 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTellWhisper: Tell Whisper Who Speaks When
Jan 08, 2026Multi-speaker automatic speech recognition (MASR) aims to predict ''who spoke when and what'' from multi-speaker speech, a key technology for multi-party dialogue understanding. However, most existing approaches decouple temporal modeling and speaker modeling when addressing ''when'' and ''who'': some inject speaker cues before encoding (e.g., speaker masking), which can cause irreversible information loss; others fuse identity by mixing speaker posteriors after encoding, which may entangle acoustic content with speaker identity. This separation is brittle under rapid turn-taking and overlapping speech, often leading to degraded performance. To address these limitations, we propose TellWhisper, a unified framework that jointly models speaker identity and temporal within the speech encoder. Specifically, we design TS-RoPE, a time-speaker rotary positional encoding: time coordinates are derived from frame indices, while speaker coordinates are derived from speaker activity and pause cues. By applying region-specific rotation angles, the model explicitly captures per-speaker continuity, speaker-turn transitions, and state dynamics, enabling the attention mechanism to simultaneously attend to ''when'' and ''who''. Moreover, to estimate frame-level speaker activity, we develop Hyper-SD, which casts speaker classification in hyperbolic space to enhance inter-class separation and refine speaker-activity estimates. Extensive experiments demonstrate the effectiveness of the proposed approach.
Optimizing Neural Speech Codec for Low-Bitrate Compression via Multi-Scale Encoding
Oct 21, 2024



