 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Federated Conformal Prediction with Group-Conditional Guarantees
Mar 17, 2026Deploying trustworthy AI systems requires principled uncertainty quantification. Conformal prediction (CP) is a widely used framework for constructing prediction sets with distribution-free coverage guarantees. In many practical settings, including healthcare, finance, and mobile sensing, the calibration data required for CP are distributed across multiple clients, each with its own local data distribution. In this federated setting, data can often be partitioned into, potentially overlapping, groups, which may reflect client-specific strata or cross-cutting attributes such as demographic or semantic categories. We propose group-conditional federated conformal prediction (GC-FCP), a novel protocol that provides group-conditional coverage guarantees. GC-FCP constructs mergeable, group-stratified coresets from local calibration scores, enabling clients to communicate compact weighted summaries that support efficient aggregation and calibration at the server. Experiments on synthetic and real-world datasets validate the performance of GC-FCP compared to centralized calibration baselines.
User Localization and Channel Estimation for Pinching-Antenna Systems (PASS)
Dec 16, 2025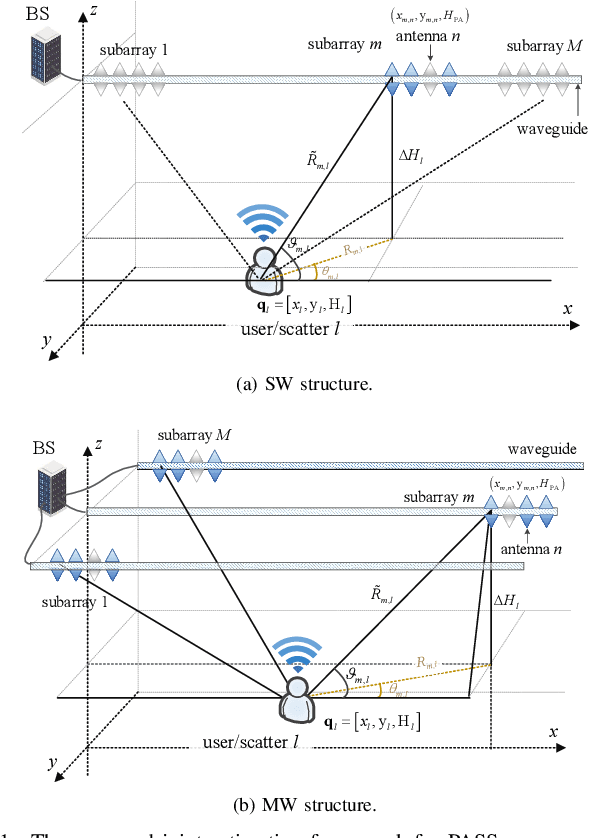
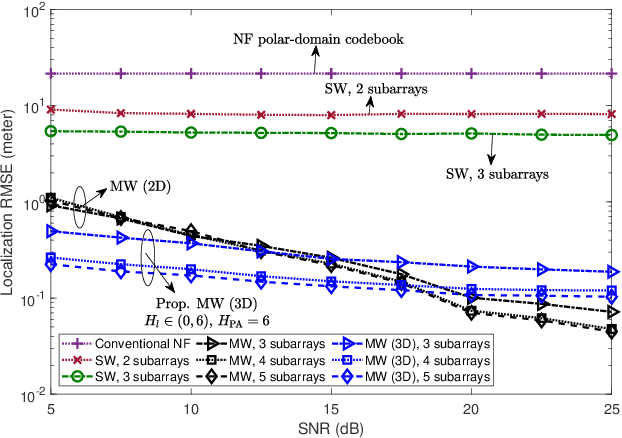
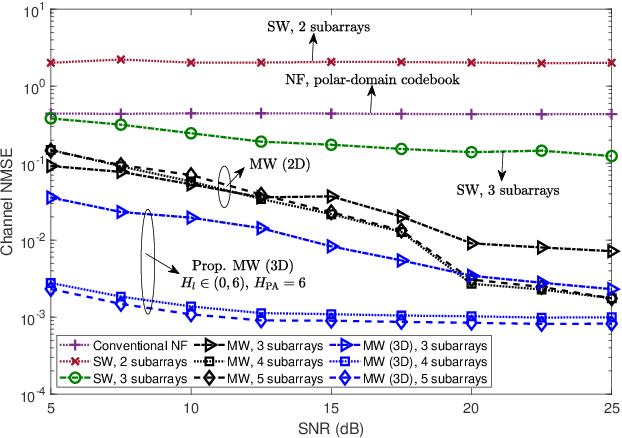
This letter proposes a novel user localization and channel estimation framework for pinching-antenna systems (PASS), where pinching antennas are grouped into subarrays on each waveguide to cooperatively estimate user/scatterer locations, thus reconstructing channels. Both single-waveguide (SW) and multi-waveguide (MW) structures are considered. SW consists of multiple alternatingly activated subarrays, while MW deploys one subarray on each waveguide to enable concurrent subarray measurements. For the 2D scenarios with a fixed user/scatter height, an orthogonal matching pursuit-based geometry-consistent localization (OMP-GCL) algorithm is proposed, which leverages inter-subarray geometric relationships and compressed sensing for precise estimation. Theoretical analysis on Cramér-Rao lower bound (CRLB) demonstrates that: 1) The estimation accuracy can be improved by increasing the geometric diversity through multi-subarray deployment; and 2) SW provides a limited geometric diversity within a $180^\circ$ half space and leads to angle ambiguity, while MW enables full-space observations and reduces overheads. The OMP-GCL algorithm is further extended to 3D scenarios, where user and scatter heights are also estimated. Numerical results validate the theoretical analysis, and verify that MW achieves centimeter- and decimeter-level localization accuracy in 2D and 3D scenarios with only three waveguides.
