 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContour Field based Elliptical Shape Prior for the Segment Anything Model
Apr 17, 2025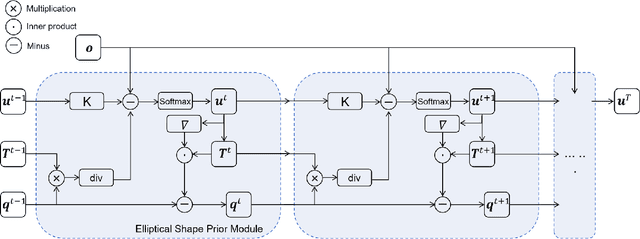

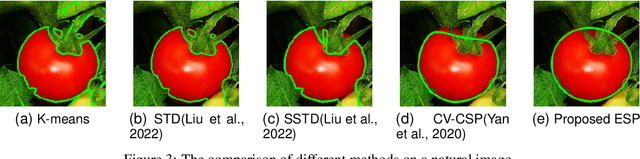
The elliptical shape prior information plays a vital role in improving the accuracy of image segmentation for specific tasks in medical and natural images. Existing deep learning-based segmentation methods, including the Segment Anything Model (SAM), often struggle to produce segmentation results with elliptical shapes efficiently. This paper proposes a new approach to integrate the prior of elliptical shapes into the deep learning-based SAM image segmentation techniques using variational methods. The proposed method establishes a parameterized elliptical contour field, which constrains the segmentation results to align with predefined elliptical contours. Utilizing the dual algorithm, the model seamlessly integrates image features with elliptical priors and spatial regularization priors, thereby greatly enhancing segmentation accuracy. By decomposing SAM into four mathematical sub-problems, we integrate the variational ellipse prior to design a new SAM network structure, ensuring that the segmentation output of SAM consists of elliptical regions. Experimental results on some specific image datasets demonstrate an improvement over the original SAM.
Slender Object Scene Segmentation in Remote Sensing Image Based on Learnable Morphological Skeleton with Segment Anything Model
Nov 13, 2024



Morphological methods play a crucial role in remote sensing image processing, due to their ability to capture and preserve small structural details. However, most of the existing deep learning models for semantic segmentation are based on the encoder-decoder architecture including U-net and Segment Anything Model (SAM), where the downsampling process tends to discard fine details. In this paper, we propose a new approach that integrates learnable morphological skeleton prior into deep neural networks using the variational method. To address the difficulty in backpropagation in neural networks caused by the non-differentiability presented in classical morphological operations, we provide a smooth representation of the morphological skeleton and design a variational segmentation model integrating morphological skeleton prior by employing operator splitting and dual methods. Then, we integrate this model into the network architecture of SAM, which is achieved by adding a token to mask decoder and modifying the final sigmoid layer, ensuring the final segmentation results preserve the skeleton structure as much as possible. Experimental results on remote sensing datasets, including buildings and roads, demonstrate that our method outperforms the original SAM on slender object segmentation and exhibits better generalization capability.
An inexact Bregman proximal point method and its acceleration version for unbalanced optimal transport
Feb 26, 2024



The Unbalanced Optimal Transport (UOT) problem plays increasingly important roles in computational biology, computational imaging and deep learning. Scaling algorithm is widely used to solve UOT due to its convenience and good convergence properties. However, this algorithm has lower accuracy for large regularization parameters, and due to stability issues, small regularization parameters can easily lead to numerical overflow. We address this challenge by developing an inexact Bregman proximal point method for solving UOT. This algorithm approximates the proximal operator using the Scaling algorithm at each iteration. The algorithm (1) converges to the true solution of UOT, (2) has theoretical guarantees and robust regularization parameter selection, (3) mitigates numerical stability issues, and (4) can achieve comparable computational complexity to the Scaling algorithm in specific practice. Building upon this, we develop an accelerated version of inexact Bregman proximal point method for solving UOT by using acceleration techniques of Bregman proximal point method and provide theoretical guarantees and experimental validation of convergence and acceleration.
