 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacySIM: Evaluating LLM Simulation of User Privacy Behavior
May 12, 2026Large language models (LLMs) are increasingly used to simulate human behavior, but their ability to simulate $individual$ privacy decisions is not well understood. In this paper, we address the problem of evaluating whether a core set of user persona attributes can drive LLMs to simulate individual-level privacy behavior. We introduce PrivacySIM, an evaluation suite that benchmarks LLM simulation of user privacy behavior against the ground-truth responses of 1,000 users. These users are drawn from five published user studies on privacy spanning LLM healthcare consultations, conversational agents, and chatbots. Drawing on these user studies, we hypothesize three persona facets as plausible predictors of privacy decision-making: demographics, previous experiences, and stated privacy attitudes. We condition nine frontier LLMs on subsets of these three facets and measure how often each model's response to a data-sharing scenario matches the user's actual response. Our findings show that (1) privacy persona conditioning consistently improves simulation quality over no-persona conditioning, but even the strongest model (40.4\% accuracy) remains far from faithfully simulating individual privacy decisions. (2) A user's stated privacy attitudes alone may not be the best predictor because they often diverge from the user's actual privacy behavior. (3) Users with high AI/chatbot experience but low stated privacy attitudes are the most challenging to simulate. PrivacySIM is a first step toward understanding and improving the capabilities of LLMs to simulate user privacy decisions. We release PrivacySIM to enable further evaluation of LLM privacy simulation.
Differentially Private Retrieval-Augmented Generation
Feb 16, 2026Retrieval-augmented generation (RAG) is a widely used framework for reducing hallucinations in large language models (LLMs) on domain-specific tasks by retrieving relevant documents from a database to support accurate responses. However, when the database contains sensitive corpora, such as medical records or legal documents, RAG poses serious privacy risks by potentially exposing private information through its outputs. Prior work has demonstrated that one can practically craft adversarial prompts that force an LLM to regurgitate the augmented contexts. A promising direction is to integrate differential privacy (DP), a privacy notion that offers strong formal guarantees, into RAG systems. However, naively applying DP mechanisms into existing systems often leads to significant utility degradation. Particularly for RAG systems, DP can reduce the usefulness of the augmented contexts leading to increase risk of hallucination from the LLMs. Motivated by these challenges, we present DP-KSA, a novel privacy-preserving RAG algorithm that integrates DP using the propose-test-release paradigm. DP-KSA follows from a key observation that most question-answering (QA) queries can be sufficiently answered with a few keywords. Hence, DP-KSA first obtains an ensemble of relevant contexts, each of which will be used to generate a response from an LLM. We utilize these responses to obtain the most frequent keywords in a differentially private manner. Lastly, the keywords are augmented into the prompt for the final output. This approach effectively compresses the semantic space while preserving both utility and privacy. We formally show that DP-KSA provides formal DP guarantees on the generated output with respect to the RAG database. We evaluate DP-KSA on two QA benchmarks using three instruction-tuned LLMs, and our empirical results demonstrate that DP-KSA achieves a strong privacy-utility tradeoff.
Hubble: a Model Suite to Advance the Study of LLM Memorization
Oct 22, 2025We present Hubble, a suite of fully open-source large language models (LLMs) for the scientific study of LLM memorization. Hubble models come in standard and perturbed variants: standard models are pretrained on a large English corpus, and perturbed models are trained in the same way but with controlled insertion of text (e.g., book passages, biographies, and test sets) designed to emulate key memorization risks. Our core release includes 8 models -- standard and perturbed models with 1B or 8B parameters, pretrained on 100B or 500B tokens -- establishing that memorization risks are determined by the frequency of sensitive data relative to size of the training corpus (i.e., a password appearing once in a smaller corpus is memorized better than the same password in a larger corpus). Our release also includes 6 perturbed models with text inserted at different pretraining phases, showing that sensitive data without continued exposure can be forgotten. These findings suggest two best practices for addressing memorization risks: to dilute sensitive data by increasing the size of the training corpus, and to order sensitive data to appear earlier in training. Beyond these general empirical findings, Hubble enables a broad range of memorization research; for example, analyzing the biographies reveals how readily different types of private information are memorized. We also demonstrate that the randomized insertions in Hubble make it an ideal testbed for membership inference and machine unlearning, and invite the community to further explore, benchmark, and build upon our work.
