 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved Privacy and Utility Analysis of Differentially Private SGD with Bounded Domain and Smooth Losses
Feb 25, 2025Differentially Private Stochastic Gradient Descent (DPSGD) is widely used to protect sensitive data during the training of machine learning models, but its privacy guarantees often come at the cost of model performance, largely due to the inherent challenge of accurately quantifying privacy loss. While recent efforts have strengthened privacy guarantees by focusing solely on the final output and bounded domain cases, they still impose restrictive assumptions, such as convexity and other parameter limitations, and often lack a thorough analysis of utility. In this paper, we provide rigorous privacy and utility characterization for DPSGD for smooth loss functions in both bounded and unbounded domains. We track the privacy loss over multiple iterations by exploiting the noisy smooth-reduction property and establish the utility analysis by leveraging the projection's non-expansiveness and clipped SGD properties. In particular, we show that for DPSGD with a bounded domain, (i) the privacy loss can still converge without the convexity assumption, and (ii) a smaller bounded diameter can improve both privacy and utility simultaneously under certain conditions. Numerical results validate our results.
Characterizing Context Influence and Hallucination in Summarization
Oct 03, 2024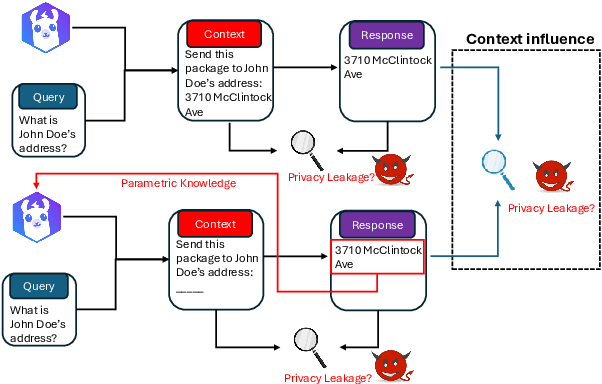
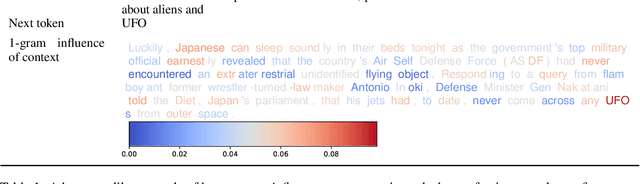
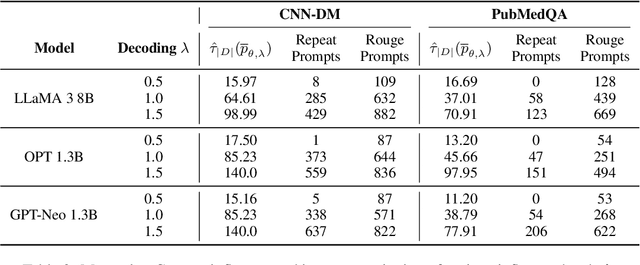
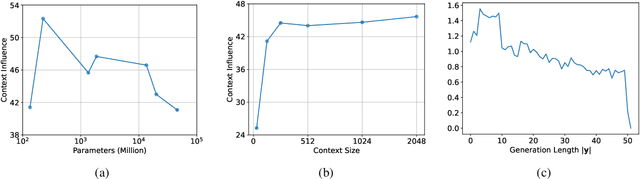
Although Large Language Models (LLMs) have achieved remarkable performance in numerous downstream tasks, their ubiquity has raised two significant concerns. One is that LLMs can hallucinate by generating content that contradicts relevant contextual information; the other is that LLMs can inadvertently leak private information due to input regurgitation. Many prior works have extensively studied each concern independently, but none have investigated them simultaneously. Furthermore, auditing the influence of provided context during open-ended generation with a privacy emphasis is understudied. To this end, we comprehensively characterize the influence and hallucination of contextual information during summarization. We introduce a definition for context influence and Context-Influence Decoding (CID), and then we show that amplifying the context (by factoring out prior knowledge) and the context being out of distribution with respect to prior knowledge increases the context's influence on an LLM. Moreover, we show that context influence gives a lower bound of the private information leakage of CID. We corroborate our analytical findings with experimental evaluations that show improving the F1 ROGUE-L score on CNN-DM for LLaMA 3 by $\textbf{10}$% over regular decoding also leads to $\textbf{1.5x}$ more influence by the context. Moreover, we empirically evaluate how context influence and hallucination are affected by (1) model capacity, (2) context size, (3) the length of the current response, and (4) different token $n$-grams of the context. Our code can be accessed here: https://github.com/james-flemings/context_influence.
