 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacySIM: Evaluating LLM Simulation of User Privacy Behavior
May 12, 2026Large language models (LLMs) are increasingly used to simulate human behavior, but their ability to simulate $individual$ privacy decisions is not well understood. In this paper, we address the problem of evaluating whether a core set of user persona attributes can drive LLMs to simulate individual-level privacy behavior. We introduce PrivacySIM, an evaluation suite that benchmarks LLM simulation of user privacy behavior against the ground-truth responses of 1,000 users. These users are drawn from five published user studies on privacy spanning LLM healthcare consultations, conversational agents, and chatbots. Drawing on these user studies, we hypothesize three persona facets as plausible predictors of privacy decision-making: demographics, previous experiences, and stated privacy attitudes. We condition nine frontier LLMs on subsets of these three facets and measure how often each model's response to a data-sharing scenario matches the user's actual response. Our findings show that (1) privacy persona conditioning consistently improves simulation quality over no-persona conditioning, but even the strongest model (40.4\% accuracy) remains far from faithfully simulating individual privacy decisions. (2) A user's stated privacy attitudes alone may not be the best predictor because they often diverge from the user's actual privacy behavior. (3) Users with high AI/chatbot experience but low stated privacy attitudes are the most challenging to simulate. PrivacySIM is a first step toward understanding and improving the capabilities of LLMs to simulate user privacy decisions. We release PrivacySIM to enable further evaluation of LLM privacy simulation.
Fast NF4 Dequantization Kernels for Large Language Model Inference
Apr 02, 2026Large language models (LLMs) have grown beyond the memory capacity of single GPU devices, necessitating quantization techniques for practical deployment. While NF4 (4-bit NormalFloat) quantization enables 4$\times$ memory reduction, inference on current NVIDIA GPUs (e.g., Ampere A100) requires expensive dequantization back to FP16 format, creating a critical performance bottleneck. This paper presents a lightweight shared memory optimization that addresses this gap through principled memory hierarchy exploitation while maintaining full ecosystem compatibility. We compare our technique against the open-source BitsAndBytes implementation, achieving 2.0--2.2$\times$ kernel speedup across three models (Gemma 27B, Qwen3 32B, and Llama3.3 70B) and up to 1.54$\times$ end-to-end improvement by leveraging the 12--15$\times$ latency advantage of shared memory over global memory access. Our optimization reduces instruction counts through simplified indexing logic while using only 64 bytes of shared memory per thread block, demonstrating that lightweight optimizations can deliver substantial performance gains with minimal engineering effort. This work provides a plug-and-play solution for the HuggingFace ecosystem that democratizes access to advanced models on existing GPU infrastructure.
Differentially Private Retrieval-Augmented Generation
Feb 16, 2026Retrieval-augmented generation (RAG) is a widely used framework for reducing hallucinations in large language models (LLMs) on domain-specific tasks by retrieving relevant documents from a database to support accurate responses. However, when the database contains sensitive corpora, such as medical records or legal documents, RAG poses serious privacy risks by potentially exposing private information through its outputs. Prior work has demonstrated that one can practically craft adversarial prompts that force an LLM to regurgitate the augmented contexts. A promising direction is to integrate differential privacy (DP), a privacy notion that offers strong formal guarantees, into RAG systems. However, naively applying DP mechanisms into existing systems often leads to significant utility degradation. Particularly for RAG systems, DP can reduce the usefulness of the augmented contexts leading to increase risk of hallucination from the LLMs. Motivated by these challenges, we present DP-KSA, a novel privacy-preserving RAG algorithm that integrates DP using the propose-test-release paradigm. DP-KSA follows from a key observation that most question-answering (QA) queries can be sufficiently answered with a few keywords. Hence, DP-KSA first obtains an ensemble of relevant contexts, each of which will be used to generate a response from an LLM. We utilize these responses to obtain the most frequent keywords in a differentially private manner. Lastly, the keywords are augmented into the prompt for the final output. This approach effectively compresses the semantic space while preserving both utility and privacy. We formally show that DP-KSA provides formal DP guarantees on the generated output with respect to the RAG database. We evaluate DP-KSA on two QA benchmarks using three instruction-tuned LLMs, and our empirical results demonstrate that DP-KSA achieves a strong privacy-utility tradeoff.