Memory-Efficient Differentially Private Training with Gradient Random Projection
Jun 18, 2025Differential privacy (DP) protects sensitive data during neural network training, but standard methods like DP-Adam suffer from high memory overhead due to per-sample gradient clipping, limiting scalability. We introduce DP-GRAPE (Gradient RAndom ProjEction), a DP training method that significantly reduces memory usage while maintaining utility on par with first-order DP approaches. Rather than directly applying DP to GaLore, DP-GRAPE introduces three key modifications: (1) gradients are privatized after projection, (2) random Gaussian matrices replace SVD-based subspaces, and (3) projection is applied during backpropagation. These contributions eliminate the need for costly SVD computations, enable substantial memory savings, and lead to improved utility. Despite operating in lower-dimensional subspaces, our theoretical analysis shows that DP-GRAPE achieves a privacy-utility trade-off comparable to DP-SGD. Our extensive empirical experiments show that DP-GRAPE can reduce the memory footprint of DP training without sacrificing accuracy or training time. In particular, DP-GRAPE reduces memory usage by over 63% when pre-training Vision Transformers and over 70% when fine-tuning RoBERTa-Large as compared to DP-Adam, while achieving similar performance. We further demonstrate that DP-GRAPE scales to fine-tuning large models such as OPT with up to 6.7 billion parameters.
Characterizing Context Influence and Hallucination in Summarization
Oct 03, 2024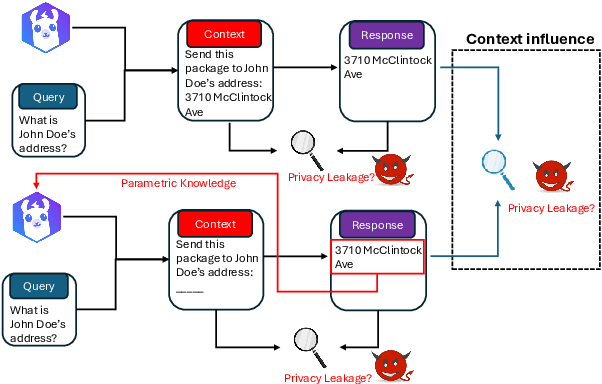
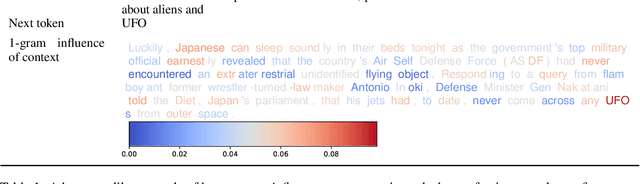
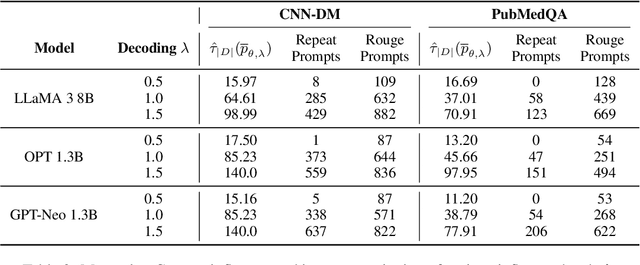
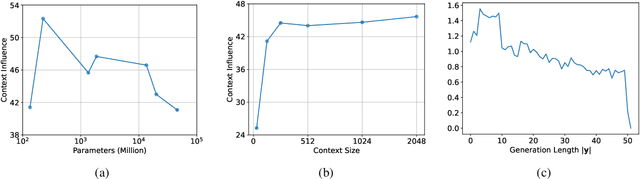
Although Large Language Models (LLMs) have achieved remarkable performance in numerous downstream tasks, their ubiquity has raised two significant concerns. One is that LLMs can hallucinate by generating content that contradicts relevant contextual information; the other is that LLMs can inadvertently leak private information due to input regurgitation. Many prior works have extensively studied each concern independently, but none have investigated them simultaneously. Furthermore, auditing the influence of provided context during open-ended generation with a privacy emphasis is understudied. To this end, we comprehensively characterize the influence and hallucination of contextual information during summarization. We introduce a definition for context influence and Context-Influence Decoding (CID), and then we show that amplifying the context (by factoring out prior knowledge) and the context being out of distribution with respect to prior knowledge increases the context's influence on an LLM. Moreover, we show that context influence gives a lower bound of the private information leakage of CID. We corroborate our analytical findings with experimental evaluations that show improving the F1 ROGUE-L score on CNN-DM for LLaMA 3 by $\textbf{10}$% over regular decoding also leads to $\textbf{1.5x}$ more influence by the context. Moreover, we empirically evaluate how context influence and hallucination are affected by (1) model capacity, (2) context size, (3) the length of the current response, and (4) different token $n$-grams of the context. Our code can be accessed here: https://github.com/james-flemings/context_influence.