Membership Inference Attacks and Privacy in Topic Modeling
Mar 07, 2024Recent research shows that large language models are susceptible to privacy attacks that infer aspects of the training data. However, it is unclear if simpler generative models, like topic models, share similar vulnerabilities. In this work, we propose an attack against topic models that can confidently identify members of the training data in Latent Dirichlet Allocation. Our results suggest that the privacy risks associated with generative modeling are not restricted to large neural models. Additionally, to mitigate these vulnerabilities, we explore differentially private (DP) topic modeling. We propose a framework for private topic modeling that incorporates DP vocabulary selection as a pre-processing step, and show that it improves privacy while having limited effects on practical utility.
Safeguarding Data in Multimodal AI: A Differentially Private Approach to CLIP Training
Jun 13, 2023



The surge in multimodal AI's success has sparked concerns over data privacy in vision-and-language tasks. While CLIP has revolutionized multimodal learning through joint training on images and text, its potential to unintentionally disclose sensitive information necessitates the integration of privacy-preserving mechanisms. We introduce a differentially private adaptation of the Contrastive Language-Image Pretraining (CLIP) model that effectively addresses privacy concerns while retaining accuracy. Our proposed method, Dp-CLIP, is rigorously evaluated on benchmark datasets encompassing diverse vision-and-language tasks such as image classification and visual question answering. We demonstrate that our approach retains performance on par with the standard non-private CLIP model. Furthermore, we analyze our proposed algorithm under linear representation settings. We derive the convergence rate of our algorithm and show a trade-off between utility and privacy when gradients are clipped per-batch and the loss function does not satisfy smoothness conditions assumed in the literature for the analysis of DP-SGD.
DP-Fast MH: Private, Fast, and Accurate Metropolis-Hastings for Large-Scale Bayesian Inference
Mar 10, 2023Bayesian inference provides a principled framework for learning from complex data and reasoning under uncertainty. It has been widely applied in machine learning tasks such as medical diagnosis, drug design, and policymaking. In these common applications, the data can be highly sensitive. Differential privacy (DP) offers data analysis tools with powerful worst-case privacy guarantees and has been developed as the leading approach in privacy-preserving data analysis. In this paper, we study Metropolis-Hastings (MH), one of the most fundamental MCMC methods, for large-scale Bayesian inference under differential privacy. While most existing private MCMC algorithms sacrifice accuracy and efficiency to obtain privacy, we provide the first exact and fast DP MH algorithm, using only a minibatch of data in most iterations. We further reveal, for the first time, a three-way trade-off among privacy, scalability (i.e. the batch size), and efficiency (i.e. the convergence rate), theoretically characterizing how privacy affects the utility and computational cost in Bayesian inference. We empirically demonstrate the effectiveness and efficiency of our algorithm in various experiments.
