 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rashomon Effect for Visualizing High-Dimensional Data
Apr 01, 2026Dimension reduction (DR) is inherently non-unique: multiple embeddings can preserve the structure of high-dimensional data equally well while differing in layout or geometry. In this paper, we formally define the Rashomon set for DR -- the collection of `good' embedding -- and show how embracing this multiplicity leads to more powerful and trustworthy representations. Specifically, we pursue three goals. First, we introduce PCA-informed alignment to steer embeddings toward principal components, making axes interpretable without distorting local neighborhoods. Second, we design concept-alignment regularization that aligns an embedding dimension with external knowledge, such as class labels or user-defined concepts. Third, we propose a method to extract common knowledge across the Rashomon set by identifying trustworthy and persistent nearest-neighbor relationships, which we use to construct refined embeddings with improved local structure while preserving global relationships. By moving beyond a single embedding and leveraging the Rashomon set, we provide a flexible framework for building interpretable, robust, and goal-aligned visualizations.
It's LIT! Reliability-Optimized LLMs with Inspectable Tools
Nov 18, 2025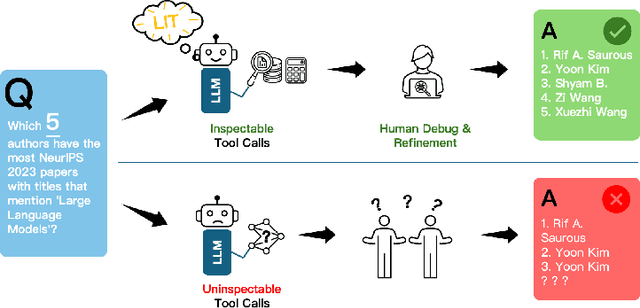
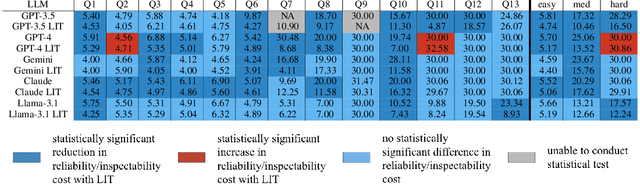
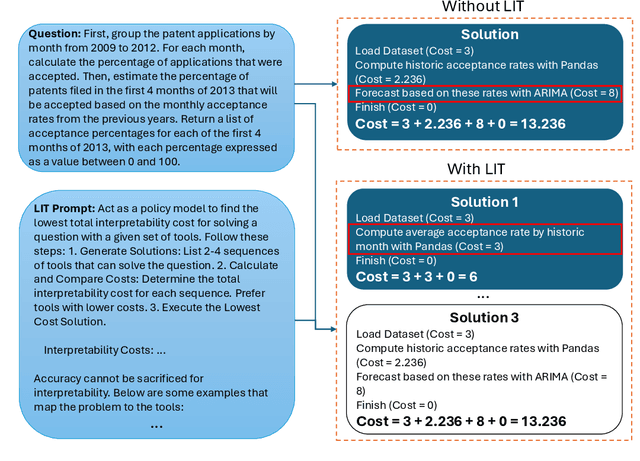
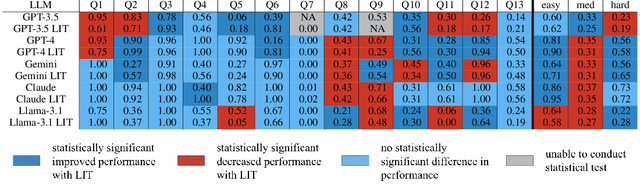
Large language models (LLMs) have exhibited remarkable capabilities across various domains. The ability to call external tools further expands their capability to handle real-world tasks. However, LLMs often follow an opaque reasoning process, which limits their usefulness in high-stakes domains where solutions need to be trustworthy to end users. LLMs can choose solutions that are unreliable and difficult to troubleshoot, even if better options are available. We address this issue by forcing LLMs to use external -- more reliable -- tools to solve problems when possible. We present a framework built on the tool-calling capabilities of existing LLMs to enable them to select the most reliable and easy-to-troubleshoot solution path, which may involve multiple sequential tool calls. We refer to this framework as LIT (LLMs with Inspectable Tools). In order to support LIT, we introduce a new and challenging benchmark dataset of 1,300 questions and a customizable set of reliability cost functions associated with a collection of specialized tools. These cost functions summarize how reliable each tool is and how easy it is to troubleshoot. For instance, a calculator is reliable across domains, whereas a linear prediction model is not reliable if there is distribution shift, but it is easy to troubleshoot. A tool that constructs a random forest is neither reliable nor easy to troubleshoot. These tools interact with the Harvard USPTO Patent Dataset and a new dataset of NeurIPS 2023 papers to solve mathematical, coding, and modeling problems of varying difficulty levels. We demonstrate that LLMs can achieve more reliable and informed problem-solving while maintaining task performance using our framework.