XFormer: Fast and Accurate Monocular 3D Body Capture
May 18, 2023We present XFormer, a novel human mesh and motion capture method that achieves real-time performance on consumer CPUs given only monocular images as input. The proposed network architecture contains two branches: a keypoint branch that estimates 3D human mesh vertices given 2D keypoints, and an image branch that makes predictions directly from the RGB image features. At the core of our method is a cross-modal transformer block that allows information to flow across these two branches by modeling the attention between 2D keypoint coordinates and image spatial features. Our architecture is smartly designed, which enables us to train on various types of datasets including images with 2D/3D annotations, images with 3D pseudo labels, and motion capture datasets that do not have associated images. This effectively improves the accuracy and generalization ability of our system. Built on a lightweight backbone (MobileNetV3), our method runs blazing fast (over 30fps on a single CPU core) and still yields competitive accuracy. Furthermore, with an HRNet backbone, XFormer delivers state-of-the-art performance on Huamn3.6 and 3DPW datasets.
Human MotionFormer: Transferring Human Motions with Vision Transformers
Feb 25, 2023



Human motion transfer aims to transfer motions from a target dynamic person to a source static one for motion synthesis. An accurate matching between the source person and the target motion in both large and subtle motion changes is vital for improving the transferred motion quality. In this paper, we propose Human MotionFormer, a hierarchical ViT framework that leverages global and local perceptions to capture large and subtle motion matching, respectively. It consists of two ViT encoders to extract input features (i.e., a target motion image and a source human image) and a ViT decoder with several cascaded blocks for feature matching and motion transfer. In each block, we set the target motion feature as Query and the source person as Key and Value, calculating the cross-attention maps to conduct a global feature matching. Further, we introduce a convolutional layer to improve the local perception after the global cross-attention computations. This matching process is implemented in both warping and generation branches to guide the motion transfer. During training, we propose a mutual learning loss to enable the co-supervision between warping and generation branches for better motion representations. Experiments show that our Human MotionFormer sets the new state-of-the-art performance both qualitatively and quantitatively. Project page: \url{https://github.com/KumapowerLIU/Human-MotionFormer}
Normalized Cut with Adaptive Similarity and Spatial Regularization
Jun 06, 2018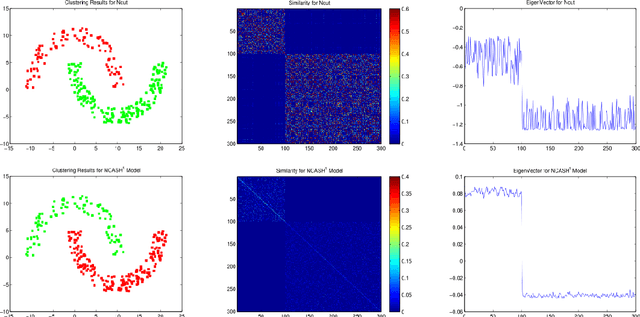
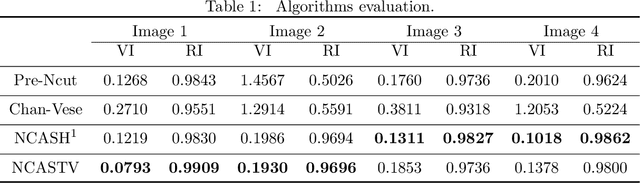
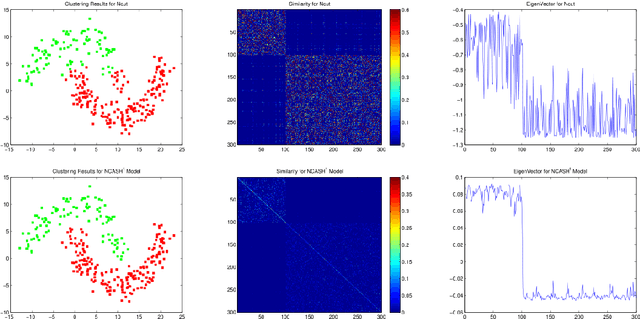
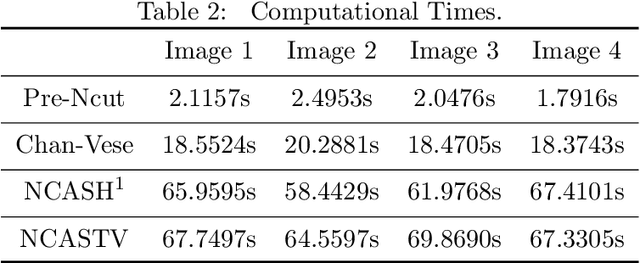
In this paper, we propose a normalized cut segmentation algorithm with spatial regularization priority and adaptive similarity matrix. We integrate the well-known expectation-maximum(EM) method in statistics and the regularization technique in partial differential equation (PDE) method into normalized cut (Ncut). The introduced EM technique makes our method can adaptively update the similarity matrix, which can help us to get a better classification criterion than the classical Ncut method. While the regularization priority can guarantee the proposed algorithm has a robust performance under noise. To unify the three totally different methods including EM, spatial regularization, and spectral graph clustering, we built a variational framework to combine them and get a general normalized cut segmentation algorithm. The well-defined theory of the proposed model is also given in the paper. Compared with some existing spectral clustering methods such as the traditional Ncut algorithm and the variational based Chan-Vese model, the numerical experiments show that our methods can achieve promising segmentation performance.
