 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Martingale Posterior Samping
May 18, 2026Federated Bayesian neural networks require fixing a prior on the model parameters together with a likelihood. Eliciting meaningful priors on the weight space of modern overparameterized models is notoriously difficult, and misspecification of either component can severely degrade accuracy and calibration. Motivated by the rapid progress of predictive models such as large language models, the martingale posterior, also known as predictive Bayes, replaces the prior--likelihood pair with a predictive distribution and recovers parameter uncertainty by repeatedly drawing predictive samples and refitting the model. A direct federated implementation, however, would require clients to share the local data sets. This letter proposes {federated martingale posterior} (FMP) sampling, a one-shot embarrassingly parallel protocol in which each client uploads a small set of trainable data embeddings and the server runs the predictive sampler centrally. Experiments on MNIST, CIFAR-10, and CIFAR-100 show that FMP closely matches the centralized counterpart and significantly improves calibration over consensus-style baselines.
Semantic-Aware Command and Control Transmission for Multi-UAVs
Jan 29, 2026Uncrewed aerial vehicles (UAVs) have played an important role in the low-altitude economy and have been used in various applications. However, with the increasing number of UAVs and explosive wireless data, the existing bit-oriented communication network has approached the Shannon capacity, which cannot satisfy the quality of service (QoS) with ultra-reliable low-latency communication (URLLC) requirements for command and control (C\&C) transmission in bit-oriented UAV communication networks. To address this issue, we propose a novel semantic-aware C\&C transmission for multi-UAVs under limited wireless resources. Specifically, we leverage semantic similarity to measure the variation in C\&C messages for each UAV over continuous transmission time intervals (TTIs) and capture the correlation of C\&C messages among UAVs, enabling multicast transmission. Based on the semantic similarity and the importance of UAV commands, we design a trigger function to quantify the QoS of UAVs. Then, to maximize the long-term QoS and exploit multicast opportunities of C\&C messages induced by semantic similarity, we develop a proximal policy optimization (PPO) algorithm to jointly determine the transmission mode (unicast/multicast/idle) and the allocation of limited resource blocks (RBs) between a base station (BS) and UAVs. Experimental results show that our proposed semantic-aware framework significantly increases transmission efficiency and improves effectiveness compared with bit-oriented UAV transmission.
Channel Capacity-Aware Distributed Encoding for Multi-View Sensing and Edge Inference
Nov 18, 2024


Integrated sensing and communication (ISAC) unifies wireless communication and sensing by sharing spectrum and hardware, which often incurs trade-offs between two functions due to limited resources. However, this paper shifts focus to exploring the synergy between communication and sensing, using WiFi sensing as an exemplary scenario where communication signals are repurposed to probe the environment without dedicated sensing waveforms, followed by data uploading to the edge server for inference. While increased device participation enhances multi-view sensing data, it also imposes significant communication overhead between devices and the edge server. To address this challenge, we aim to maximize the sensing task performance, measured by mutual information, under the channel capacity constraint. The information-theoretic optimization problem is solved by the proposed ADE-MI, a novel framework that employs a two-stage optimization two-stage optimization approach: (1) adaptive distributed encoding (ADE) at the device, which ensures transmitted bits are most relevant to sensing tasks, and (2) multi-view Inference (MI) at the edge server, which orchestrates multi-view data from distributed devices. Our experimental results highlight the synergy between communication and sensing, showing that more frequent communication from WiFi access points to edge devices improves sensing inference accuracy. The proposed ADE-MI achieves 92\% recognition accuracy with over $10^4$-fold reduction in latency compared to schemes with raw data communication, achieving both high sensing inference accuracy and low communication latency simultaneously.