Joint Optimization of Prompt Security and System Performance in Edge-Cloud LLM Systems
Jan 30, 2025



Large language models (LLMs) have significantly facilitated human life, and prompt engineering has improved the efficiency of these models. However, recent years have witnessed a rise in prompt engineering-empowered attacks, leading to issues such as privacy leaks, increased latency, and system resource wastage. Though safety fine-tuning based methods with Reinforcement Learning from Human Feedback (RLHF) are proposed to align the LLMs, existing security mechanisms fail to cope with fickle prompt attacks, highlighting the necessity of performing security detection on prompts. In this paper, we jointly consider prompt security, service latency, and system resource optimization in Edge-Cloud LLM (EC-LLM) systems under various prompt attacks. To enhance prompt security, a vector-database-enabled lightweight attack detector is proposed. We formalize the problem of joint prompt detection, latency, and resource optimization into a multi-stage dynamic Bayesian game model. The equilibrium strategy is determined by predicting the number of malicious tasks and updating beliefs at each stage through Bayesian updates. The proposed scheme is evaluated on a real implemented EC-LLM system, and the results demonstrate that our approach offers enhanced security, reduces the service latency for benign users, and decreases system resource consumption compared to state-of-the-art algorithms.
DC-PCN: Point Cloud Completion Network with Dual-Codebook Guided Quantization
Jan 19, 2025Point cloud completion aims to reconstruct complete 3D shapes from partial 3D point clouds. With advancements in deep learning techniques, various methods for point cloud completion have been developed. Despite achieving encouraging results, a significant issue remains: these methods often overlook the variability in point clouds sampled from a single 3D object surface. This variability can lead to ambiguity and hinder the achievement of more precise completion results. Therefore, in this study, we introduce a novel point cloud completion network, namely Dual-Codebook Point Completion Network (DC-PCN), following an encder-decoder pipeline. The primary objective of DC-PCN is to formulate a singular representation of sampled point clouds originating from the same 3D surface. DC-PCN introduces a dual-codebook design to quantize point-cloud representations from a multilevel perspective. It consists of an encoder-codebook and a decoder-codebook, designed to capture distinct point cloud patterns at shallow and deep levels. Additionally, to enhance the information flow between these two codebooks, we devise an information exchange mechanism. This approach ensures that crucial features and patterns from both shallow and deep levels are effectively utilized for completion. Extensive experiments on the PCN, ShapeNet\_Part, and ShapeNet34 datasets demonstrate the state-of-the-art performance of our method.
Dimension Reduction with Locally Adjusted Graphs
Dec 19, 2024Dimension reduction (DR) algorithms have proven to be extremely useful for gaining insight into large-scale high-dimensional datasets, particularly finding clusters in transcriptomic data. The initial phase of these DR methods often involves converting the original high-dimensional data into a graph. In this graph, each edge represents the similarity or dissimilarity between pairs of data points. However, this graph is frequently suboptimal due to unreliable high-dimensional distances and the limited information extracted from the high-dimensional data. This problem is exacerbated as the dataset size increases. If we reduce the size of the dataset by selecting points for a specific sections of the embeddings, the clusters observed through DR are more separable since the extracted subgraphs are more reliable. In this paper, we introduce LocalMAP, a new dimensionality reduction algorithm that dynamically and locally adjusts the graph to address this challenge. By dynamically extracting subgraphs and updating the graph on-the-fly, LocalMAP is capable of identifying and separating real clusters within the data that other DR methods may overlook or combine. We demonstrate the benefits of LocalMAP through a case study on biological datasets, highlighting its utility in helping users more accurately identify clusters for real-world problems.