Unsupervised Learning for AoD Estimation in MISO Downlink LoS Transmissions
Mar 15, 2025



With the emerging of simultaneous localization and communication (SLAC), it becomes more and more attractive to perform angle of departure (AoD) estimation at the receiving Internet of Thing (IoT) user end for improved positioning accuracy, flexibility and enhanced user privacy. To address challenges like large number of real-time measurements required for latency-critical applications and enormous data collection for training deep learning models in conventional AoD estimation methods, we propose in this letter an unsupervised learning framework, which unifies training for both deterministic maximum likelihood (DML) and stochastic maximum likelihood (SML) based AoD estimation in multiple-input single-output (MISO) downlink (DL) wireless transmissions. Specifically, under the line-of-sight (LoS) assumption, we incorporate both the received signals and pilot-sequence information, as per its availability at the DL user, into the input of the deep learning model, and adopt a common neural network architecture compatible with input data in both DML and SML cases. Extensive numerical results validate that the proposed unsupervised learning based AoD estimation not only improves estimation accuracy, but also significantly reduces required number of observations, thereby reducing both estimation overhead and latency compared to various benchmarks.
An Improved Privacy and Utility Analysis of Differentially Private SGD with Bounded Domain and Smooth Losses
Feb 25, 2025Differentially Private Stochastic Gradient Descent (DPSGD) is widely used to protect sensitive data during the training of machine learning models, but its privacy guarantees often come at the cost of model performance, largely due to the inherent challenge of accurately quantifying privacy loss. While recent efforts have strengthened privacy guarantees by focusing solely on the final output and bounded domain cases, they still impose restrictive assumptions, such as convexity and other parameter limitations, and often lack a thorough analysis of utility. In this paper, we provide rigorous privacy and utility characterization for DPSGD for smooth loss functions in both bounded and unbounded domains. We track the privacy loss over multiple iterations by exploiting the noisy smooth-reduction property and establish the utility analysis by leveraging the projection's non-expansiveness and clipped SGD properties. In particular, we show that for DPSGD with a bounded domain, (i) the privacy loss can still converge without the convexity assumption, and (ii) a smaller bounded diameter can improve both privacy and utility simultaneously under certain conditions. Numerical results validate our results.
Distributed Conformal Prediction via Message Passing
Jan 24, 2025



Post-hoc calibration of pre-trained models is critical for ensuring reliable inference, especially in safety-critical domains such as healthcare. Conformal Prediction (CP) offers a robust post-hoc calibration framework, providing distribution-free statistical coverage guarantees for prediction sets by leveraging held-out datasets. In this work, we address a decentralized setting where each device has limited calibration data and can communicate only with its neighbors over an arbitrary graph topology. We propose two message-passing-based approaches for achieving reliable inference via CP: quantile-based distributed conformal prediction (Q-DCP) and histogram-based distributed conformal prediction (H-DCP). Q-DCP employs distributed quantile regression enhanced with tailored smoothing and regularization terms to accelerate convergence, while H-DCP uses a consensus-based histogram estimation approach. Through extensive experiments, we investigate the trade-offs between hyperparameter tuning requirements, communication overhead, coverage guarantees, and prediction set sizes across different network topologies.
NCAirFL: CSI-Free Over-the-Air Federated Learning Based on Non-Coherent Detection
Nov 20, 2024


Over-the-air federated learning (FL), i.e., AirFL, leverages computing primitively over multiple access channels. A long-standing challenge in AirFL is to achieve coherent signal alignment without relying on expensive channel estimation and feedback. This paper proposes NCAirFL, a CSI-free AirFL scheme based on unbiased non-coherent detection at the edge server. By exploiting binary dithering and a long-term memory based error-compensation mechanism, NCAirFL achieves a convergence rate of order $\mathcal{O}(1/\sqrt{T})$ in terms of the average square norm of the gradient for general non-convex and smooth objectives, where $T$ is the number of communication rounds. Experiments demonstrate the competitive performance of NCAirFL compared to vanilla FL with ideal communications and to coherent transmission-based benchmarks.