Variational based Mixed Noise Removal with CNN Deep Learning Regularization
May 21, 2018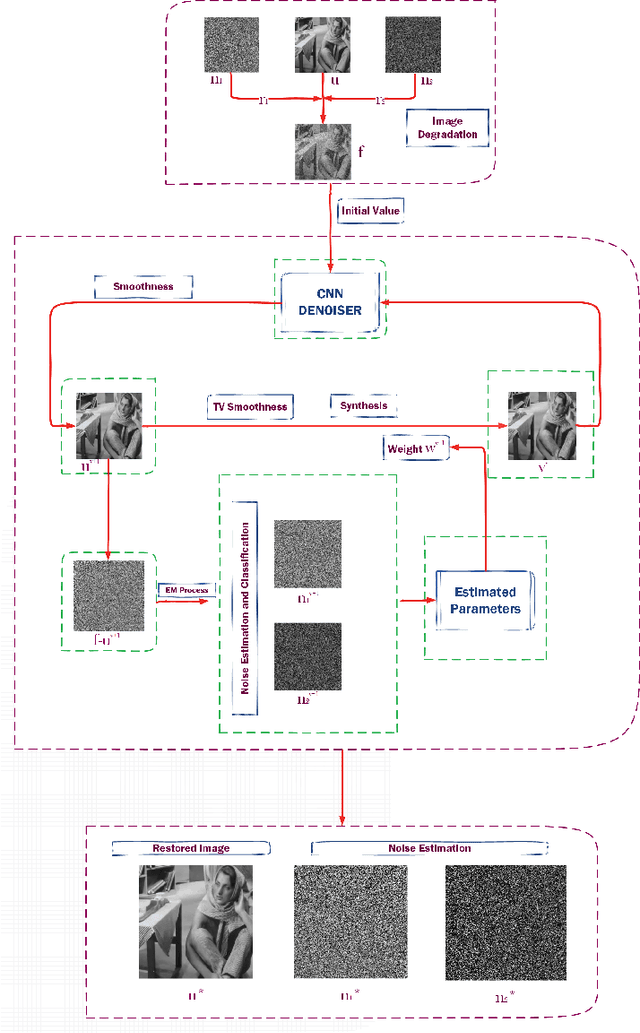



In this paper, the traditional model based variational method and learning based algorithms are naturally integrated to address mixed noise removal problem. To be different from single type noise (e.g. Gaussian) removal, it is a challenge problem to accurately discriminate noise types and levels for each pixel. We propose a variational method to iteratively estimate the noise parameters, and then the algorithm can automatically classify the noise according to the different statistical parameters. The proposed variational problem can be separated into regularization, synthesis, parameter estimation and noise classification four steps with the operator splitting scheme. Each step is related to an optimization subproblem. To enforce the regularization, the deep learning method is employed to learn the natural images priori. Compared with some model based regularizations, the CNN regularizer can significantly improve the quality of the restored images. Compared with some learning based methods, the synthesis step can produce better reconstructions by analyzing the recognized noise types and levels. In our method, the convolution neutral network (CNN) can be regarded as an operator which associated to a variational functional. From this viewpoint, the proposed method can be extended to many image reconstruction and inverse problems. Numerical experiments in the paper show that our method can achieve some state-of-the-art results for mixed noise removal.
