 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Neural Speech Codec for Low-Bitrate Compression via Multi-Scale Encoding
Oct 21, 2024



Neural speech codecs have demonstrated their ability to compress high-quality speech and audio by converting them into discrete token representations. Most existing methods utilize Residual Vector Quantization (RVQ) to encode speech into multiple layers of discrete codes with uniform time scales. However, this strategy overlooks the differences in information density across various speech features, leading to redundant encoding of sparse information, which limits the performance of these methods at low bitrate. This paper proposes MsCodec, a novel multi-scale neural speech codec that encodes speech into multiple layers of discrete codes, each corresponding to a different time scale. This encourages the model to decouple speech features according to their diverse information densities, consequently enhancing the performance of speech compression. Furthermore, we incorporate mutual information loss to augment the diversity among speech codes across different layers. Experimental results indicate that our proposed method significantly improves codec performance at low bitrate.
End to End Face Reconstruction via Differentiable PnP
Sep 21, 2024This is a challenge report of the ECCV 2022 WCPA Challenge, Face Reconstruction Track. Inside this report is a brief explanation of how we accomplish this challenge. We design a two-branch network to accomplish this task, whose roles are Face Reconstruction and Face Landmark Detection. The former outputs canonical 3D face coordinates. The latter outputs pixel coordinates, i.e. 2D mapping of 3D coordinates with head pose and perspective projection. In addition, we utilize a differentiable PnP (Perspective-n-Points) layer to finetune the outputs of the two branch. Our method achieves very competitive quantitative results on the MVP-Human dataset and wins a $3^{rd}$ prize in the challenge.
AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation
Mar 26, 2024

In this study, we propose AniPortrait, a novel framework for generating high-quality animation driven by audio and a reference portrait image. Our methodology is divided into two stages. Initially, we extract 3D intermediate representations from audio and project them into a sequence of 2D facial landmarks. Subsequently, we employ a robust diffusion model, coupled with a motion module, to convert the landmark sequence into photorealistic and temporally consistent portrait animation. Experimental results demonstrate the superiority of AniPortrait in terms of facial naturalness, pose diversity, and visual quality, thereby offering an enhanced perceptual experience. Moreover, our methodology exhibits considerable potential in terms of flexibility and controllability, which can be effectively applied in areas such as facial motion editing or face reenactment. We release code and model weights at https://github.com/scutzzj/AniPortrait
ExpCLIP: Bridging Text and Facial Expressions via Semantic Alignment
Sep 11, 2023The objective of stylized speech-driven facial animation is to create animations that encapsulate specific emotional expressions. Existing methods often depend on pre-established emotional labels or facial expression templates, which may limit the necessary flexibility for accurately conveying user intent. In this research, we introduce a technique that enables the control of arbitrary styles by leveraging natural language as emotion prompts. This technique presents benefits in terms of both flexibility and user-friendliness. To realize this objective, we initially construct a Text-Expression Alignment Dataset (TEAD), wherein each facial expression is paired with several prompt-like descriptions.We propose an innovative automatic annotation method, supported by Large Language Models (LLMs), to expedite the dataset construction, thereby eliminating the substantial expense of manual annotation. Following this, we utilize TEAD to train a CLIP-based model, termed ExpCLIP, which encodes text and facial expressions into semantically aligned style embeddings. The embeddings are subsequently integrated into the facial animation generator to yield expressive and controllable facial animations. Given the limited diversity of facial emotions in existing speech-driven facial animation training data, we further introduce an effective Expression Prompt Augmentation (EPA) mechanism to enable the animation generator to support unprecedented richness in style control. Comprehensive experiments illustrate that our method accomplishes expressive facial animation generation and offers enhanced flexibility in effectively conveying the desired style.
XFormer: Fast and Accurate Monocular 3D Body Capture
May 18, 2023We present XFormer, a novel human mesh and motion capture method that achieves real-time performance on consumer CPUs given only monocular images as input. The proposed network architecture contains two branches: a keypoint branch that estimates 3D human mesh vertices given 2D keypoints, and an image branch that makes predictions directly from the RGB image features. At the core of our method is a cross-modal transformer block that allows information to flow across these two branches by modeling the attention between 2D keypoint coordinates and image spatial features. Our architecture is smartly designed, which enables us to train on various types of datasets including images with 2D/3D annotations, images with 3D pseudo labels, and motion capture datasets that do not have associated images. This effectively improves the accuracy and generalization ability of our system. Built on a lightweight backbone (MobileNetV3), our method runs blazing fast (over 30fps on a single CPU core) and still yields competitive accuracy. Furthermore, with an HRNet backbone, XFormer delivers state-of-the-art performance on Huamn3.6 and 3DPW datasets.
Human MotionFormer: Transferring Human Motions with Vision Transformers
Feb 25, 2023Human motion transfer aims to transfer motions from a target dynamic person to a source static one for motion synthesis. An accurate matching between the source person and the target motion in both large and subtle motion changes is vital for improving the transferred motion quality. In this paper, we propose Human MotionFormer, a hierarchical ViT framework that leverages global and local perceptions to capture large and subtle motion matching, respectively. It consists of two ViT encoders to extract input features (i.e., a target motion image and a source human image) and a ViT decoder with several cascaded blocks for feature matching and motion transfer. In each block, we set the target motion feature as Query and the source person as Key and Value, calculating the cross-attention maps to conduct a global feature matching. Further, we introduce a convolutional layer to improve the local perception after the global cross-attention computations. This matching process is implemented in both warping and generation branches to guide the motion transfer. During training, we propose a mutual learning loss to enable the co-supervision between warping and generation branches for better motion representations. Experiments show that our Human MotionFormer sets the new state-of-the-art performance both qualitatively and quantitatively. Project page: \url{https://github.com/KumapowerLIU/Human-MotionFormer}
Balanced Alignment for Face Recognition: A Joint Learning Approach
Mar 23, 2020