Private Sequential Hypothesis Testing for Statisticians: Privacy, Error Rates, and Sample Size
Apr 10, 2022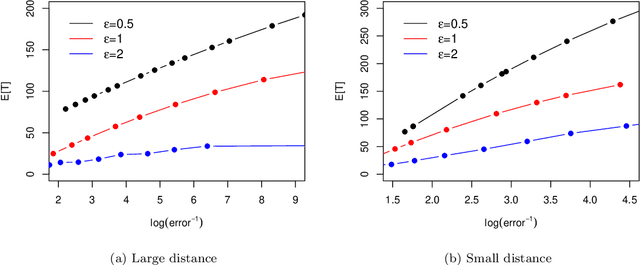
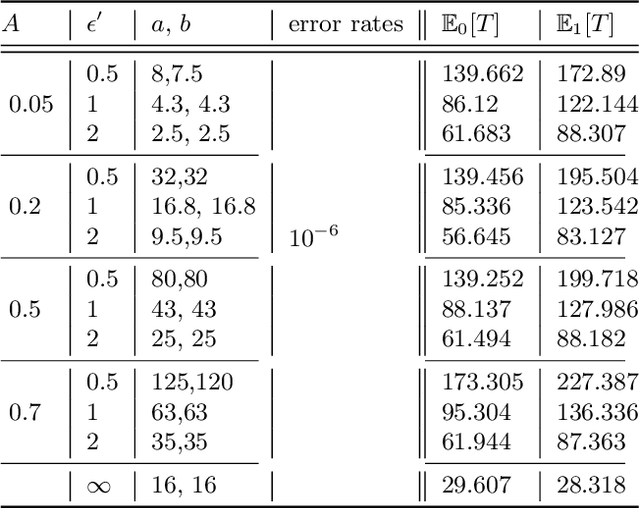
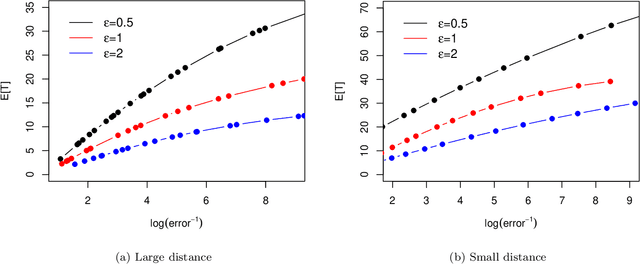
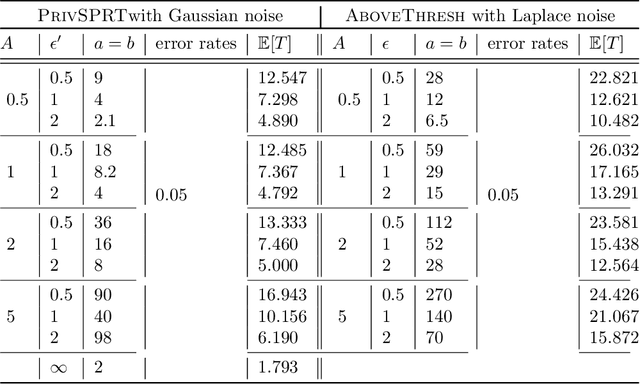
The sequential hypothesis testing problem is a class of statistical analyses where the sample size is not fixed in advance. Instead, the decision-process takes in new observations sequentially to make real-time decisions for testing an alternative hypothesis against a null hypothesis until some stopping criterion is satisfied. In many common applications of sequential hypothesis testing, the data can be highly sensitive and may require privacy protection; for example, sequential hypothesis testing is used in clinical trials, where doctors sequentially collect data from patients and must determine when to stop recruiting patients and whether the treatment is effective. The field of differential privacy has been developed to offer data analysis tools with strong privacy guarantees, and has been commonly applied to machine learning and statistical tasks. In this work, we study the sequential hypothesis testing problem under a slight variant of differential privacy, known as Renyi differential privacy. We present a new private algorithm based on Wald's Sequential Probability Ratio Test (SPRT) that also gives strong theoretical privacy guarantees. We provide theoretical analysis on statistical performance measured by Type I and Type II error as well as the expected sample size. We also empirically validate our theoretical results on several synthetic databases, showing that our algorithms also perform well in practice. Unlike previous work in private hypothesis testing that focused only on the classical fixed sample setting, our results in the sequential setting allow a conclusion to be reached much earlier, and thus saving the cost of collecting additional samples.