Navigating the Effect of Parametrization for Dimensionality Reduction
Nov 24, 2024Parametric dimensionality reduction methods have gained prominence for their ability to generalize to unseen datasets, an advantage that traditional approaches typically lack. Despite their growing popularity, there remains a prevalent misconception among practitioners about the equivalence in performance between parametric and non-parametric methods. Here, we show that these methods are not equivalent -- parametric methods retain global structure but lose significant local details. To explain this, we provide evidence that parameterized approaches lack the ability to repulse negative pairs, and the choice of loss function also has an impact. Addressing these issues, we developed a new parametric method, ParamRepulsor, that incorporates Hard Negative Mining and a loss function that applies a strong repulsive force. This new method achieves state-of-the-art performance on local structure preservation for parametric methods without sacrificing the fidelity of global structural representation. Our code is available at https://github.com/hyhuang00/ParamRepulsor.
Towards MoE Deployment: Mitigating Inefficiencies in Mixture-of-Expert (MoE) Inference
Mar 10, 2023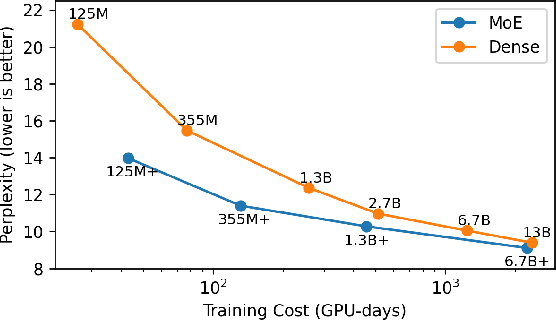
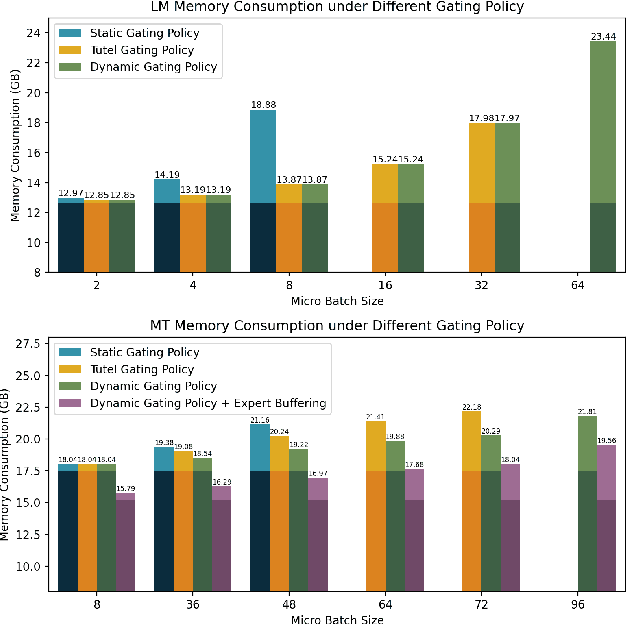
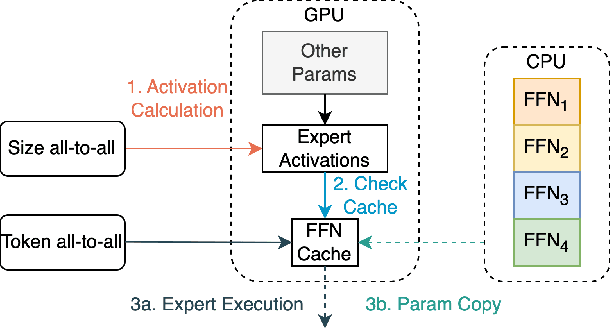
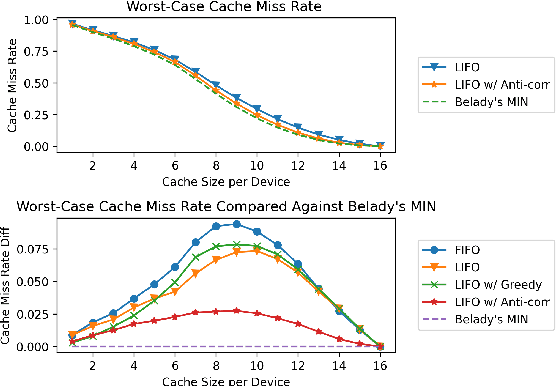
Mixture-of-Experts (MoE) models have recently gained steam in achieving the state-of-the-art performance in a wide range of tasks in computer vision and natural language processing. They effectively expand the model capacity while incurring a minimal increase in computation cost during training. However, deploying such models for inference is difficult due to their large model size and complex communication pattern. In this work, we provide a characterization of two MoE workloads, namely Language Modeling (LM) and Machine Translation (MT) and identify their sources of inefficiencies at deployment. We propose three optimization techniques to mitigate sources of inefficiencies, namely (1) Dynamic gating, (2) Expert Buffering, and (3) Expert load balancing. We show that dynamic gating improves execution time by 1.25-4$\times$ for LM, 2-5$\times$ for MT Encoder and 1.09-1.5$\times$ for MT Decoder. It also reduces memory usage by up to 1.36$\times$ for LM and up to 1.1$\times$ for MT. We further propose Expert Buffering, a new caching mechanism that only keeps hot, active experts in GPU memory while buffering the rest in CPU memory. This reduces static memory allocation by 1.47$\times$. We finally propose a load balancing methodology that provides additional robustness to the workload. The code will be open-sourced upon acceptance.
