 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHQ-SVC: Towards High-Quality Zero-Shot Singing Voice Conversion in Low-Resource Scenarios
Nov 15, 2025Zero-shot singing voice conversion (SVC) transforms a source singer's timbre to an unseen target speaker's voice while preserving melodic content without fine-tuning. Existing methods model speaker timbre and vocal content separately, losing essential acoustic information that degrades output quality while requiring significant computational resources. To overcome these limitations, we propose HQ-SVC, an efficient framework for high-quality zero-shot SVC. HQ-SVC first extracts jointly content and speaker features using a decoupled codec. It then enhances fidelity through pitch and volume modeling, preserving critical acoustic information typically lost in separate modeling approaches, and progressively refines outputs via differentiable signal processing and diffusion techniques. Evaluations confirm HQ-SVC significantly outperforms state-of-the-art zero-shot SVC methods in conversion quality and efficiency. Beyond voice conversion, HQ-SVC achieves superior voice naturalness compared to specialized audio super-resolution methods while natively supporting voice super-resolution tasks.
Optimizing Neural Speech Codec for Low-Bitrate Compression via Multi-Scale Encoding
Oct 21, 2024



Neural speech codecs have demonstrated their ability to compress high-quality speech and audio by converting them into discrete token representations. Most existing methods utilize Residual Vector Quantization (RVQ) to encode speech into multiple layers of discrete codes with uniform time scales. However, this strategy overlooks the differences in information density across various speech features, leading to redundant encoding of sparse information, which limits the performance of these methods at low bitrate. This paper proposes MsCodec, a novel multi-scale neural speech codec that encodes speech into multiple layers of discrete codes, each corresponding to a different time scale. This encourages the model to decouple speech features according to their diverse information densities, consequently enhancing the performance of speech compression. Furthermore, we incorporate mutual information loss to augment the diversity among speech codes across different layers. Experimental results indicate that our proposed method significantly improves codec performance at low bitrate.
SPA-SVC: Self-supervised Pitch Augmentation for Singing Voice Conversion
Jun 09, 2024



Diffusion-based singing voice conversion (SVC) models have shown better synthesis quality compared to traditional methods. However, in cross-domain SVC scenarios, where there is a significant disparity in pitch between the source and target voice domains, the models tend to generate audios with hoarseness, posing challenges in achieving high-quality vocal outputs. Therefore, in this paper, we propose a Self-supervised Pitch Augmentation method for Singing Voice Conversion (SPA-SVC), which can enhance the voice quality in SVC tasks without requiring additional data or increasing model parameters. We innovatively introduce a cycle pitch shifting training strategy and Structural Similarity Index (SSIM) loss into our SVC model, effectively enhancing its performance. Experimental results on the public singing datasets M4Singer indicate that our proposed method significantly improves model performance in both general SVC scenarios and particularly in cross-domain SVC scenarios.
CONCSS: Contrastive-based Context Comprehension for Dialogue-appropriate Prosody in Conversational Speech Synthesis
Dec 16, 2023Conversational speech synthesis (CSS) incorporates historical dialogue as supplementary information with the aim of generating speech that has dialogue-appropriate prosody. While previous methods have already delved into enhancing context comprehension, context representation still lacks effective representation capabilities and context-sensitive discriminability. In this paper, we introduce a contrastive learning-based CSS framework, CONCSS. Within this framework, we define an innovative pretext task specific to CSS that enables the model to perform self-supervised learning on unlabeled conversational datasets to boost the model's context understanding. Additionally, we introduce a sampling strategy for negative sample augmentation to enhance context vectors' discriminability. This is the first attempt to integrate contrastive learning into CSS. We conduct ablation studies on different contrastive learning strategies and comprehensive experiments in comparison with prior CSS systems. Results demonstrate that the synthesized speech from our proposed method exhibits more contextually appropriate and sensitive prosody.
M2-CTTS: End-to-End Multi-scale Multi-modal Conversational Text-to-Speech Synthesis
May 03, 2023


