 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Generalization from Embedding Dimension and Distributional Convergence
Jan 30, 2026Deep neural networks often generalize well despite heavy over-parameterization, challenging classical parameter-based analyses. We study generalization from a representation-centric perspective and analyze how the geometry of learned embeddings controls predictive performance for a fixed trained model. We show that population risk can be bounded by two factors: (i) the intrinsic dimension of the embedding distribution, which determines the convergence rate of empirical embedding distribution to the population distribution in Wasserstein distance, and (ii) the sensitivity of the downstream mapping from embeddings to predictions, characterized by Lipschitz constants. Together, these yield an embedding-dependent error bound that does not rely on parameter counts or hypothesis class complexity. At the final embedding layer, architectural sensitivity vanishes and the bound is dominated by embedding dimension, explaining its strong empirical correlation with generalization performance. Experiments across architectures and datasets validate the theory and demonstrate the utility of embedding-based diagnostics.
Local Intrinsic Dimension of Representations Predicts Alignment and Generalization in AI Models and Human Brain
Jan 30, 2026Recent work has found that neural networks with stronger generalization tend to exhibit higher representational alignment with one another across architectures and training paradigms. In this work, we show that models with stronger generalization also align more strongly with human neural activity. Moreover, generalization performance, model--model alignment, and model--brain alignment are all significantly correlated with each other. We further show that these relationships can be explained by a single geometric property of learned representations: the local intrinsic dimension of embeddings. Lower local dimension is consistently associated with stronger model--model alignment, stronger model--brain alignment, and better generalization, whereas global dimension measures fail to capture these effects. Finally, we find that increasing model capacity and training data scale systematically reduces local intrinsic dimension, providing a geometric account of the benefits of scaling. Together, our results identify local intrinsic dimension as a unifying descriptor of representational convergence in artificial and biological systems.
Scale-Invariance Drives Convergence in AI and Brain Representations
Jun 13, 2025Despite variations in architecture and pretraining strategies, recent studies indicate that large-scale AI models often converge toward similar internal representations that also align with neural activity. We propose that scale-invariance, a fundamental structural principle in natural systems, is a key driver of this convergence. In this work, we propose a multi-scale analytical framework to quantify two core aspects of scale-invariance in AI representations: dimensional stability and structural similarity across scales. We further investigate whether these properties can predict alignment performance with functional Magnetic Resonance Imaging (fMRI) responses in the visual cortex. Our analysis reveals that embeddings with more consistent dimension and higher structural similarity across scales align better with fMRI data. Furthermore, we find that the manifold structure of fMRI data is more concentrated, with most features dissipating at smaller scales. Embeddings with similar scale patterns align more closely with fMRI data. We also show that larger pretraining datasets and the inclusion of language modalities enhance the scale-invariance properties of embeddings, further improving neural alignment. Our findings indicate that scale-invariance is a fundamental structural principle that bridges artificial and biological representations, providing a new framework for evaluating the structural quality of human-like AI systems.
BIMgent: Towards Autonomous Building Modeling via Computer-use Agents
Jun 08, 2025Existing computer-use agents primarily focus on general-purpose desktop automation tasks, with limited exploration of their application in highly specialized domains. In particular, the 3D building modeling process in the Architecture, Engineering, and Construction (AEC) sector involves open-ended design tasks and complex interaction patterns within Building Information Modeling (BIM) authoring software, which has yet to be thoroughly addressed by current studies. In this paper, we propose BIMgent, an agentic framework powered by multimodal large language models (LLMs), designed to enable autonomous building model authoring via graphical user interface (GUI) operations. BIMgent automates the architectural building modeling process, including multimodal input for conceptual design, planning of software-specific workflows, and efficient execution of the authoring GUI actions. We evaluate BIMgent on real-world building modeling tasks, including both text-based conceptual design generation and reconstruction from existing building design. The design quality achieved by BIMgent was found to be reasonable. Its operations achieved a 32% success rate, whereas all baseline models failed to complete the tasks (0% success rate). Results demonstrate that BIMgent effectively reduces manual workload while preserving design intent, highlighting its potential for practical deployment in real-world architectural modeling scenarios.