SegDiscover: Visual Concept Discovery via Unsupervised Semantic Segmentation
Apr 22, 2022Visual concept discovery has long been deemed important to improve interpretability of neural networks, because a bank of semantically meaningful concepts would provide us with a starting point for building machine learning models that exhibit intelligible reasoning process. Previous methods have disadvantages: either they rely on labelled support sets that incorporate human biases for objects that are "useful," or they fail to identify multiple concepts that occur within a single image. We reframe the concept discovery task as an unsupervised semantic segmentation problem, and present SegDiscover, a novel framework that discovers semantically meaningful visual concepts from imagery datasets with complex scenes without supervision. Our method contains three important pieces: generating concept primitives from raw images, discovering concepts by clustering in the latent space of a self-supervised pretrained encoder, and concept refinement via neural network smoothing. Experimental results provide evidence that our method can discover multiple concepts within a single image and outperforms state-of-the-art unsupervised methods on complex datasets such as Cityscapes and COCO-Stuff. Our method can be further used as a neural network explanation tool by comparing results obtained by different encoders.
Interpretable Machine Learning: Fundamental Principles and 10 Grand Challenges
Mar 20, 2021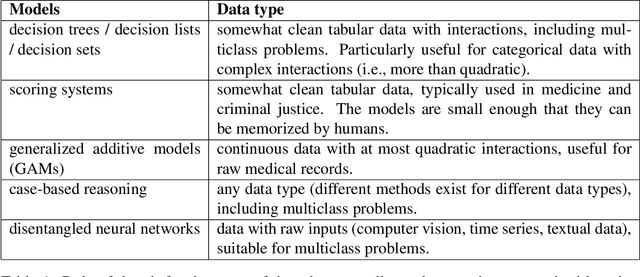
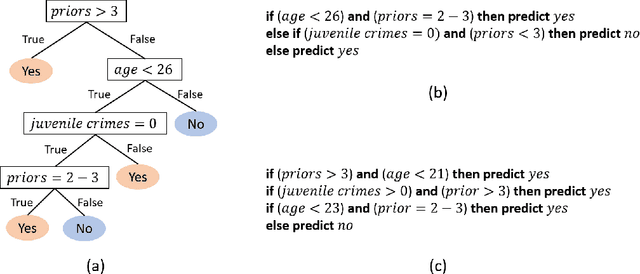
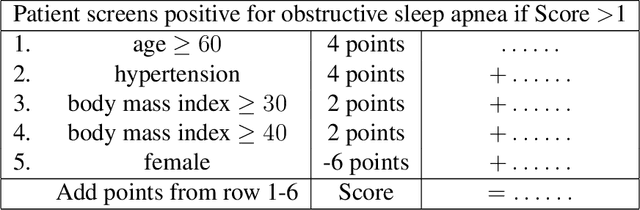
Interpretability in machine learning (ML) is crucial for high stakes decisions and troubleshooting. In this work, we provide fundamental principles for interpretable ML, and dispel common misunderstandings that dilute the importance of this crucial topic. We also identify 10 technical challenge areas in interpretable machine learning and provide history and background on each problem. Some of these problems are classically important, and some are recent problems that have arisen in the last few years. These problems are: (1) Optimizing sparse logical models such as decision trees; (2) Optimization of scoring systems; (3) Placing constraints into generalized additive models to encourage sparsity and better interpretability; (4) Modern case-based reasoning, including neural networks and matching for causal inference; (5) Complete supervised disentanglement of neural networks; (6) Complete or even partial unsupervised disentanglement of neural networks; (7) Dimensionality reduction for data visualization; (8) Machine learning models that can incorporate physics and other generative or causal constraints; (9) Characterization of the "Rashomon set" of good models; and (10) Interpretable reinforcement learning. This survey is suitable as a starting point for statisticians and computer scientists interested in working in interpretable machine learning.