Adaptively Private Next-Token Prediction of Large Language Models
Oct 02, 2024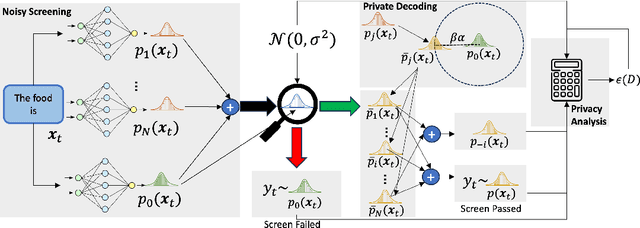
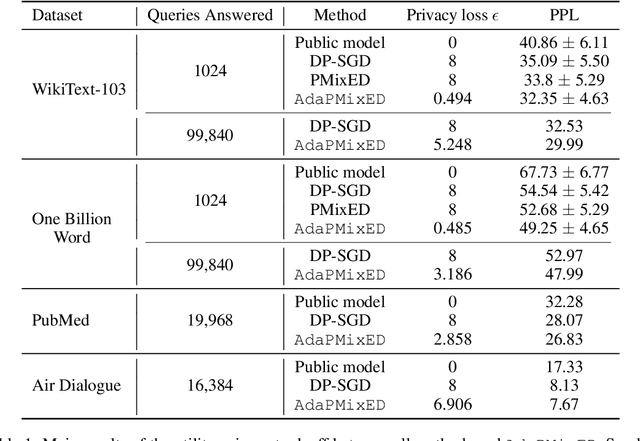
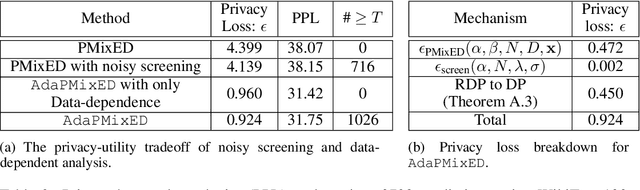
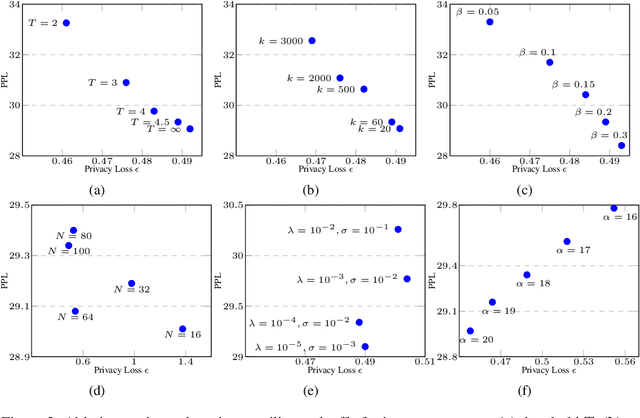
As Large Language Models (LLMs) proliferate, developing privacy safeguards for these models is crucial. One popular safeguard involves training LLMs in a differentially private manner. However, such solutions are shown to be computationally expensive and detrimental to the utility of these models. Since LLMs are deployed on the cloud and thus only accessible via an API, a Machine Learning as a Service (MLaaS) provider can protect its downstream data by privatizing the predictions during the decoding process. However, the practicality of such solutions still largely lags behind DP training methods. One recent promising approach, Private Mixing of Ensemble Distributions (PMixED), avoids additive noise by sampling from the output distributions of private LLMs mixed with the output distribution of a public model. Yet, PMixED must satisfy a fixed privacy level for a given number of queries, which is difficult for an analyst to estimate before inference and, hence, does not scale. To this end, we relax the requirements to a more practical setting by introducing Adaptive PMixED (AdaPMixED), a private decoding framework based on PMixED that is adaptive to the private and public output distributions evaluated on a given input query. In this setting, we introduce a noisy screening mechanism that filters out queries with potentially expensive privacy loss, and a data-dependent analysis that exploits the divergence of the private and public output distributions in its privacy loss calculation. Our experimental evaluations demonstrate that our mechanism and analysis can reduce the privacy loss by 16x while preserving the utility over the original PMixED. Furthermore, performing 100K predictions with AdaPMixED still achieves strong utility and a reasonable data-dependent privacy loss of 5.25.