Personalizing Low-Rank Bayesian Neural Networks Via Federated Learning
Oct 18, 2024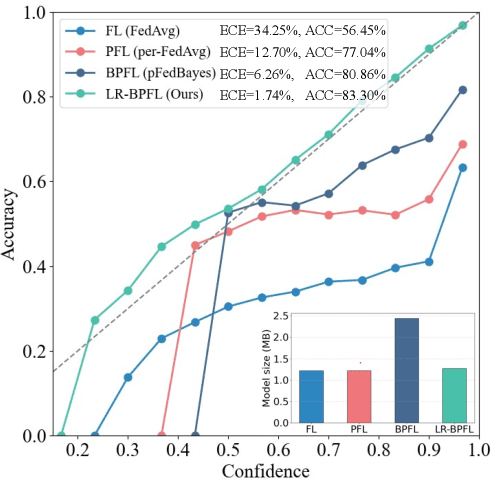
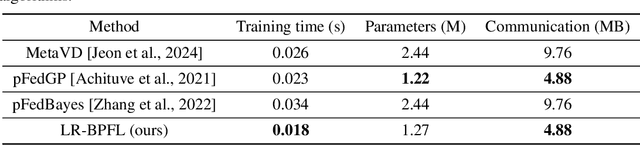
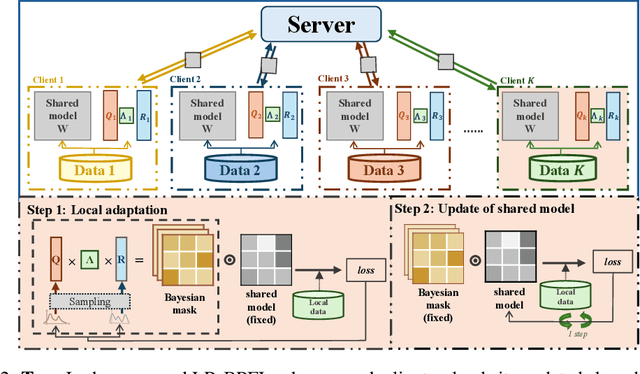

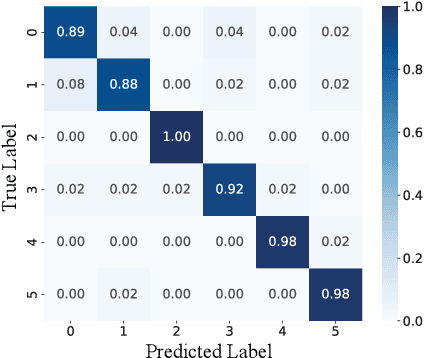
To support real-world decision-making, it is crucial for models to be well-calibrated, i.e., to assign reliable confidence estimates to their predictions. Uncertainty quantification is particularly important in personalized federated learning (PFL), as participating clients typically have small local datasets, making it difficult to unambiguously determine optimal model parameters. Bayesian PFL (BPFL) methods can potentially enhance calibration, but they often come with considerable computational and memory requirements due to the need to track the variances of all the individual model parameters. Furthermore, different clients may exhibit heterogeneous uncertainty levels owing to varying local dataset sizes and distributions. To address these challenges, we propose LR-BPFL, a novel BPFL method that learns a global deterministic model along with personalized low-rank Bayesian corrections. To tailor the local model to each client's inherent uncertainty level, LR-BPFL incorporates an adaptive rank selection mechanism. We evaluate LR-BPFL across a variety of datasets, demonstrating its advantages in terms of calibration, accuracy, as well as computational and memory requirements.
Low-Rank Gradient Compression with Error Feedback for MIMO Wireless Federated Learning
Jan 15, 2024This paper presents a novel approach to enhance the communication efficiency of federated learning (FL) in multiple input and multiple output (MIMO) wireless systems. The proposed method centers on a low-rank matrix factorization strategy for local gradient compression based on alternating least squares, along with over-the-air computation and error feedback. The proposed protocol, termed over-the-air low-rank compression (Ota-LC), is demonstrated to have lower computation cost and lower communication overhead as compared to existing benchmarks while guaranteeing the same inference performance. As an example, when targeting a test accuracy of 80% on the Cifar-10 dataset, Ota-LC achieves a reduction in total communication costs of at least 30% when contrasted with benchmark schemes, while also reducing the computational complexity order by a factor equal to the sum of the dimension of the gradients.