LRD-MPC: Efficient MPC Inference through Low-rank Decomposition
Feb 16, 2026Secure Multi-party Computation (MPC) enables untrusted parties to jointly compute a function without revealing their inputs. Its application to machine learning (ML) has gained significant attention, particularly for secure inference services deployed across multiple cloud virtual machines (VMs), where each VM acts as an MPC party. Model providers secret-share model weights, and users secret-share inputs, ensuring that each server operates only on random shares. While MPC provides strong cryptographic guarantees, it incurs substantial computational and communication overhead. Deep neural networks rely heavily on convolutional and fully connected layers, which require costly matrix multiplications in MPC. To reduce this cost, we propose leveraging low-rank decomposition (LRD) for linear layers, replacing one large matrix multiplication with two smaller ones. Each matrix multiplication in MPC incurs a round of communication, meaning decomposing one matrix multiplication into two leads to an additional communication round. Second, the added matrix multiplication requires an additional truncation step to maintain numerical precision. Since truncation itself requires communication and computation, these overheads can offset the gains from decomposition. To address this, we introduce two complementary optimizations: truncation skipping and efficient linear layer concatenation. Truncation skipping removes the extra truncation induced by LRD, while linear layer concatenation pipelines operations to hide the additional communication round. Together, these techniques mitigate the main overheads of LRD in MPC and improve overall efficiency. Our approach is broadly applicable across MPC protocols. Experiments show up to 25% speedup in n-PC and 33% in 3-PC protocols over full-rank baselines, along with up to 52% GPU energy savings and 88% reduction in offline-phase latency.
Striking the Right Balance between Compute and Copy: Improving LLM Inferencing Under Speculative Decoding
Nov 15, 2025With the skyrocketing costs of GPUs and their virtual instances in the cloud, there is a significant desire to use CPUs for large language model (LLM) inference. KV cache update, often implemented as allocation, copying, and in-place strided update for each generated token, incurs significant overhead. As the sequence length increases, the allocation and copy overheads dominate the performance. Alternate approaches may allocate large KV tensors upfront to enable in-place updates, but these matrices (with zero-padded rows) cause redundant computations. In this work, we propose a new KV cache allocation mechanism called Balancing Memory and Compute (BMC). BMC allocates, once every r iterations, KV tensors with r redundant rows, allowing in-place update without copy overhead for those iterations, but at the expense of a small amount of redundant computation. Second, we make an interesting observation that the extra rows allocated in the KV tensors and the resulting redundant computation can be repurposed for Speculative Decoding (SD) that improves token generation efficiency. Last, BMC represents a spectrum of design points with different values of r. To identify the best-performing design point(s), we derive a simple analytical model for BMC. The proposed BMC method achieves an average throughput acceleration of up to 3.2x over baseline HuggingFace (without SD). Importantly when we apply BMC with SD, it results in an additional speedup of up to 1.39x, over and above the speedup offered by SD. Further, BMC achieves a throughput acceleration of up to 1.36x and 2.29x over state-of-the-art inference servers vLLM and DeepSpeed, respectively. Although the BMC technique is evaluated extensively across different classes of CPUs (desktop and server class), we also evaluate the scheme with GPUs and demonstrate that it works well for GPUs.
DuetServe: Harmonizing Prefill and Decode for LLM Serving via Adaptive GPU Multiplexing
Nov 06, 2025Modern LLM serving systems must sustain high throughput while meeting strict latency SLOs across two distinct inference phases: compute-intensive prefill and memory-bound decode phases. Existing approaches either (1) aggregate both phases on shared GPUs, leading to interference between prefill and decode phases, which degrades time-between-tokens (TBT); or (2) disaggregate the two phases across GPUs, improving latency but wasting resources through duplicated models and KV cache transfers. We present DuetServe, a unified LLM serving framework that achieves disaggregation-level isolation within a single GPU. DuetServe operates in aggregated mode by default and dynamically activates SM-level GPU spatial multiplexing when TBT degradation is predicted. Its key idea is to decouple prefill and decode execution only when needed through fine-grained, adaptive SM partitioning that provides phase isolation only when contention threatens latency service level objectives (SLOs). DuetServe integrates (1) an attention-aware roofline model to forecast iteration latency, (2) a partitioning optimizer that selects the optimal SM split to maximize throughput under TBT constraints, and (3) an interruption-free execution engine that eliminates CPU-GPU synchronization overhead. Evaluations show that DuetServe improves total throughput by up to 1.3x while maintaining low generation latency compared to state-of-the-art frameworks.