Differentially Private Next-Token Prediction of Large Language Models
Apr 01, 2024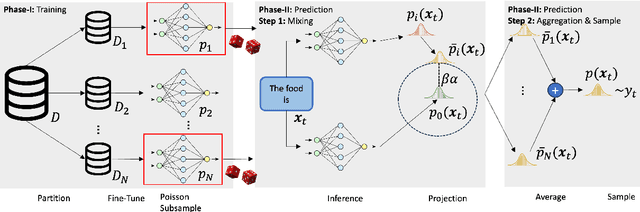
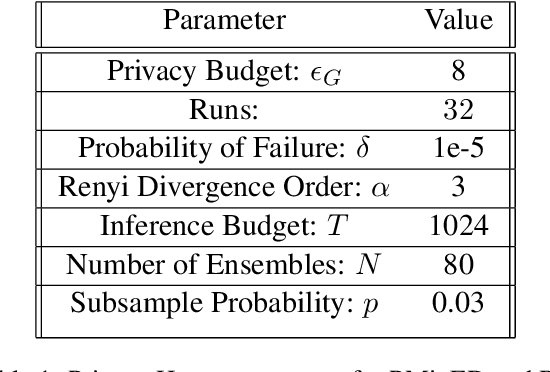
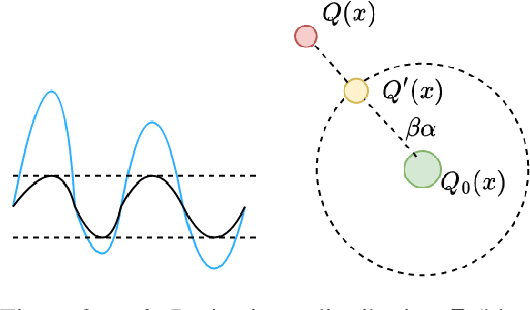
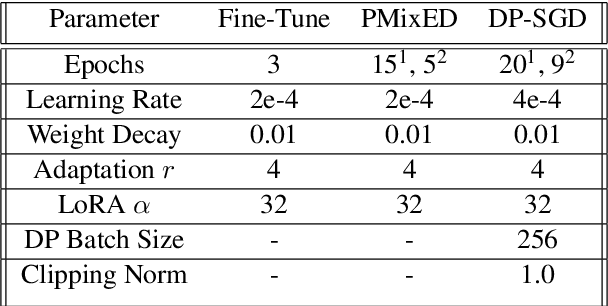
Ensuring the privacy of Large Language Models (LLMs) is becoming increasingly important. The most widely adopted technique to accomplish this is DP-SGD, which trains a model to guarantee Differential Privacy (DP). However, DP-SGD overestimates an adversary's capabilities in having white box access to the model and, as a result, causes longer training times and larger memory usage than SGD. On the other hand, commercial LLM deployments are predominantly cloud-based; hence, adversarial access to LLMs is black-box. Motivated by these observations, we present Private Mixing of Ensemble Distributions (PMixED): a private prediction protocol for next-token prediction that utilizes the inherent stochasticity of next-token sampling and a public model to achieve Differential Privacy. We formalize this by introducing RD-mollifers which project each of the model's output distribution from an ensemble of fine-tuned LLMs onto a set around a public LLM's output distribution, then average the projected distributions and sample from it. Unlike DP-SGD which needs to consider the model architecture during training, PMixED is model agnostic, which makes PMixED a very appealing solution for current deployments. Our results show that PMixED achieves a stronger privacy guarantee than sample-level privacy and outperforms DP-SGD for privacy $\epsilon = 8$ on large-scale datasets. Thus, PMixED offers a practical alternative to DP training methods for achieving strong generative utility without compromising privacy.