Face alignment is crucial for face recognition and has been widely adopted. However, current practice is too simple and under-explored. There lacks an understanding of how important face alignment is and how it should be performed, for recognition. This work studies these problems and makes two contributions. First, it provides an in-depth and quantitative study of how alignment strength affects recognition accuracy. Our results show that excessive alignment is harmful and an optimal balanced point of alignment is in need. To strike the balance, our second contribution is a novel joint learning approach where alignment learning is controllable with respect to its strength and driven by recognition. Our proposed method is validated by comprehensive experiments on several benchmarks, especially the challenging ones with large pose.
3D Dense Face Alignment via Graph Convolution Networks
Apr 11, 2019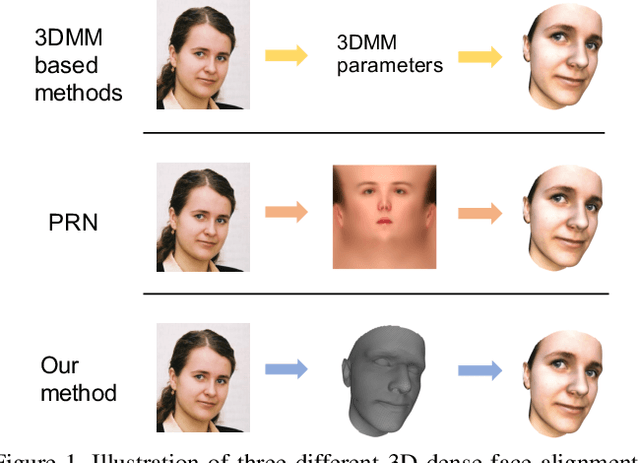



Recently, 3D face reconstruction and face alignment tasks are gradually combined into one task: 3D dense face alignment. Its goal is to reconstruct the 3D geometric structure of face with pose information. In this paper, we propose a graph convolution network to regress 3D face coordinates. Our method directly performs feature learning on the 3D face mesh, where the geometric structure and details are well preserved. Extensive experiments show that our approach gains superior performance over state-of-the-art methods on several challenging datasets.