 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards MoE Deployment: Mitigating Inefficiencies in Mixture-of-Expert (MoE) Inference
Mar 10, 2023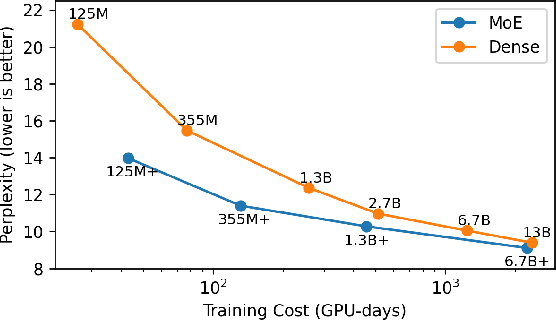
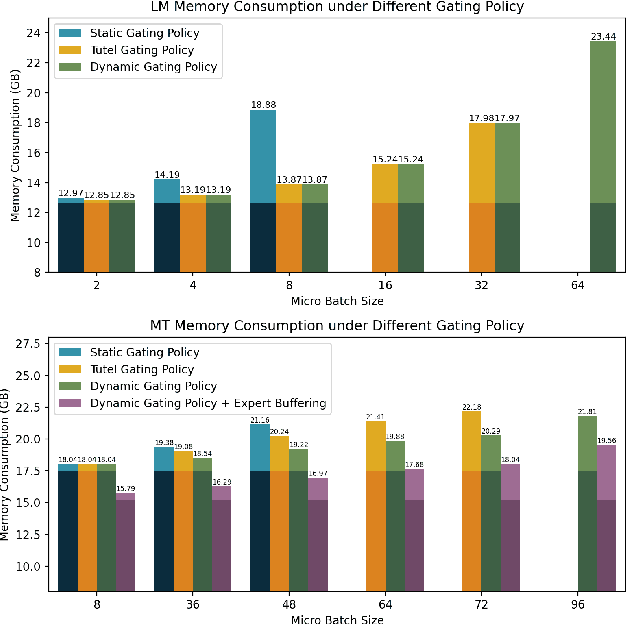
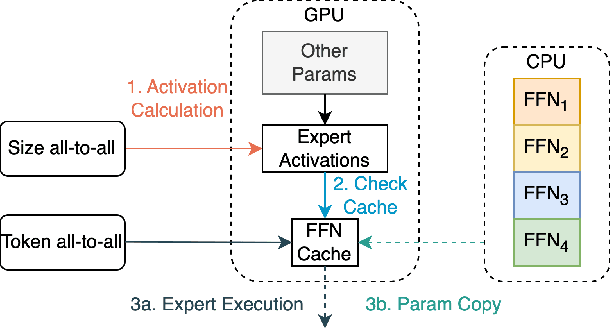
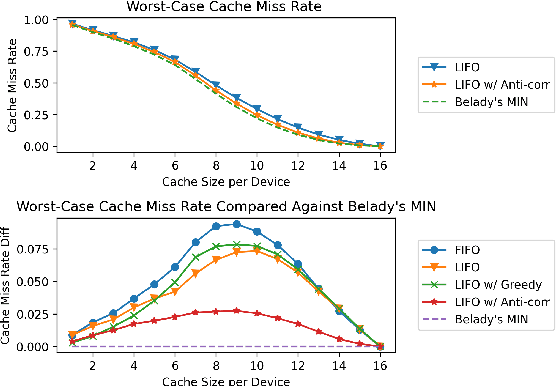
Mixture-of-Experts (MoE) models have recently gained steam in achieving the state-of-the-art performance in a wide range of tasks in computer vision and natural language processing. They effectively expand the model capacity while incurring a minimal increase in computation cost during training. However, deploying such models for inference is difficult due to their large model size and complex communication pattern. In this work, we provide a characterization of two MoE workloads, namely Language Modeling (LM) and Machine Translation (MT) and identify their sources of inefficiencies at deployment. We propose three optimization techniques to mitigate sources of inefficiencies, namely (1) Dynamic gating, (2) Expert Buffering, and (3) Expert load balancing. We show that dynamic gating improves execution time by 1.25-4$\times$ for LM, 2-5$\times$ for MT Encoder and 1.09-1.5$\times$ for MT Decoder. It also reduces memory usage by up to 1.36$\times$ for LM and up to 1.1$\times$ for MT. We further propose Expert Buffering, a new caching mechanism that only keeps hot, active experts in GPU memory while buffering the rest in CPU memory. This reduces static memory allocation by 1.47$\times$. We finally propose a load balancing methodology that provides additional robustness to the workload. The code will be open-sourced upon acceptance.