Neural speech codecs have demonstrated their ability to compress high-quality speech and audio by converting them into discrete token representations. Most existing methods utilize Residual Vector Quantization (RVQ) to encode speech into multiple layers of discrete codes with uniform time scales. However, this strategy overlooks the differences in information density across various speech features, leading to redundant encoding of sparse information, which limits the performance of these methods at low bitrate. This paper proposes MsCodec, a novel multi-scale neural speech codec that encodes speech into multiple layers of discrete codes, each corresponding to a different time scale. This encourages the model to decouple speech features according to their diverse information densities, consequently enhancing the performance of speech compression. Furthermore, we incorporate mutual information loss to augment the diversity among speech codes across different layers. Experimental results indicate that our proposed method significantly improves codec performance at low bitrate.
Geometric Artifact Correction for Symmetric Multi-Linear Trajectory CT: Theory, Method, and Generalization
Aug 27, 2024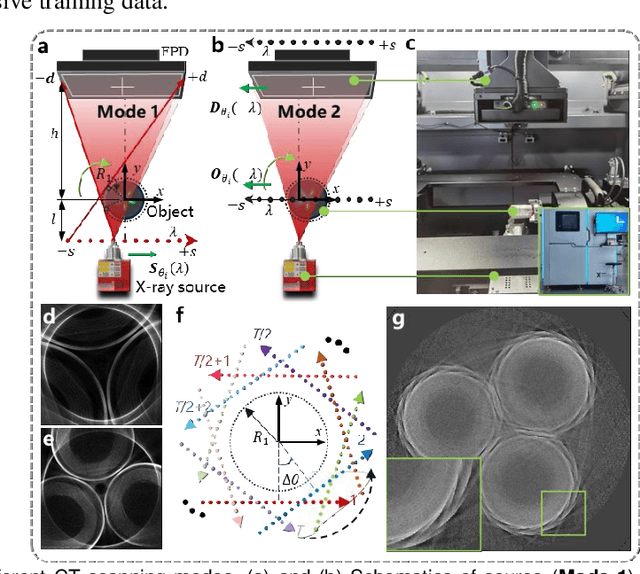
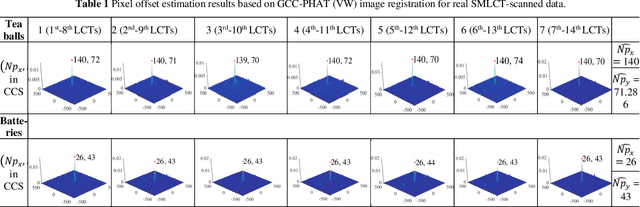
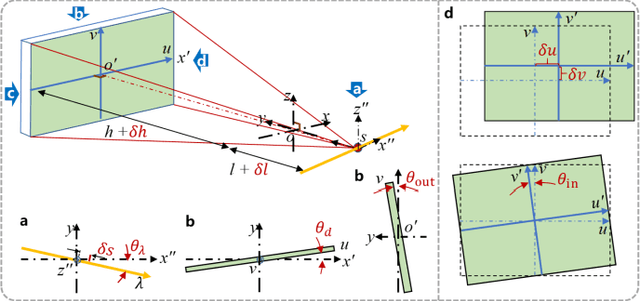
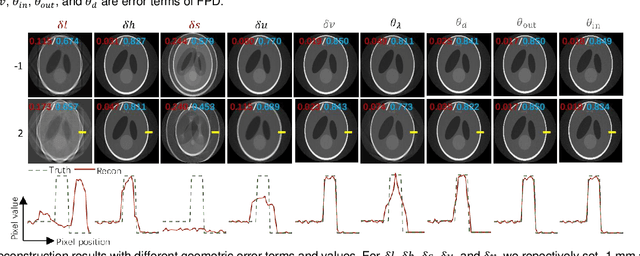
For extending CT field-of-view to perform non-destructive testing, the Symmetric Multi-Linear trajectory Computed Tomography (SMLCT) has been developed as a successful example of non-standard CT scanning modes. However, inevitable geometric errors can cause severe artifacts in the reconstructed images. The existing calibration method for SMLCT is both crude and inefficient. It involves reconstructing hundreds of images by exhaustively substituting each potential error, and then manually identifying the images with the fewest geometric artifacts to estimate the final geometric errors for calibration. In this paper, we comprehensively and efficiently address the challenging geometric artifacts in SMLCT, , and the corresponding works mainly involve theory, method, and generalization. In particular, after identifying sensitive parameters and conducting some theory analysis of geometric artifacts, we summarize several key properties between