Understanding How Dimension Reduction Tools Work: An Empirical Approach to Deciphering t-SNE, UMAP, TriMAP, and PaCMAP for Data Visualization
Dec 08, 2020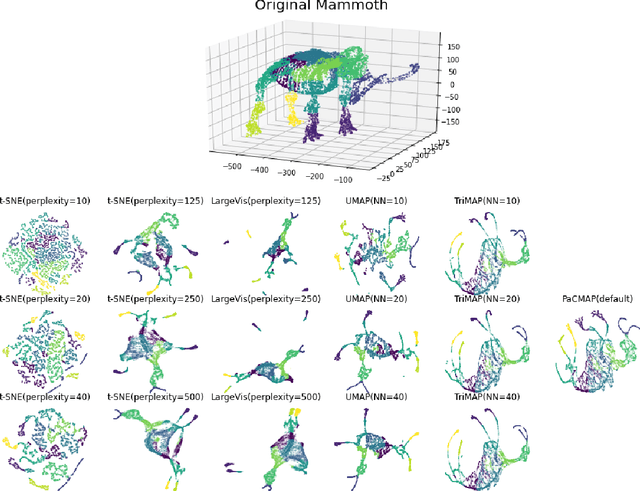

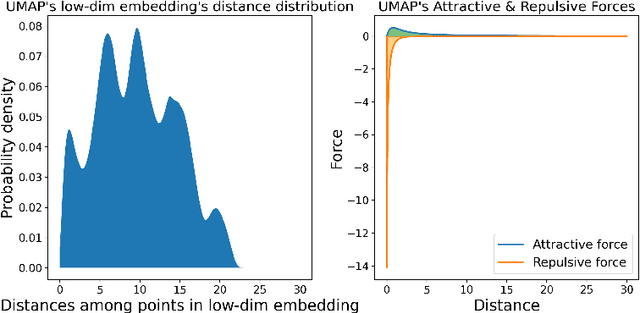
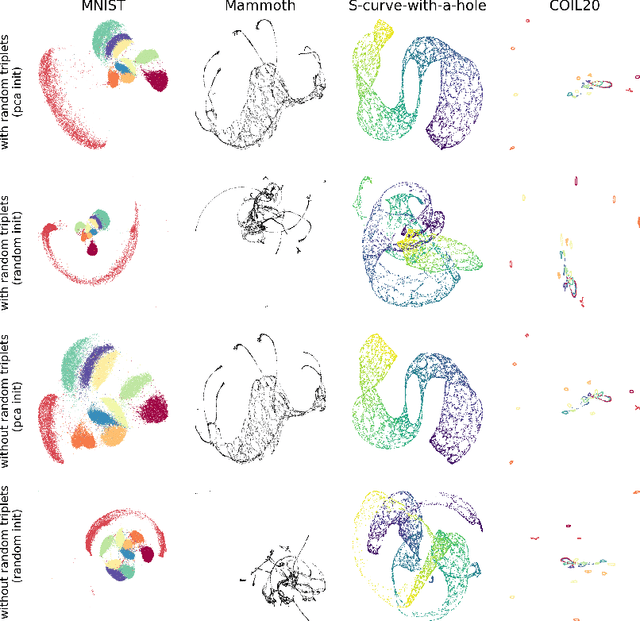
Dimension reduction (DR) techniques such as t-SNE, UMAP, and TriMAP have demonstrated impressive visualization performance on many real world datasets. One tension that has always faced these methods is the trade-off between preservation of global structure and preservation of local structure: these methods can either handle one or the other, but not both. In this work, our main goal is to understand what aspects of DR methods are important for preserving both local and global structure: it is difficult to design a better method without a true understanding of the choices we make in our algorithms and their empirical impact on the lower-dimensional embeddings they produce. Towards the goal of local structure preservation, we provide several useful design principles for DR loss functions based on our new understanding of the mechanisms behind successful DR methods. Towards the goal of global structure preservation, our analysis illuminates that the choice of which components to preserve is important. We leverage these insights to design a new algorithm for DR, called Pairwise Controlled Manifold Approximation Projection (PaCMAP), which preserves both local and global structure. Our work provides several unexpected insights into what design choices both to make and avoid when constructing DR algorithms.