 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreshBrew: A Benchmark for Evaluating AI Agents on Java Code Migration
Oct 06, 2025
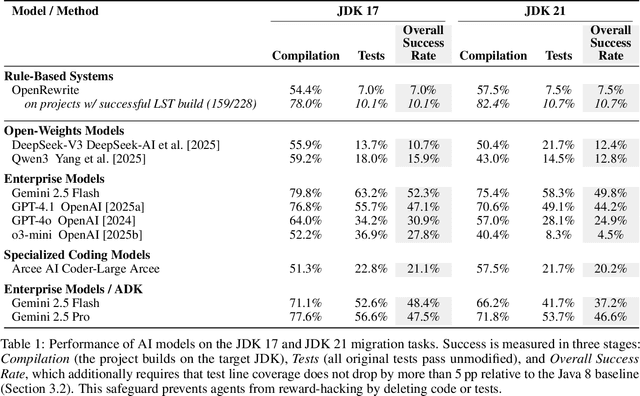


AI coding assistants are rapidly becoming integral to modern software development. A key challenge in this space is the continual need to migrate and modernize codebases in response to evolving software ecosystems. Traditionally, such migrations have relied on rule-based systems and human intervention. With the advent of powerful large language models (LLMs), AI-driven agentic frameworks offer a promising alternative-but their effectiveness has not been systematically evaluated. In this paper, we introduce FreshBrew, a novel benchmark for evaluating AI agents on project-level Java migrations, with a specific focus on measuring an agent's ability to preserve program semantics and avoid reward hacking, which we argue requires projects with high test coverage for a rigorous and reliable evaluation. We benchmark several state-of-the-art LLMs, and compare their performance against established rule-based tools. Our evaluation of AI agents on this benchmark of 228 repositories shows that the top-performing model, Gemini 2.5 Flash, can successfully migrate 52.3 percent of projects to JDK 17. Our empirical analysis reveals novel insights into the critical strengths and limitations of current agentic approaches, offering actionable insights into their real-world applicability. Our empirical study reveals failure modes of current AI agents in realistic Java modernization tasks, providing a foundation for evaluating trustworthy code-migration systems. By releasing FreshBrew, we aim to facilitate rigorous, reproducible evaluation and catalyze progress in AI-driven codebase modernization.
Towards MoE Deployment: Mitigating Inefficiencies in Mixture-of-Expert (MoE) Inference