sensitive geometric parameters and artifact characteristics. Then, we further construct mathematical relationships that relate sensitive geometric errors to the pixel offsets of reconstruction images with artifact characteristics. To accurately extract pixel bias, we innovatively adapt the Generalized Cross-Correlation with Phase Transform (GCC-PHAT) algorithm, commonly used in sound processing, for our image registration task for each paired symmetric LCT. This adaptation leads to the design of a highly efficient rigid translation registration method. Simulation and physical experiments have validated the excellent performance of this work. Additionally, our results demonstrate significant generalization to common rotated CT and a variant of SMLCT.
Spontaneous Style Text-to-Speech Synthesis with Controllable Spontaneous Behaviors Based on Language Models
Jul 18, 2024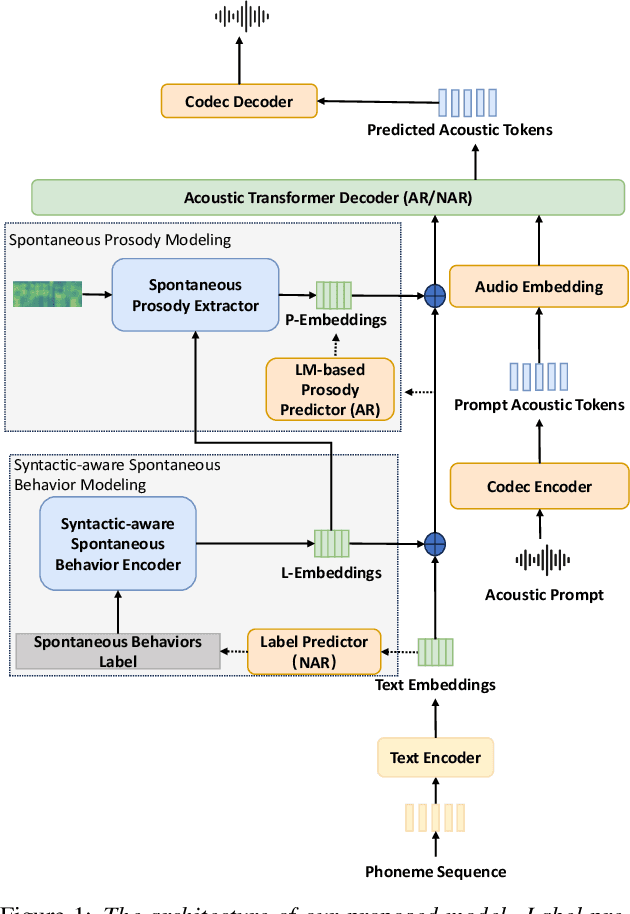
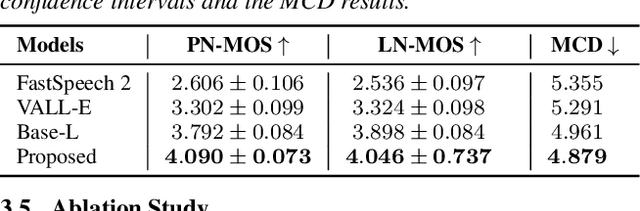
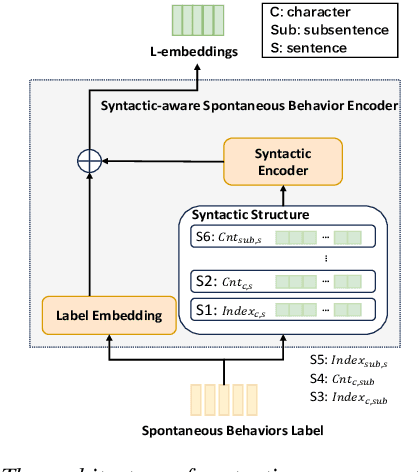
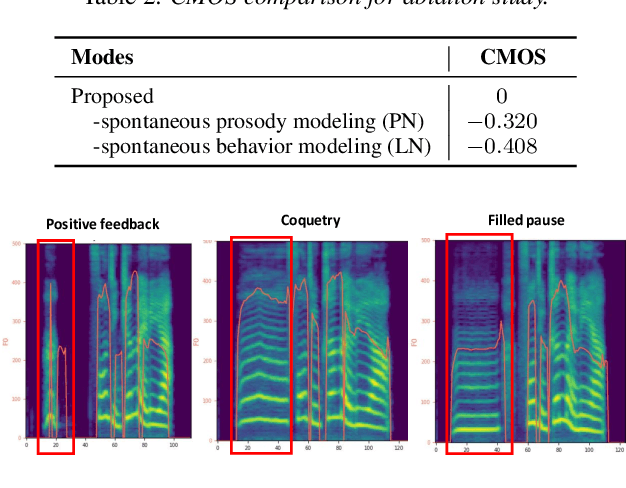
Spontaneous style speech synthesis, which aims to generate human-like speech, often encounters challenges due to the scarcity of high-quality data and limitations in model capabilities. Recent language model-based TTS systems can be trained on large, diverse, and low-quality speech datasets, resulting in highly natural synthesized speech. However, they are limited by the difficulty of simulating various spontaneous behaviors and capturing prosody variations in spontaneous speech. In this paper, we propose a novel spontaneous speech synthesis system based on language models. We systematically categorize and uniformly model diverse spontaneous behaviors. Moreover, fine-grained prosody modeling is introduced to enhance the model's ability to capture subtle prosody variations in spontaneous speech.Experimental results show that our proposed method significantly outperforms the baseline methods in terms of prosody naturalness and spontaneous behavior naturalness.
AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation
Mar 26, 2024

In this study, we propose AniPortrait, a novel framework for generating high-quality animation driven by audio and a reference portrait image. Our methodology is divided into two stages. Initially, we extract 3D intermediate representations from audio and project them into a sequence of 2D facial landmarks. Subsequently, we employ a robust diffusion model, coupled with a motion module, to convert the landmark sequence into photorealistic and temporally consistent portrait animation. Experimental results demonstrate the superiority of AniPortrait in terms of facial naturalness, pose diversity, and visual quality, thereby offering an enhanced perceptual experience. Moreover, our methodology exhibits considerable potential in terms of flexibility and controllability, which can be effectively applied in areas such as facial motion editing or face reenactment. We release code and model weights at https://github.com/scutzzj/AniPortrait
3D Visibility-aware Generalizable Neural Radiance Fields for Interacting Hands
Jan 02, 2024



Neural radiance fields (NeRFs) are promising 3D representations for scenes, objects, and humans. However, most existing methods require multi-view inputs and per-scene training, which limits their real-life applications. Moreover, current methods focus on single-subject cases, leaving scenes of interacting hands that involve severe inter-hand occlusions and challenging view variations remain unsolved. To tackle these issues, this paper proposes a generalizable visibility-aware NeRF (VA-NeRF) framework for interacting hands. Specifically, given an image of interacting hands as input, our VA-NeRF first obtains a mesh-based representation of hands and extracts their corresponding geometric and textural features. Subsequently, a feature fusion module that exploits the visibility of query points and mesh vertices is introduced to adaptively merge features of both hands, enabling the recovery of features in unseen areas. Additionally, our VA-NeRF is optimized together with a novel discriminator within an adversarial learning paradigm. In contrast to conventional discriminators that predict a single real/fake label for the synthesized image, the proposed discriminator generates a pixel-wise visibility map, providing fine-grained supervision for unseen areas and encouraging the VA-NeRF to improve the visual quality of synthesized images. Experiments on the Interhand2.6M dataset demonstrate that our proposed VA-NeRF outperforms conventional NeRFs significantly. Project Page: \url{https://github.com/XuanHuang0/VANeRF}.
Monocular 3D Hand Mesh Recovery via Dual Noise Estimation
Dec 26, 2023



Current parametric models have made notable progress in 3D hand pose and shape estimation. However, due to the fixed hand topology and complex hand poses, current models are hard to generate meshes that are aligned with the image well. To tackle this issue, we introduce a dual noise estimation method in this paper. Given a single-view image as input, we first adopt a baseline parametric regressor to obtain the coarse hand meshes. We assume the mesh vertices and their image-plane projections are noisy, and can be associated in a unified probabilistic model. We then learn the distributions of noise to refine mesh vertices and their projections. The refined vertices are further utilized to refine camera parameters in a closed-form manner. Consequently, our method obtains well-aligned and high-quality 3D hand meshes. Extensive experiments on the large-scale Interhand2.6M dataset demonstrate that the proposed method not only improves the performance of its baseline by more than 10$\%$ but also achieves state-of-the-art performance. Project page: \url{https://github.com/hanhuili/DNE4Hand}.
OSNet & MNetO: Two Types of General Reconstruction Architectures for Linear Computed Tomography in Multi-Scenarios
Sep 25, 2023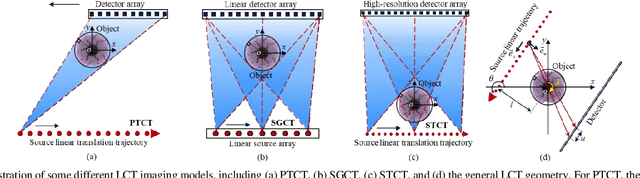
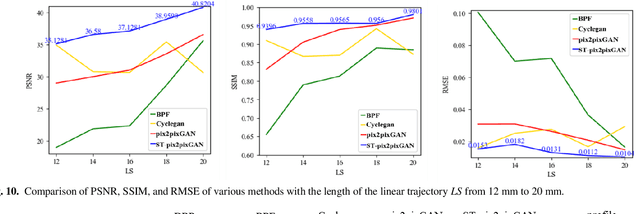
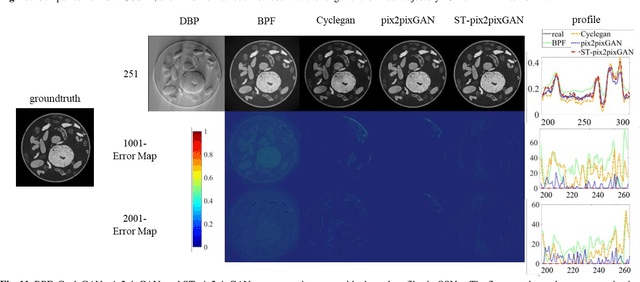
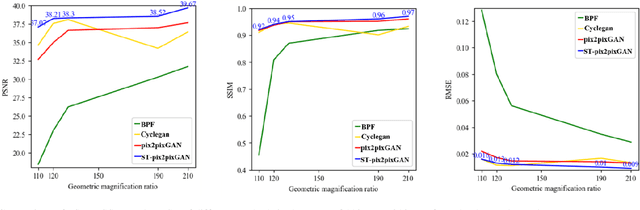
