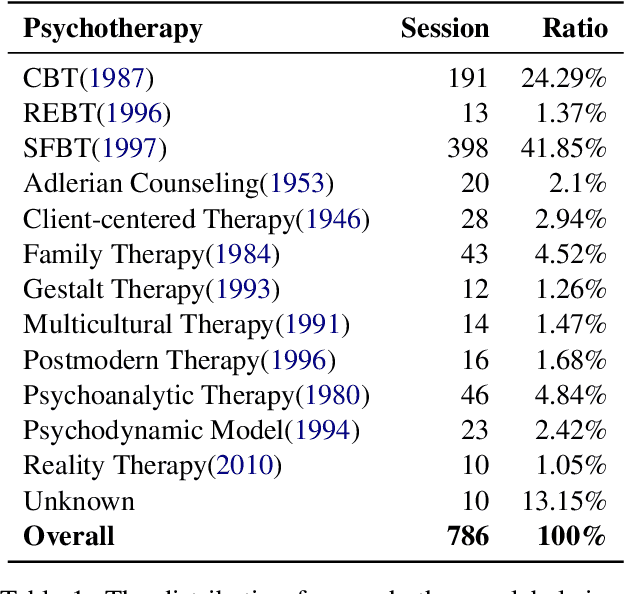
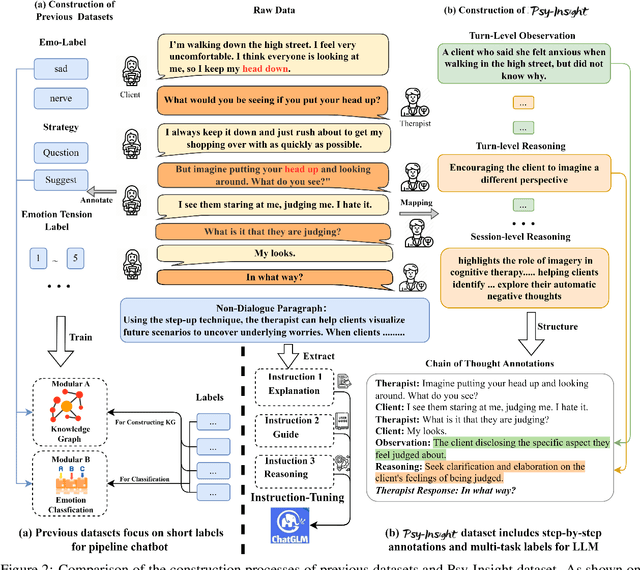
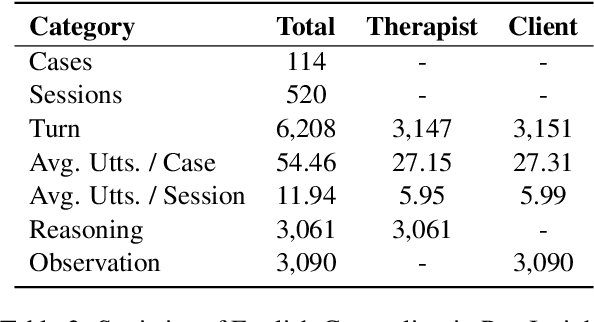
The in-context learning capabilities of large language models (LLMs) show great potential in mental health support. However, the lack of counseling datasets, particularly in Chinese corpora, restricts their application in this field. To address this, we constructed Psy-Insight, the first mental health-oriented explainable multi-task bilingual dataset. We collected face-to-face multi-turn counseling dialogues, which are annotated with multi-task labels and conversation process explanations. Our annotations include psychotherapy, emotion, strategy, and topic labels, as well as turn-level reasoning and session-level guidance. Psy-Insight is not only suitable for tasks such as label recognition but also meets the need for training LLMs to act as empathetic counselors through logical reasoning. Experiments show that training LLMs on Psy-Insight enables the models to not only mimic the conversation style but also understand the underlying strategies and reasoning of counseling.
Psy-Copilot: Visual Chain of Thought for Counseling
Mar 05, 2025

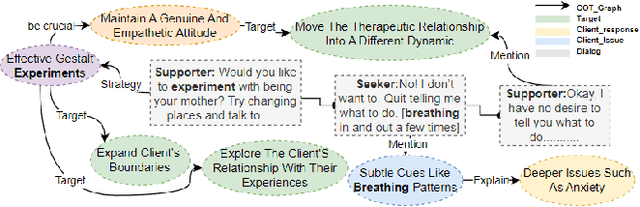

Large language models (LLMs) are becoming increasingly popular in the field of psychological counseling. However, when human therapists work with LLMs in therapy sessions, it is hard to understand how the model gives the answers. To address this, we have constructed Psy-COT, a graph designed to visualize the thought processes of LLMs during therapy sessions. The Psy-COT graph presents semi-structured counseling conversations alongside step-by-step annotations that capture the reasoning and insights of therapists. Moreover, we have developed Psy-Copilot, which is a conversational AI assistant designed to assist human psychological therapists in their consultations. It can offer traceable psycho-information based on retrieval, including response candidates, similar dialogue sessions, related strategies, and visual traces of results. We have also built an interactive platform for AI-assisted counseling. It has an interface that displays the relevant parts of the retrieval sub-graph. The Psy-Copilot is designed not to replace psychotherapists but to foster collaboration between AI and human therapists, thereby promoting mental health development. Our code and demo are both open-sourced and available for use.
Enhancing Modal Fusion by Alignment and Label Matching for Multimodal Emotion Recognition
Aug 18, 2024