Data Leakage via Access Patterns of Sparse Features in Deep Learning-based Recommendation Systems
Dec 12, 2022Online personalized recommendation services are generally hosted in the cloud where users query the cloud-based model to receive recommended input such as merchandise of interest or news feed. State-of-the-art recommendation models rely on sparse and dense features to represent users' profile information and the items they interact with. Although sparse features account for 99% of the total model size, there was not enough attention paid to the potential information leakage through sparse features. These sparse features are employed to track users' behavior, e.g., their click history, object interactions, etc., potentially carrying each user's private information. Sparse features are represented as learned embedding vectors that are stored in large tables, and personalized recommendation is performed by using a specific user's sparse feature to index through the tables. Even with recently-proposed methods that hides the computation happening in the cloud, an attacker in the cloud may be able to still track the access patterns to the embedding tables. This paper explores the private information that may be learned by tracking a recommendation model's sparse feature access patterns. We first characterize the types of attacks that can be carried out on sparse features in recommendation models in an untrusted cloud, followed by a demonstration of how each of these attacks leads to extracting users' private information or tracking users by their behavior over time.
Neural Network-Inspired Analog-to-Digital Conversion to Achieve Super-Resolution with Low-Precision RRAM Devices
Nov 28, 2019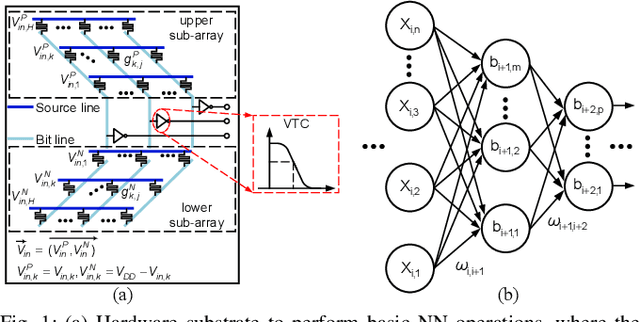
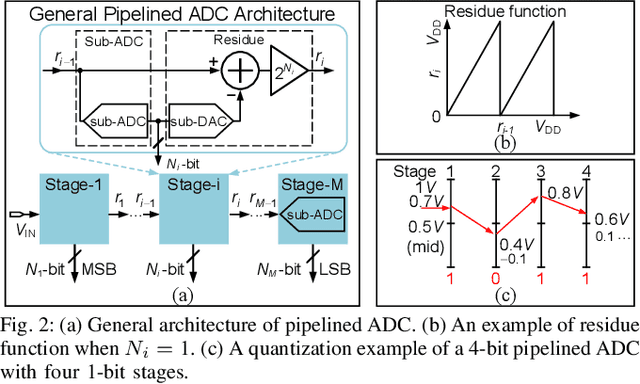
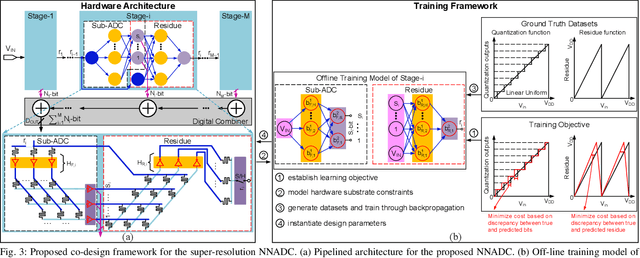
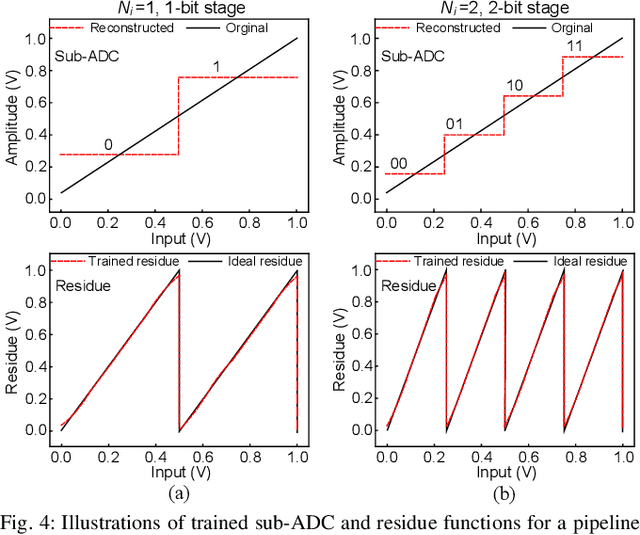