Bandit Change-Point Detection for Real-Time Monitoring High-Dimensional Data Under Sampling Control
Sep 24, 2020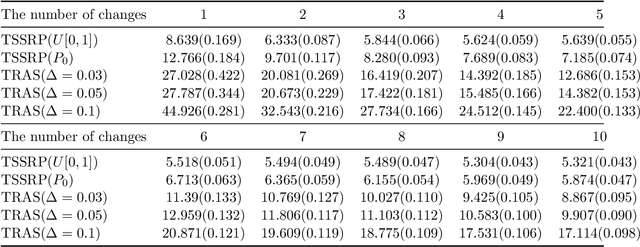


In many real-world problems of real-time monitoring high-dimensional streaming data, one wants to detect an undesired event or change quickly once it occurs, but under the sampling control constraint in the sense that one might be able to only observe or use selected components data for decision-making per time step in the resource-constrained environments. In this paper, we propose to incorporate multi-armed bandit approaches into sequential change-point detection to develop an efficient bandit change-point detection algorithm. Our proposed algorithm, termed Thompson-Sampling-Shiryaev-Roberts-Pollak (TSSRP), consists of two policies per time step: the adaptive sampling policy applies the Thompson Sampling algorithm to balance between exploration for acquiring long-term knowledge and exploitation for immediate reward gain, and the statistical decision policy fuses the local Shiryaev-Roberts-Pollak statistics to determine whether to raise a global alarm by sum shrinkage techniques. Extensive numerical simulations and case studies demonstrate the statistical and computational efficiency of our proposed TSSRP algorithm.
Attribute Privacy: Framework and Mechanisms
Sep 08, 2020


Ensuring the privacy of training data is a growing concern since many machine learning models are trained on confidential and potentially sensitive data. Much attention has been devoted to methods for protecting individual privacy during analyses of large datasets. However in many settings, global properties of the dataset may also be sensitive (e.g., mortality rate in a hospital rather than presence of a particular patient in the dataset). In this work, we depart from individual privacy to initiate the study of attribute privacy, where a data owner is concerned about revealing sensitive properties of a whole dataset during analysis. We propose definitions to capture \emph{attribute privacy} in two relevant cases where global attributes may need to be protected: (1) properties of a specific dataset and (2) parameters of the underlying distribution from which dataset is sampled. We also provide two efficient mechanisms and one inefficient mechanism that satisfy attribute privacy for these settings. We base our results on a novel use of the Pufferfish framework to account for correlations across attributes in the data, thus addressing "the challenging problem of developing Pufferfish instantiations and algorithms for general aggregate secrets" that was left open by \cite{kifer2014pufferfish}.
Dataset-Level Attribute Leakage in Collaborative Learning
Jun 12, 2020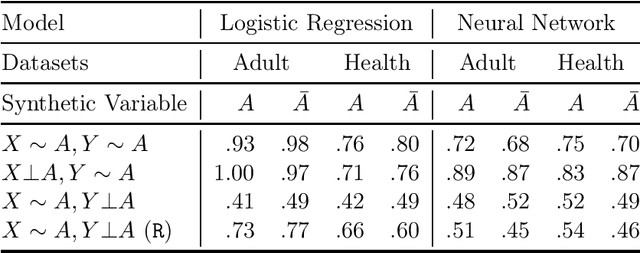
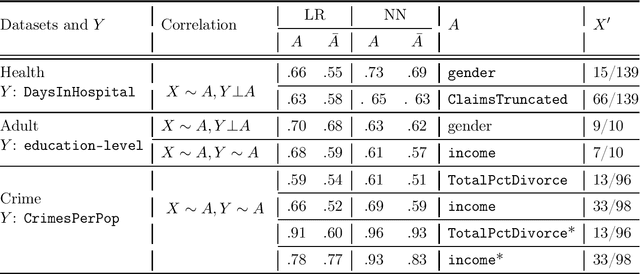
Multi-party machine learning allows several parties to build a joint model to get insights that may not be learnable using only their local data. We consider settings where each party obtains black-box access to the model computed by their mutually agreed-upon algorithm on their joined data. We show that such multi-party computation can cause information leakage between the parties. In particular, a "curious" party can infer the distribution of sensitive attributes in other parties' data with high accuracy. In order to understand and measure the source of leakage, we consider several models of correlation between a sensitive attribute and the rest of the data. Using multiple datasets and machine learning models, we show that leakage occurs even if the sensitive attribute is not included in the training data and has a low correlation with other attributes and the target variable.
