 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptively Private Next-Token Prediction of Large Language Models
Paper and Code
Oct 02, 2024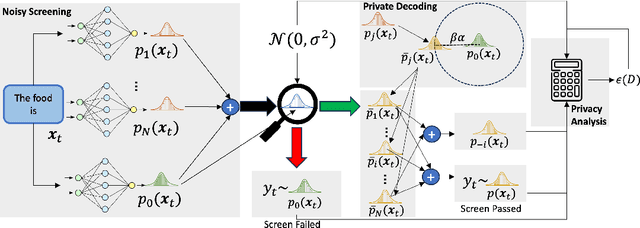
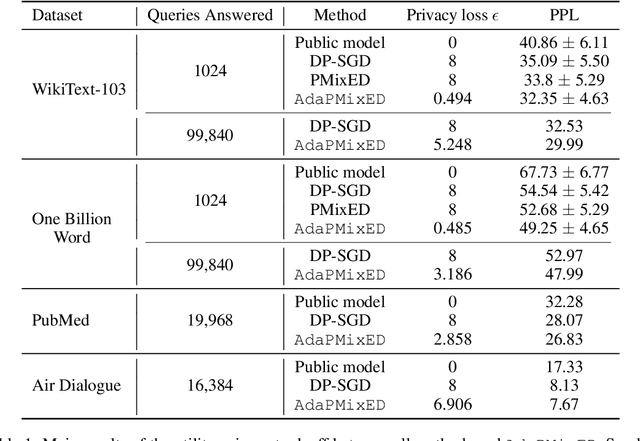
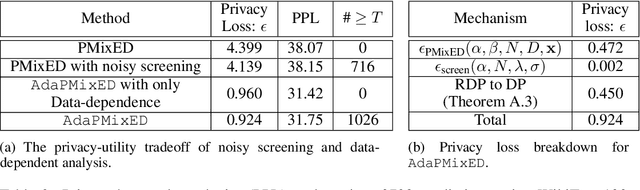
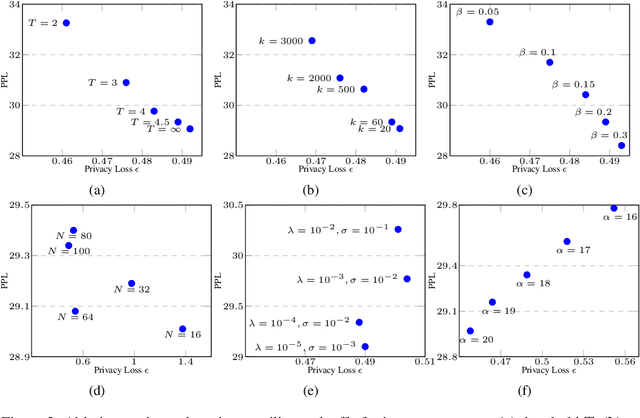
As Large Language Models (LLMs) proliferate, developing privacy safeguards for these models is crucial. One popular safeguard involves training LLMs in a differentially private manner. However, such solutions are shown to be computationally expensive and detrimental to the utility of these models. Since LLMs are deployed on the cloud and thus only accessible via an API, a Machine Learning as a Service (MLaaS) provider can protect its downstream data by privatizing the predictions during the decoding process. However, the practicality of such solutions still largely lags behind DP training methods. One recent promising approach, Private Mixing of Ensemble Distributions (PMixED), avoids additive noise by sampling from the output distributions of private LLMs mixed with the output distribution of a public model. Yet, PMixED must satisfy a fixed privacy level for a given number of queries, which is difficult for an analyst to estimate before inference and, hence, does not scale. To this end, we relax the requirements to a more practical setting by introducing Adaptive PMixED (AdaPMixED), a private decoding framework based on PMixED that is adaptive to the private and public output distributions evaluated on a given input query. In this setting, we introduce a noisy screening mechanism that filters out queries with potentially expensive privacy loss, and a data-dependent analysis that exploits the divergence of the private and public output distributions in its privacy loss calculation. Our experimental evaluations demonstrate that our mechanism and analysis can reduce the privacy loss by 16x while preserving the utility over the original PMixED. Furthermore, performing 100K predictions with AdaPMixED still achieves strong utility and a reasonable data-dependent privacy loss of 5.25.