Recent works propose neural network- (NN-) inspired analog-to-digital converters (NNADCs) and demonstrate their great potentials in many emerging applications. These NNADCs often rely on resistive random-access memory (RRAM) devices to realize the NN operations and require high-precision RRAM cells (6~12-bit) to achieve a moderate quantization resolution (4~8-bit). Such optimistic assumption of RRAM resolution, however, is not supported by fabrication data of RRAM arrays in large-scale production process. In this paper, we propose an NN-inspired super-resolution ADC based on low-precision RRAM devices by taking the advantage of a co-design methodology that combines a pipelined hardware architecture with a custom NN training framework. Results obtained from SPICE simulations demonstrate that our method leads to robust design of a 14-bit super-resolution ADC using 3-bit RRAM devices with improved power and speed performance and competitive figure-of-merits (FoMs). In addition to the linear uniform quantization, the proposed ADC can also support configurable high-resolution nonlinear quantization with high conversion speed and low conversion energy, enabling future intelligent analog-to-information interfaces for near-sensor analytics and processing.
AxTrain: Hardware-Oriented Neural Network Training for Approximate Inference
May 21, 2018
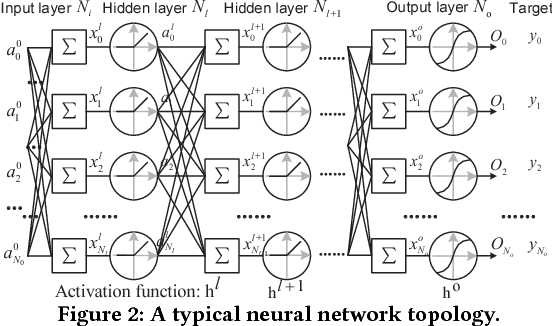


The intrinsic error tolerance of neural network (NN) makes approximate computing a promising technique to improve the energy efficiency of NN inference. Conventional approximate computing focuses on balancing the efficiency-accuracy trade-off for existing pre-trained networks, which can lead to suboptimal solutions. In this paper, we propose AxTrain, a hardware-oriented training framework to facilitate approximate computing for NN inference. Specifically, AxTrain leverages the synergy between two orthogonal methods---one actively searches for a network parameters distribution with high error tolerance, and the other passively learns resilient weights by numerically incorporating the noise distributions of the approximate hardware in the forward pass during the training phase. Experimental results from various datasets with near-threshold computing and approximation multiplication strategies demonstrate AxTrain's ability to obtain resilient neural network parameters and system energy efficiency improvement.