Memory-Efficient Differentially Private Training with Gradient Random Projection
Jun 18, 2025Differential privacy (DP) protects sensitive data during neural network training, but standard methods like DP-Adam suffer from high memory overhead due to per-sample gradient clipping, limiting scalability. We introduce DP-GRAPE (Gradient RAndom ProjEction), a DP training method that significantly reduces memory usage while maintaining utility on par with first-order DP approaches. Rather than directly applying DP to GaLore, DP-GRAPE introduces three key modifications: (1) gradients are privatized after projection, (2) random Gaussian matrices replace SVD-based subspaces, and (3) projection is applied during backpropagation. These contributions eliminate the need for costly SVD computations, enable substantial memory savings, and lead to improved utility. Despite operating in lower-dimensional subspaces, our theoretical analysis shows that DP-GRAPE achieves a privacy-utility trade-off comparable to DP-SGD. Our extensive empirical experiments show that DP-GRAPE can reduce the memory footprint of DP training without sacrificing accuracy or training time. In particular, DP-GRAPE reduces memory usage by over 63% when pre-training Vision Transformers and over 70% when fine-tuning RoBERTa-Large as compared to DP-Adam, while achieving similar performance. We further demonstrate that DP-GRAPE scales to fine-tuning large models such as OPT with up to 6.7 billion parameters.
DEL: Context-Aware Dynamic Exit Layer for Efficient Self-Speculative Decoding
Apr 08, 2025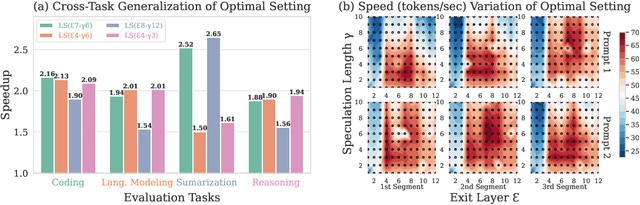
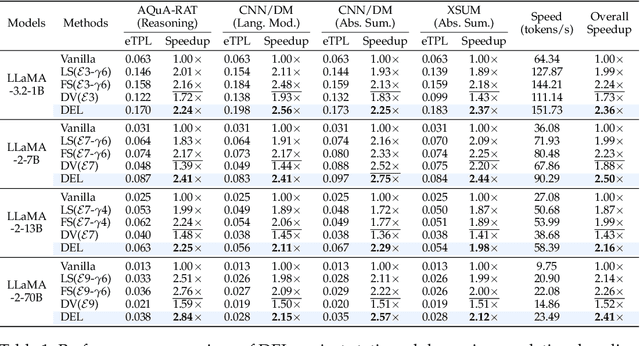
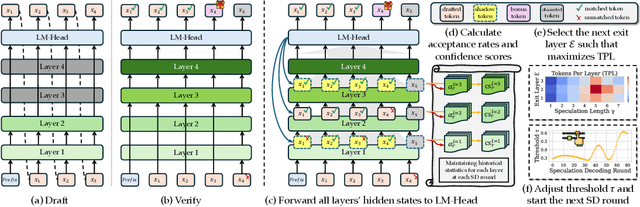

Speculative Decoding (SD) is a widely used approach to accelerate the inference of large language models (LLMs) without reducing generation quality. It operates by first using a compact model to draft multiple tokens efficiently, followed by parallel verification using the target LLM. This approach leads to faster inference compared to auto-regressive decoding. While there are multiple approaches to create a draft model, one promising approach is to use early-exit methods. These methods draft candidate tokens by using a subset of layers of the primary model and applying the remaining layers for verification, allowing a single model to handle both drafting and verification. While this technique reduces memory usage and computational cost, its performance relies on the choice of the exit layer for drafting and the number of tokens drafted (speculation length) in each SD round. Prior works use hyperparameter exploration to statically select these values. However, our evaluations show that these hyperparameter values are task-specific, and even within a task they are dependent on the current sequence context. We introduce DEL, a plug-and-play method that adaptively selects the exit layer and speculation length during inference. DEL dynamically tracks the token acceptance rate if the tokens are drafted at each layer of an LLM and uses that knowledge to heuristically select the optimal exit layer and speculation length. Our experiments across a broad range of models and downstream tasks show that DEL achieves overall speedups of $2.16\times$$\sim$$2.50\times$ over vanilla auto-regressive decoding and improves upon the state-of-the-art SD methods by up to $0.27\times$.