Recently, linear computed tomography (LCT) systems have actively attracted attention. To weaken projection truncation and image the region of interest (ROI) for LCT, the backprojection filtration (BPF) algorithm is an effective solution. However, in BPF for LCT, it is difficult to achieve stable interior reconstruction, and for differentiated backprojection (DBP) images of LCT, multiple rotation-finite inversion of Hilbert transform (Hilbert filtering)-inverse rotation operations will blur the image. To satisfy multiple reconstruction scenarios for LCT, including interior ROI, complete object, and exterior region beyond field-of-view (FOV), and avoid the rotation operations of Hilbert filtering, we propose two types of reconstruction architectures. The first overlays multiple DBP images to obtain a complete DBP image, then uses a network to learn the overlying Hilbert filtering function, referred to as the Overlay-Single Network (OSNet). The second uses multiple networks to train different directional Hilbert filtering models for DBP images of multiple linear scannings, respectively, and then overlays the reconstructed results, i.e., Multiple Networks Overlaying (MNetO). In two architectures, we introduce a Swin Transformer (ST) block to the generator of pix2pixGAN to extract both local and global features from DBP images at the same time. We investigate two architectures from different networks, FOV sizes, pixel sizes, number of projections, geometric magnification, and processing time. Experimental results show that two architectures can both recover images. OSNet outperforms BPF in various scenarios. For the different networks, ST-pix2pixGAN is superior to pix2pixGAN and CycleGAN. MNetO exhibits a few artifacts due to the differences among the multiple models, but any one of its models is suitable for imaging the exterior edge in a certain direction.
ExpCLIP: Bridging Text and Facial Expressions via Semantic Alignment
Sep 11, 2023The objective of stylized speech-driven facial animation is to create animations that encapsulate specific emotional expressions. Existing methods often depend on pre-established emotional labels or facial expression templates, which may limit the necessary flexibility for accurately conveying user intent. In this research, we introduce a technique that enables the control of arbitrary styles by leveraging natural language as emotion prompts. This technique presents benefits in terms of both flexibility and user-friendliness. To realize this objective, we initially construct a Text-Expression Alignment Dataset (TEAD), wherein each facial expression is paired with several prompt-like descriptions.We propose an innovative automatic annotation method, supported by Large Language Models (LLMs), to expedite the dataset construction, thereby eliminating the substantial expense of manual annotation. Following this, we utilize TEAD to train a CLIP-based model, termed ExpCLIP, which encodes text and facial expressions into semantically aligned style embeddings. The embeddings are subsequently integrated into the facial animation generator to yield expressive and controllable facial animations. Given the limited diversity of facial emotions in existing speech-driven facial animation training data, we further introduce an effective Expression Prompt Augmentation (EPA) mechanism to enable the animation generator to support unprecedented richness in style control. Comprehensive experiments illustrate that our method accomplishes expressive facial animation generation and offers enhanced flexibility in effectively conveying the desired style.
LongDanceDiff: Long-term Dance Generation with Conditional Diffusion Model
Aug 23, 2023



Dancing with music is always an essential human art form to express emotion. Due to the high temporal-spacial complexity, long-term 3D realist dance generation synchronized with music is challenging. Existing methods suffer from the freezing problem when generating long-term dances due to error accumulation and training-inference discrepancy. To address this, we design a conditional diffusion model, LongDanceDiff, for this sequence-to-sequence long-term dance generation, addressing the challenges of temporal coherency and spatial constraint. LongDanceDiff contains a transformer-based diffusion model, where the input is a concatenation of music, past motions, and noised future motions. This partial noising strategy leverages the full-attention mechanism and learns the dependencies among music and past motions. To enhance the diversity of generated dance motions and mitigate the freezing problem, we introduce a mutual information minimization objective that regularizes the dependency between past and future motions. We also address common visual quality issues in dance generation, such as foot sliding and unsmooth motion, by incorporating spatial constraints through a Global-Trajectory Modulation (GTM) layer and motion perceptual losses, thereby improving the smoothness and naturalness of motion generation. Extensive experiments demonstrate a significant improvement in our approach over the existing state-of-the-art methods. We plan to release our codes and models soon.