OSNet & MNetO: Two Types of General Reconstruction Architectures for Linear Computed Tomography in Multi-Scenarios
Sep 25, 2023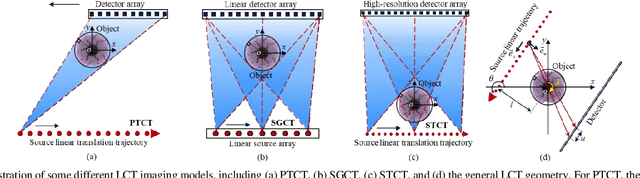
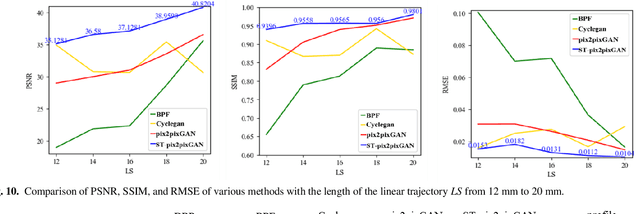
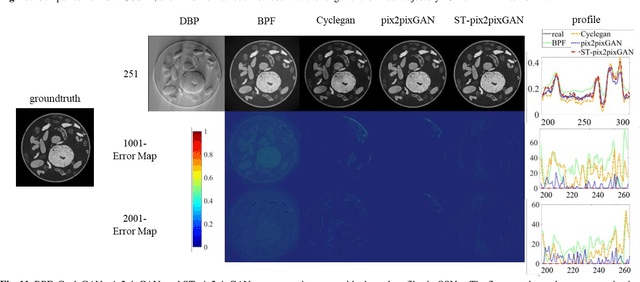
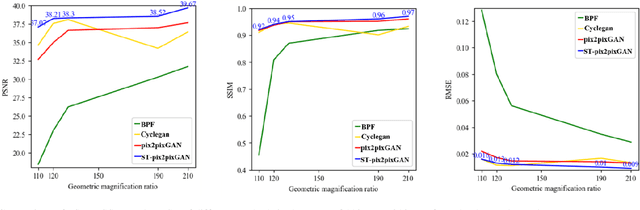
Recently, linear computed tomography (LCT) systems have actively attracted attention. To weaken projection truncation and image the region of interest (ROI) for LCT, the backprojection filtration (BPF) algorithm is an effective solution. However, in BPF for LCT, it is difficult to achieve stable interior reconstruction, and for differentiated backprojection (DBP) images of LCT, multiple rotation-finite inversion of Hilbert transform (Hilbert filtering)-inverse rotation operations will blur the image. To satisfy multiple reconstruction scenarios for LCT, including interior ROI, complete object, and exterior region beyond field-of-view (FOV), and avoid the rotation operations of Hilbert filtering, we propose two types of reconstruction architectures. The first overlays multiple DBP images to obtain a complete DBP image, then uses a network to learn the overlying Hilbert filtering function, referred to as the Overlay-Single Network (OSNet). The second uses multiple networks to train different directional Hilbert filtering models for DBP images of multiple linear scannings, respectively, and then overlays the reconstructed results, i.e., Multiple Networks Overlaying (MNetO). In two architectures, we introduce a Swin Transformer (ST) block to the generator of pix2pixGAN to extract both local and global features from DBP images at the same time. We investigate two architectures from different networks, FOV sizes, pixel sizes, number of projections, geometric magnification, and processing time. Experimental results show that two architectures can both recover images. OSNet outperforms BPF in various scenarios. For the different networks, ST-pix2pixGAN is superior to pix2pixGAN and CycleGAN. MNetO exhibits a few artifacts due to the differences among the multiple models, but any one of its models is suitable for imaging the exterior edge in a certain direction.