Metric Learning with Dynamically Generated Pairwise Constraints for Ear Recognition
Mar 26, 2018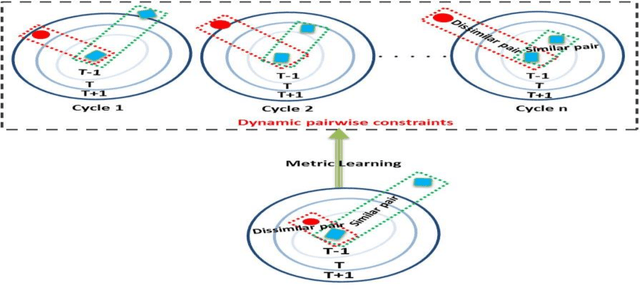
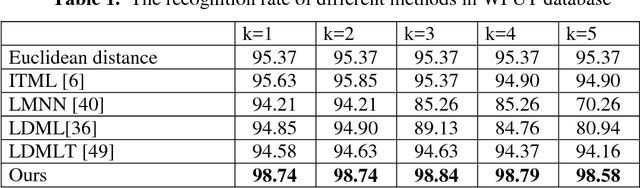
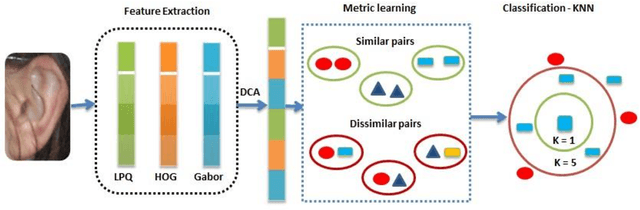
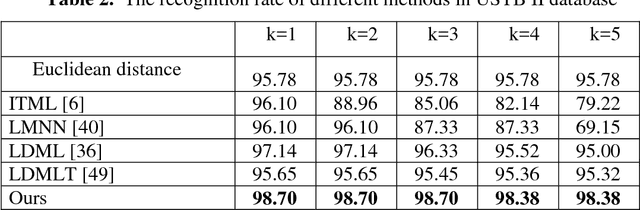
Ear recognition task is known as predicting whether two ear images belong to the same person or not. In this paper, we present a novel metric learning method for ear recognition. This method is formulated as a pairwise constrained optimization problem. In each training cycle, this method selects the nearest similar and dissimilar neighbors of each sample to construct the pairwise constraints, and then solve the optimization problem by the iterated Bregman projections. Experiments are conducted on AMI, USTB II and WPUT databases. The results show that the proposed approach can achieve promising recognition rates in ear recognition, and its training process is much more efficient than the other competing metric learning methods.
Iterated Support Vector Machines for Distance Metric Learning
Feb 02, 2015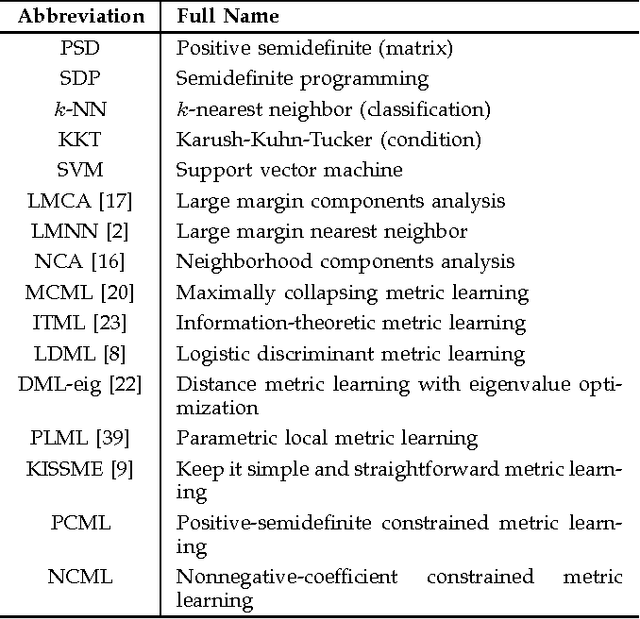
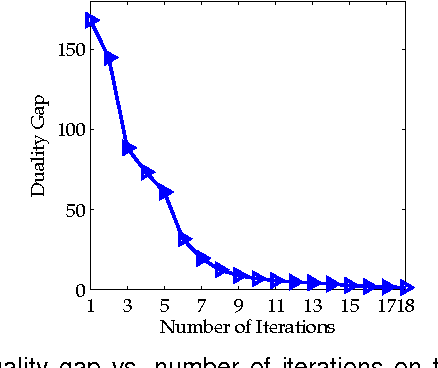
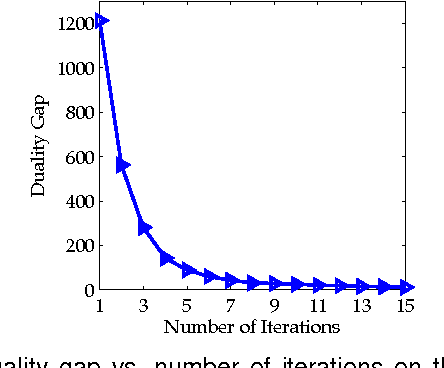
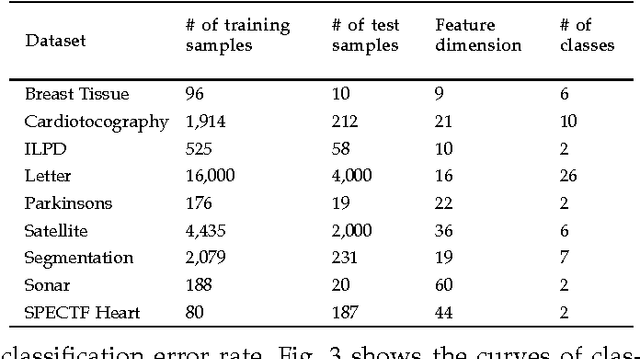
Distance metric learning aims to learn from the given training data a valid distance metric, with which the similarity between data samples can be more effectively evaluated for classification. Metric learning is often formulated as a convex or nonconvex optimization problem, while many existing metric learning algorithms become inefficient for large scale problems. In this paper, we formulate metric learning as a kernel classification problem, and solve it by iterated training of support vector machines (SVM). The new formulation is easy to implement, efficient in training, and tractable for large-scale problems. Two novel metric