Conversational text-to-speech (TTS) aims to synthesize speech with proper prosody of reply based on the historical conversation. However, it is still a challenge to comprehensively model the conversation, and a majority of conversational TTS systems only focus on extracting global information and omit local prosody features, which contain important fine-grained information like keywords and emphasis. Moreover, it is insufficient to only consider the textual features, and acoustic features also contain various prosody information. Hence, we propose M2-CTTS, an end-to-end multi-scale multi-modal conversational text-to-speech system, aiming to comprehensively utilize historical conversation and enhance prosodic expression. More specifically, we design a textual context module and an acoustic context module with both coarse-grained and fine-grained modeling. Experimental results demonstrate that our model mixed with fine-grained context information and additionally considering acoustic features achieves better prosody performance and naturalness in CMOS tests.
Multi-scale multi-modal micro-expression recognition algorithm based on transformer
Jan 11, 2023



A micro-expression is a spontaneous unconscious facial muscle movement that can reveal the true emotions people attempt to hide. Although manual methods have made good progress and deep learning is gaining prominence. Due to the short duration of micro-expression and different scales of expressed in facial regions, existing algorithms cannot extract multi-modal multi-scale facial region features while taking into account contextual information to learn underlying features. Therefore, in order to solve the above problems, a multi-modal multi-scale algorithm based on transformer network is proposed in this paper, aiming to fully learn local multi-grained features of micro-expressions through two modal features of micro-expressions - motion features and texture features. To obtain local area features of the face at different scales, we learned patch features at different scales for both modalities, and then fused multi-layer multi-headed attention weights to obtain effective features by weighting the patch features, and combined cross-modal contrastive learning for model optimization. We conducted comprehensive experiments on three spontaneous datasets, and the results show the accuracy of the proposed algorithm in single measurement SMIC database is up to 78.73% and the F1 value on CASMEII of the combined database is up to 0.9071, which is at the leading level.
A Dynamic 3D Spontaneous Micro-expression Database: Establishment and Evaluation
Aug 22, 2021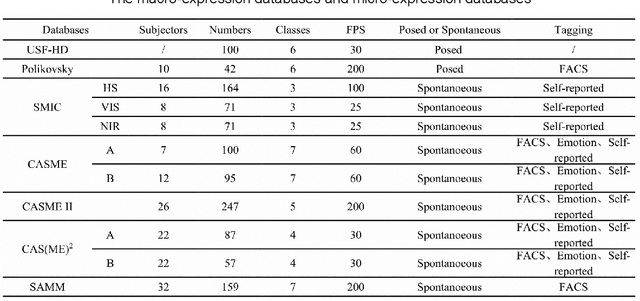
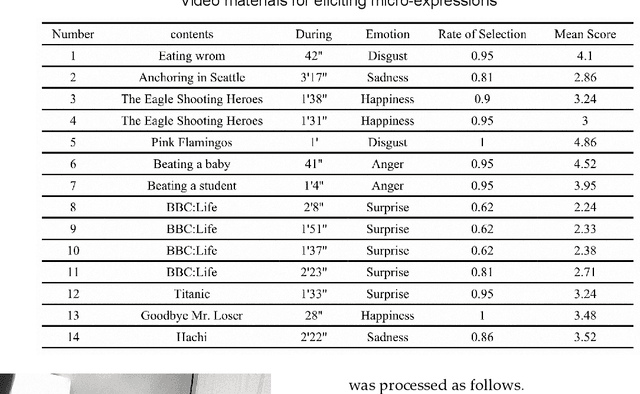


Micro-expressions are spontaneous, unconscious facial movements that show people's true inner emotions and have great potential in related fields of psychological testing. Since the face is a 3D deformation object, the occurrence of an expression can arouse spatial deformation of the face, but limited by the available databases are 2D videos, lacking the description of 3D spatial information of micro-expressions. Therefore, we proposed a new micro-expression database containing 2D video sequences and 3D point clouds sequences. The database includes 259 micro-expressions sequences, and these samples were classified using the objective method based on facial action coding system, as well as the non-objective method that combines video contents and participants' self-reports. We extracted 2D and 3D features using the local binary patterns on three orthogonal planes (LBP-TOP) and curvature algorithms, respectively, and evaluated the classification accuracies of these two features and their fusion results with leave-one-subject-out (LOSO) and 10-fold cross-validation. Further, we performed various neural network algorithms for database classification, the results show that classification accuracies are improved by fusing 3D features than using only 2D features. The database offers original and cropped micro-expression samples, which will facilitate the exploration and research on 3D Spatio-temporal features of micro-expressions.