Generative Artificial Intelligence (GAI) for Mobile Communications: A Diffusion Model Perspective
Oct 08, 2024This article targets at unlocking the potentials of a class of prominent generative artificial intelligence (GAI) method, namely diffusion model (DM), for mobile communications. First, a DM-driven communication architecture is proposed, which introduces two key paradigms, i.e., conditional DM and DMdriven deep reinforcement learning (DRL), for wireless data generation and communication management, respectively. Then, we discuss the key advantages of DM-driven communication paradigms. To elaborate further, we explore DM-driven channel generation mechanisms for channel estimation, extrapolation, and feedback in multiple-input multiple-output (MIMO) systems. We showcase the numerical performance of conditional DM using the accurate DeepMIMO channel datasets, revealing its superiority in generating high-fidelity channels and mitigating unforeseen distribution shifts in sophisticated scenes. Furthermore, several DM-driven communication management designs are conceived, which is promising to deal with imperfect channels and taskoriented communications. To inspire future research developments, we highlight the potential applications and open research challenges of DM-driven communications. Code is available at https://github.com/xiaoxiaxusummer/GAI_COMM/
PRF: Parallel Resonate and Fire Neuron for Long Sequence Learning in Spiking Neural Networks
Oct 04, 2024Recently, there is growing demand for effective and efficient long sequence modeling, with State Space Models (SSMs) proving to be effective for long sequence tasks. To further reduce energy consumption, SSMs can be adapted to Spiking Neural Networks (SNNs) using spiking functions. However, current spiking-formalized SSMs approaches still rely on float-point matrix-vector multiplication during inference, undermining SNNs' energy advantage. In this work, we address the efficiency and performance challenges of long sequence learning in SNNs simultaneously. First, we propose a decoupled reset method for parallel spiking neuron training, reducing the typical Leaky Integrate-and-Fire (LIF) model's training time from $O(L^2)$ to $O(L\log L)$, effectively speeding up the training by $6.57 \times$ to $16.50 \times$ on sequence lengths $1,024$ to $32,768$. To our best knowledge, this is the first time that parallel computation with a reset mechanism is implemented achieving equivalence to its sequential counterpart. Secondly, to capture long-range dependencies, we propose a Parallel Resonate and Fire (PRF) neuron, which leverages an oscillating membrane potential driven by a resonate mechanism from a differentiable reset function in the complex domain. The PRF enables efficient long sequence learning while maintaining parallel training. Finally, we demonstrate that the proposed spike-driven architecture using PRF achieves performance comparable to Structured SSMs (S4), with two orders of magnitude reduction in energy consumption, outperforming Transformer on Long Range Arena tasks.
Accelerating Mobile Edge Generation (MEG) by Constrained Learning
Jul 09, 2024A novel accelerated mobile edge generation (MEG) framework is proposed for generating high-resolution images on mobile devices. Exploiting a large-scale latent diffusion model (LDM) distributed across edge server (ES) and user equipment (UE), cost-efficient artificial intelligence generated content (AIGC) is achieved by transmitting low-dimensional features between ES and UE. To reduce overheads of both distributed computations and transmissions, a dynamic diffusion and feature merging scheme is conceived. By jointly optimizing the denoising steps and feature merging ratio, the image generation quality is maximized subject to latency and energy consumption constraints. To address this problem and tailor LDM sub-models, a low-complexity MEG acceleration protocol is developed. Particularly, a backbone meta-architecture is trained via offline distillation. Then, dynamic diffusion and feature merging are determined in online channel environment, which can be viewed as a constrained Markov Decision Process (MDP). A constrained variational policy optimization (CVPO) based MEG algorithm is further proposed for constraint-guaranteed learning, namely MEG-CVPO. Numerical results verify that: 1) The proposed framework can generate 1024$\times$1024 high-quality images over noisy channels while reducing over $40\%$ latency compared to conventional generation schemes. 2) The developed MEG-CVPO effectively mitigates constraint violations, thus flexibly controlling the trade-off between image distortion and generation costs.
Pre-Training and Personalized Fine-Tuning via Over-the-Air Federated Meta-Learning: Convergence-Generalization Trade-Offs
Jun 17, 2024



For modern artificial intelligence (AI) applications such as large language models (LLMs), the training paradigm has recently shifted to pre-training followed by fine-tuning. Furthermore, owing to dwindling open repositories of data and thanks to efforts to democratize access to AI models, pre-training is expected to increasingly migrate from the current centralized deployments to federated learning (FL) implementations. Meta-learning provides a general framework in which pre-training and fine-tuning can be formalized. Meta-learning-based personalized FL (meta-pFL) moves beyond basic personalization by targeting generalization to new agents and tasks. This paper studies the generalization performance of meta-pFL for a wireless setting in which the agents participating in the pre-training phase, i.e., meta-learning, are connected via a shared wireless channel to the server. Adopting over-the-air computing, we study the trade-off between generalization to new agents and tasks, on the one hand, and convergence, on the other hand. The trade-off arises from the fact that channel impairments may enhance generalization, while degrading convergence. Extensive numerical results validate the theory.