learning models, namely Positive-semidefinite Constrained Metric Learning (PCML) and Nonnegative-coefficient Constrained Metric Learning (NCML), are developed. Both PCML and NCML can guarantee the global optimality of their solutions. Experimental results on UCI dataset classification, handwritten digit recognition, face verification and person re-identification demonstrate that the proposed metric learning methods achieve higher classification accuracy than state-of-the-art methods and they are significantly more efficient in training.
A Kernel Classification Framework for Metric Learning
Sep 23, 2013
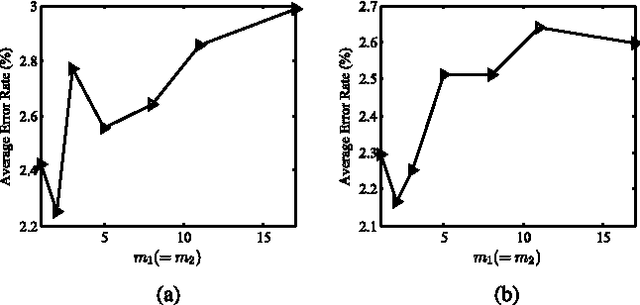


Learning a distance metric from the given training samples plays a crucial role in many machine learning tasks, and various models and optimization algorithms have been proposed in the past decade. In this paper, we generalize several state-of-the-art metric learning methods, such as large margin nearest neighbor (LMNN) and information theoretic metric learning (ITML), into a kernel classification framework. First, doublets and triplets are constructed from the training samples, and a family of degree-2 polynomial kernel functions are proposed for pairs of doublets or triplets. Then, a kernel classification framework is established, which can not only generalize many popular metric learning methods such as LMNN and ITML, but also suggest new metric learning methods, which can be efficiently implemented, interestingly, by using the standard support vector machine (SVM) solvers. Two novel metric learning methods, namely doublet-SVM and triplet-SVM, are then developed under the proposed framework. Experimental results show that doublet-SVM and triplet-SVM achieve competitive classification accuracies with state-of-the-art metric learning methods such as ITML and LMNN but with significantly less training time.