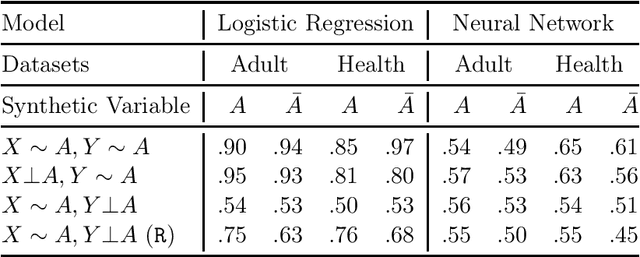
PAPRIKA: Private Online False Discovery Rate Control
Feb 27, 2020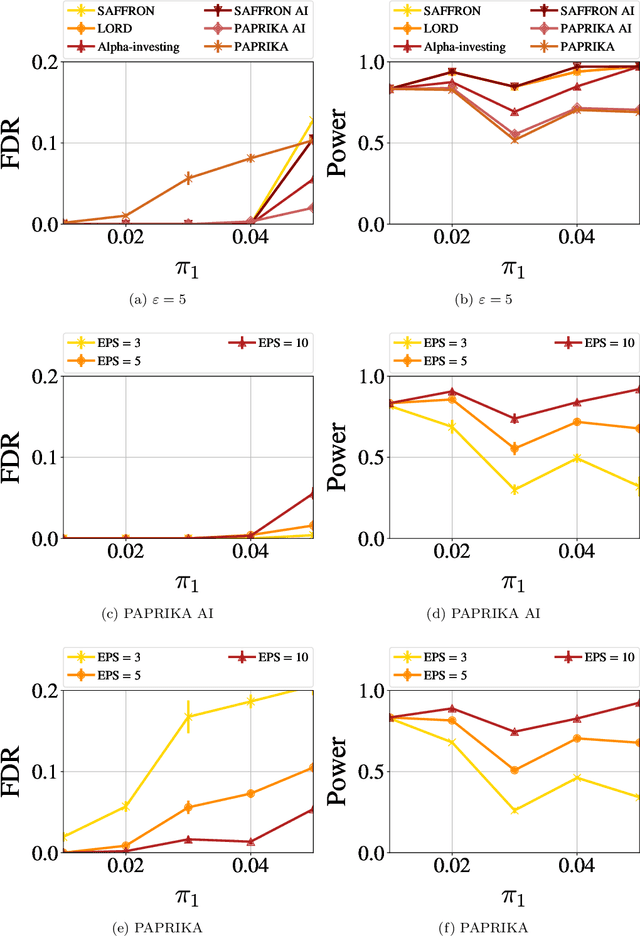

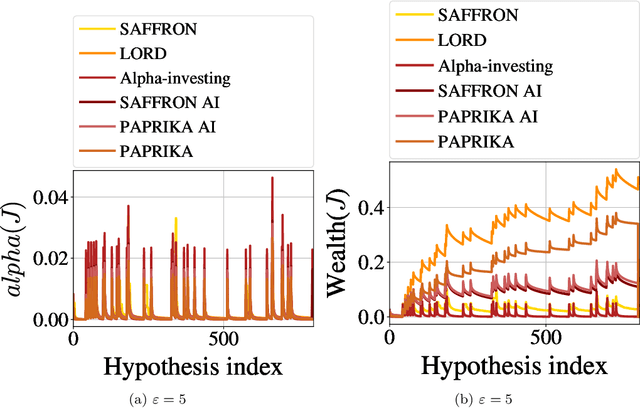

In hypothesis testing, a false discovery occurs when a hypothesis is incorrectly rejected due to noise in the sample. When adaptively testing multiple hypotheses, the probability of a false discovery increases as more tests are performed. Thus the problem of False Discovery Rate (FDR) control is to find a procedure for testing multiple hypotheses that accounts for this effect in determining the set of hypotheses to reject. The goal is to minimize the number (or fraction) of false discoveries, while maintaining a high true positive rate (i.e., correct discoveries). In this work, we study False Discovery Rate (FDR) control in multiple hypothesis testing under the constraint of differential privacy for the sample. Unlike previous work in this direction, we focus on the online setting, meaning that a decision about each hypothesis must be made immediately after the test is performed, rather than waiting for the output of all tests as in the offline setting. We provide new private algorithms based on state-of-the-art results in non-private online FDR control. Our algorithms have strong provable guarantees for privacy and statistical performance as measured by FDR and power. We also provide experimental results to demonstrate the efficacy of our algorithms in a variety of data environments.