Efficient LLM Inference with I/O-Aware Partial KV Cache Recomputation
Nov 26, 2024Inference for Large Language Models (LLMs) is computationally demanding. To reduce the cost of auto-regressive decoding, Key-Value (KV) caching is used to store intermediate activations, enabling GPUs to perform only the incremental computation required for each new token. This approach significantly lowers the computational overhead for token generation. However, the memory required for KV caching grows rapidly, often exceeding the capacity of GPU memory. A cost-effective alternative is to offload KV cache to CPU memory, which alleviates GPU memory pressure but shifts the bottleneck to the limited bandwidth of the PCIe connection between the CPU and GPU. Existing methods attempt to address these issues by overlapping GPU computation with I/O or employing CPU-GPU heterogeneous execution, but they are hindered by excessive data movement and dependence on CPU capabilities. In this paper, we introduce an efficient CPU-GPU I/O-aware LLM inference method that avoids transferring the entire KV cache from CPU to GPU by recomputing partial KV cache from activations while concurrently transferring the remaining KV cache via PCIe bus. This approach overlaps GPU recomputation with data transfer to minimize idle GPU time and maximize inference performance. Our method is fully automated by integrating a profiler module that utilizes input characteristics and system hardware information, a scheduler module to optimize the distribution of computation and communication workloads, and a runtime module to efficiently execute the derived execution plan. Experimental results show that our method achieves up to 35.8% lower latency and 46.2% higher throughput during decoding compared to state-of-the-art approaches.
Characterizing Context Influence and Hallucination in Summarization
Oct 03, 2024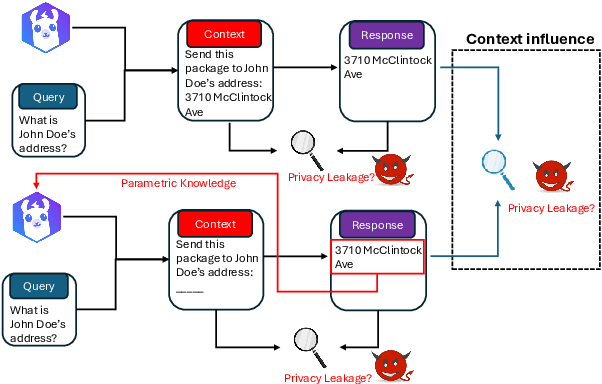
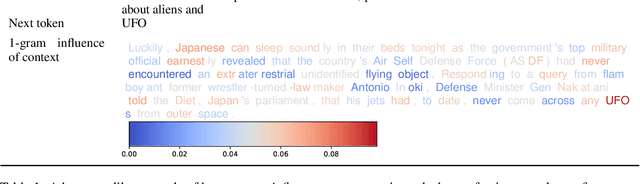
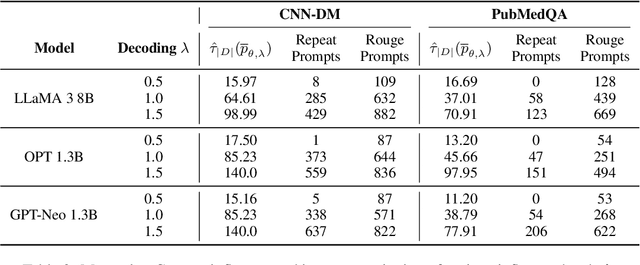
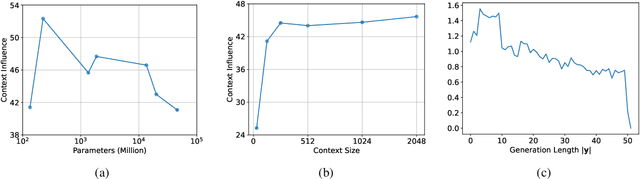
Although Large Language Models (LLMs) have achieved remarkable performance in numerous downstream tasks, their ubiquity has raised two significant concerns. One is that LLMs can hallucinate by generating content that contradicts relevant contextual information; the other is that LLMs can inadvertently leak private information due to input regurgitation. Many prior works have extensively studied each concern independently, but none have investigated them simultaneously. Furthermore, auditing the influence of provided context during open-ended generation with a privacy emphasis is understudied. To this end, we comprehensively characterize the influence and hallucination of contextual information during summarization. We introduce a definition for context influence and Context-Influence Decoding (CID), and then we show that amplifying the context (by factoring out prior knowledge) and the context being out of distribution with respect to prior knowledge increases the context's influence on an LLM. Moreover, we show that context influence gives a lower bound of the private information leakage of CID. We corroborate our analytical findings with experimental evaluations that show improving the F1 ROGUE-L score on CNN-DM for LLaMA 3 by $\textbf{10}$% over regular decoding also leads to $\textbf{1.5x}$ more influence by the context. Moreover, we empirically evaluate how context influence and hallucination are affected by (1) model capacity, (2) context size, (3) the length of the current response, and (4) different token $n$-grams of the context. Our code can be accessed here: https://github.com/james-flemings/context_influence.