To address the limitation in multimodal emotion recognition (MER) performance arising from inter-modal information fusion, we propose a novel MER framework based on multitask learning where fusion occurs after alignment, called Foal-Net. The framework is designed to enhance the effectiveness of modality fusion and includes two auxiliary tasks: audio-video emotion alignment (AVEL) and cross-modal emotion label matching (MEM). First, AVEL achieves alignment of emotional information in audio-video representations through contrastive learning. Then, a modal fusion network integrates the aligned features. Meanwhile, MEM assesses whether the emotions of the current sample pair are the same, providing assistance for modal information fusion and guiding the model to focus more on emotional information. The experimental results conducted on IEMOCAP corpus show that Foal-Net outperforms the state-of-the-art methods and emotion alignment is necessary before modal fusion.
SPA-SVC: Self-supervised Pitch Augmentation for Singing Voice Conversion
Jun 09, 2024



Diffusion-based singing voice conversion (SVC) models have shown better synthesis quality compared to traditional methods. However, in cross-domain SVC scenarios, where there is a significant disparity in pitch between the source and target voice domains, the models tend to generate audios with hoarseness, posing challenges in achieving high-quality vocal outputs. Therefore, in this paper, we propose a Self-supervised Pitch Augmentation method for Singing Voice Conversion (SPA-SVC), which can enhance the voice quality in SVC tasks without requiring additional data or increasing model parameters. We innovatively introduce a cycle pitch shifting training strategy and Structural Similarity Index (SSIM) loss into our SVC model, effectively enhancing its performance. Experimental results on the public singing datasets M4Singer indicate that our proposed method significantly improves model performance in both general SVC scenarios and particularly in cross-domain SVC scenarios.
Improving Audio Codec-based Zero-Shot Text-to-Speech Synthesis with Multi-Modal Context and Large Language Model
Jun 06, 2024


Recent advances in large language models (LLMs) and development of audio codecs greatly propel the zero-shot TTS. They can synthesize personalized speech with only a 3-second speech of an unseen speaker as acoustic prompt. However, they only support short speech prompts and cannot leverage longer context information, as required in audiobook and conversational TTS scenarios. In this paper, we introduce a novel audio codec-based TTS model to adapt context features with multiple enhancements. Inspired by the success of Qformer, we propose a multi-modal context-enhanced Qformer (MMCE-Qformer) to utilize additional multi-modal context information. Besides, we adapt a pretrained LLM to leverage its understanding ability to predict semantic tokens, and use a SoundStorm to generate acoustic tokens thereby enhancing audio quality and speaker similarity. The extensive objective and subjective evaluations show that our proposed method outperforms baselines across various context TTS scenarios.
Retrieval Augmented Generation in Prompt-based Text-to-Speech Synthesis with Context-Aware Contrastive Language-Audio Pretraining
Jun 06, 2024Recent prompt-based text-to-speech (TTS) models can clone an unseen speaker using only a short speech prompt. They leverage a strong in-context ability to mimic the speech prompts, including speaker style, prosody, and emotion. Therefore, the selection of a speech prompt greatly influences the generated speech, akin to the importance of a prompt in large language models (LLMs). However, current prompt-based TTS models choose the speech prompt manually or simply at random. Hence, in this paper, we adapt retrieval augmented generation (RAG) from LLMs to prompt-based TTS. Unlike traditional RAG methods, we additionally consider contextual information during the retrieval process and present a Context-Aware Contrastive Language-Audio Pre-training (CA-CLAP) model to extract context-aware, style-related features. The objective and subjective evaluations demonstrate that our proposed RAG method outperforms baselines, and our CA-CLAP achieves better results than text-only retrieval methods.
Auffusion: Leveraging the Power of Diffusion and Large Language Models for Text-to-Audio Generation
Jan 02, 2024Recent advancements in diffusion models and large language models (LLMs) have significantly propelled the field of AIGC. Text-to-Audio (TTA), a burgeoning AIGC application designed to generate audio from natural language prompts, is attracting increasing attention. However, existing TTA studies often struggle with generation quality and text-audio alignment, especially for complex textual inputs. Drawing inspiration from state-of-the-art Text-to-Image (T2I) diffusion models, we introduce Auffusion, a TTA system adapting T2I model frameworks to TTA task, by effectively leveraging their inherent generative strengths and precise cross-modal alignment. Our objective and subjective evaluations demonstrate that Auffusion surpasses previous TTA approaches using limited data and computational resource. Furthermore, previous studies in T2I recognizes the significant impact of encoder choice on cross-modal alignment, like fine-grained details and object bindings, while similar evaluation is lacking in prior TTA works. Through comprehensive ablation studies and innovative cross-attention map visualizations, we provide insightful assessments of text-audio alignment in TTA. Our findings reveal Auffusion's superior capability in generating audios that accurately match textual descriptions, which further demonstrated in several related tasks, such as audio style transfer, inpainting and other manipulations. Our implementation and demos are available at https://auffusion.github.io.
Frame-level emotional state alignment method for speech emotion recognition
Dec 27, 2023Speech emotion recognition (SER) systems aim to recognize human emotional state during human-computer interaction. Most existing SER systems are trained based on utterance-level labels. However, not all frames in an audio have affective states consistent with utterance-level label, which makes it difficult for the model to distinguish the true emotion of the audio and perform poorly. To address this problem, we propose a frame-level emotional state alignment method for SER. First, we fine-tune HuBERT model to obtain a SER system with task-adaptive pretraining (TAPT) method, and extract embeddings from its transformer layers to form frame-level pseudo-emotion labels with clustering. Then, the pseudo labels are used to pretrain HuBERT. Hence, the each frame output of HuBERT has corresponding emotional information. Finally, we fine-tune the above pretrained HuBERT for SER by adding an attention layer on the top of it, which can focus only on those frames that are emotionally more consistent with utterance-level label. The experimental results performed on IEMOCAP indicate that our proposed method performs better than state-of-the-art (SOTA) methods.