Differentially Private Knowledge Distillation via Synthetic Text Generation
Mar 01, 2024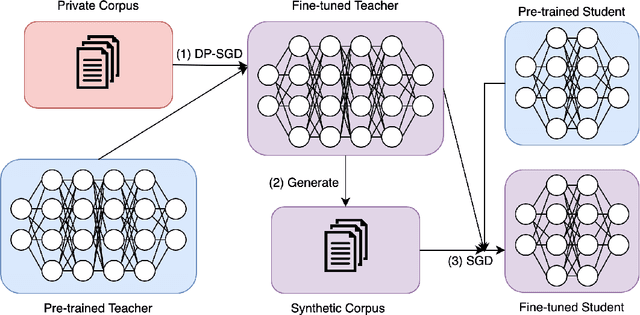
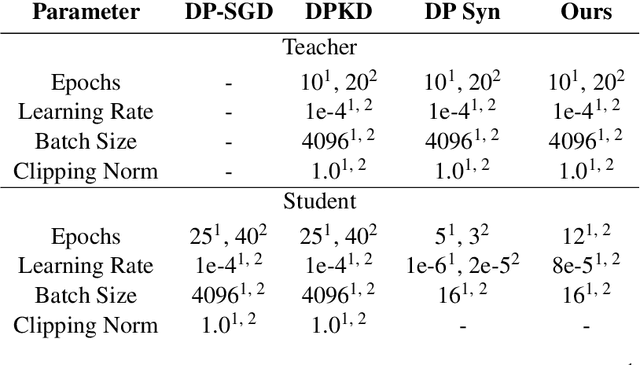
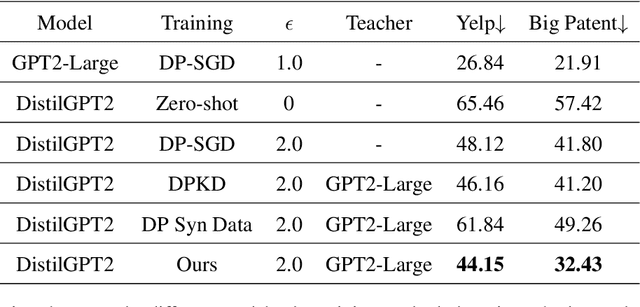
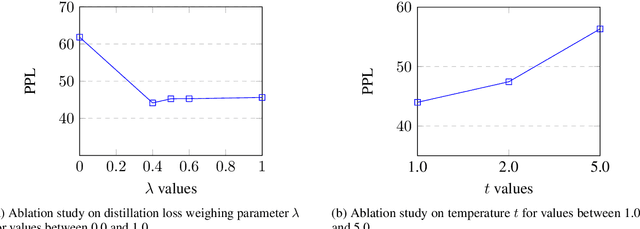
Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy requires LLMs to train with Differential Privacy (DP) on private data. Concurrently it is also necessary to compress LLMs for real-life deployments on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, concurrently achieving both can result in even more utility loss. To this end, we propose a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private LLM. The knowledge of a teacher model is transferred onto the student in two ways: one way from the synthetic data itself, the hard labels, and the other way by the output distribution of the teacher model evaluated on the synthetic data, the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by exploiting hidden representations. Our results show that our framework substantially improves the utility over existing baselines with strong privacy parameters, {\epsilon} = 2, validating that we can successfully compress autoregressive LLMs while preserving the privacy of training data.