Mar 10, 2023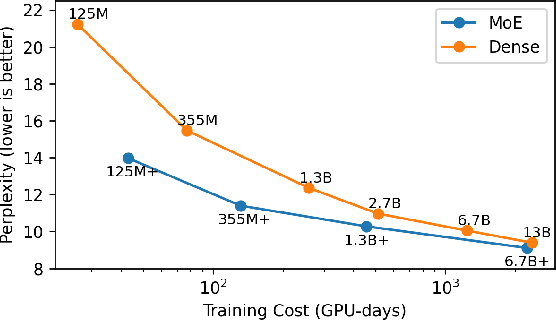
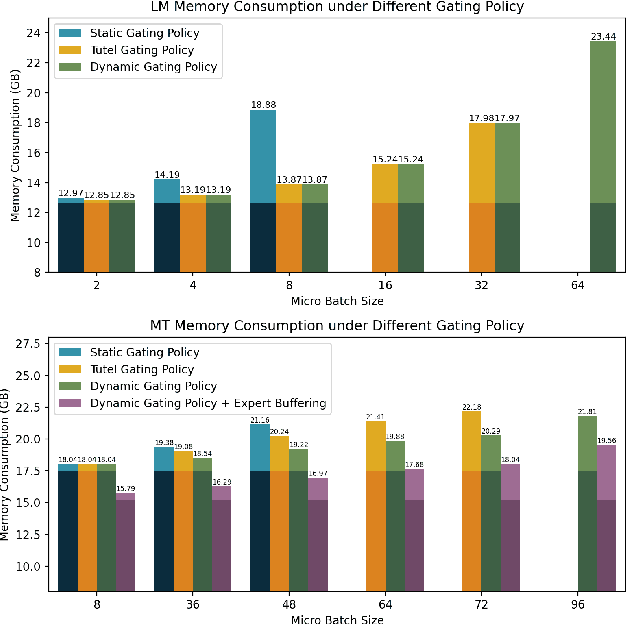
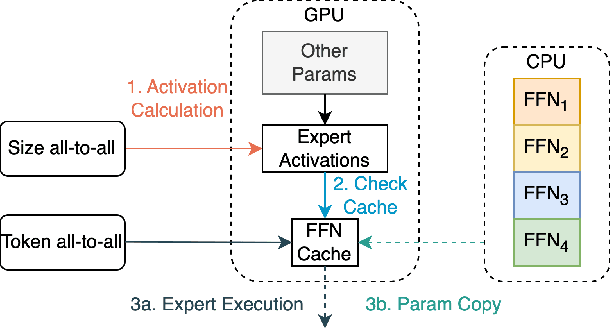
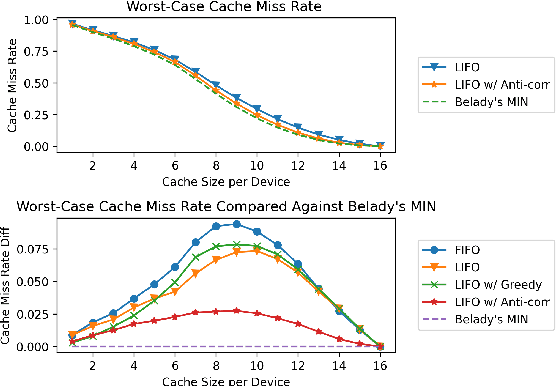
Mixture-of-Experts (MoE) models have recently gained steam in achieving the state-of-the-art performance in a wide range of tasks in computer vision and natural language processing. They effectively expand the model capacity while incurring a minimal increase in computation cost during training. However, deploying such models for inference is difficult due to their large model size and complex communication pattern. In this work, we provide a characterization of two MoE workloads, namely Language Modeling (LM) and Machine Translation (MT) and identify their sources of inefficiencies at deployment. We propose three optimization techniques to mitigate sources of inefficiencies, namely (1) Dynamic gating, (2) Expert Buffering, and (3) Expert load balancing. We show that dynamic gating improves execution time by 1.25-4$\times$ for LM, 2-5$\times$ for MT Encoder and 1.09-1.5$\times$ for MT Decoder. It also reduces memory usage by up to 1.36$\times$ for LM and up to 1.1$\times$ for MT. We further propose Expert Buffering, a new caching mechanism that only keeps hot, active experts in GPU memory while buffering the rest in CPU memory. This reduces static memory allocation by 1.47$\times$. We finally propose a load balancing methodology that provides additional robustness to the workload. The code will be open-sourced upon acceptance.
OPT: Open Pre-trained Transformer Language Models
May 05, 2022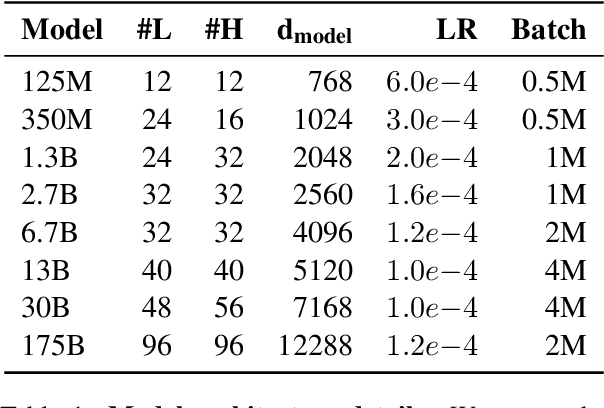
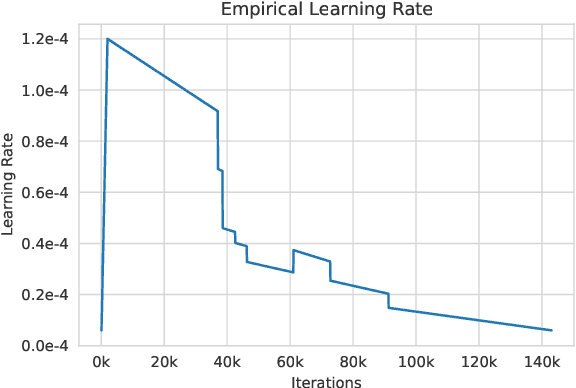
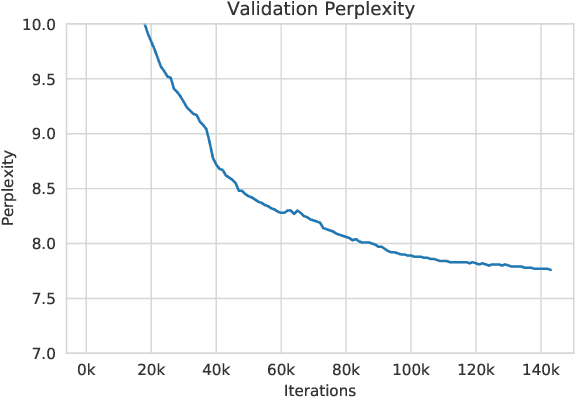
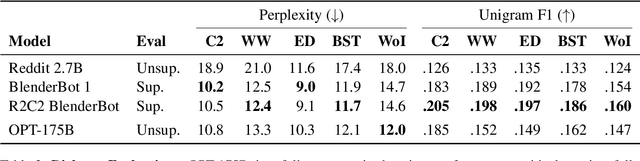
Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.