Task-Oriented Integrated Sensing, Computation and Communication for Wireless Edge AI
Jun 11, 2023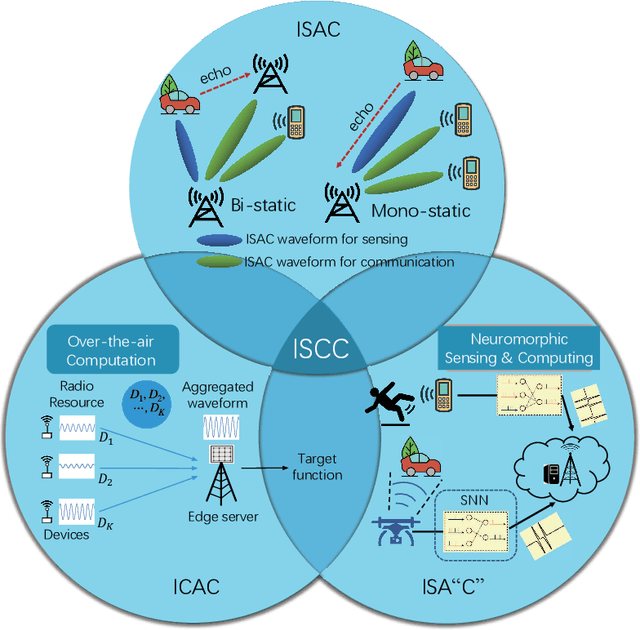
With the advent of emerging IoT applications such as autonomous driving, digital-twin and metaverse etc. featuring massive data sensing, analyzing and inference as well critical latency in beyond 5G (B5G) networks, edge artificial intelligence (AI) has been proposed to provide high-performance computation of a conventional cloud down to the network edge. Recently, convergence of wireless sensing, computation and communication (SC${}^2$) for specific edge AI tasks, has aroused paradigm shift by enabling (partial) sharing of the radio-frequency (RF) transceivers and information processing pipelines among these three fundamental functionalities of IoT. However, most existing design frameworks separate these designs incurring unnecessary signaling overhead and waste of energy, and it is therefore of paramount importance to advance fully integrated sensing, computation and communication (ISCC) to achieve ultra-reliable and low-latency edge intelligence acquisition. In this article, we provide an overview of principles of enabling ISCC technologies followed by two concrete use cases of edge AI tasks demonstrating the advantage of task-oriented ISCC, and pointed out some practical challenges in edge AI design with advanced ISCC solutions.
Bayesian Over-the-Air FedAvg via Channel Driven Stochastic Gradient Langevin Dynamics
May 09, 2023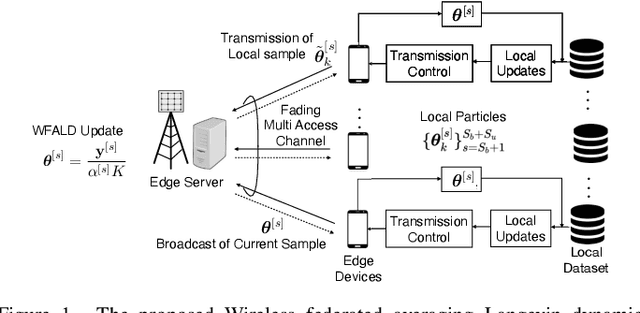



The recent development of scalable Bayesian inference methods has renewed interest in the adoption of Bayesian learning as an alternative to conventional frequentist learning that offers improved model calibration via uncertainty quantification. Recently, federated averaging Langevin dynamics (FALD) was introduced as a variant of federated averaging that can efficiently implement distributed Bayesian learning in the presence of noiseless communications. In this paper, we propose wireless FALD (WFALD), a novel protocol that realizes FALD in wireless systems by integrating over-the-air computation and channel-driven sampling for Monte Carlo updates. Unlike prior work on wireless Bayesian learning, WFALD enables (\emph{i}) multiple local updates between communication rounds; and (\emph{ii}) stochastic gradients computed by mini-batch. A convergence analysis is presented in terms of the 2-Wasserstein distance between the samples produced by WFALD and the targeted global posterior distribution. Analysis and experiments show that, when the signal-to-noise ratio is sufficiently large, channel noise can be fully repurposed for Monte Carlo sampling, thus entailing no loss in performance.
Over-the-Air Federated Edge Learning with Error-Feedback One-Bit Quantization and Power Control
Mar 20, 2023



Over-the-air federated edge learning (Air-FEEL) is a communication-efficient framework for distributed machine learning using training data distributed at edge devices. This framework enables all edge devices to transmit model updates simultaneously over the entire available bandwidth, allowing for over-the-air aggregation. A one-bit digital over-the-air aggregation (OBDA) scheme has been recently proposed, featuring one-bit gradient quantization at edge devices and majority-voting based decoding at the edge server. However, the low-resolution one-bit gradient quantization slows down the model convergence and leads to performance degradation. On the other hand, the aggregation errors caused by fading channels in Air-FEEL is still remained to be solved. To address these issues, we propose the error-feedback one-bit broadband digital aggregation (EFOBDA) and an optimized power control policy. To this end, we first provide a theoretical analysis to evaluate the impact of error feedback on the convergence of FL with EFOBDA. The analytical results show that, by setting an appropriate feedback strength, EFOBDA is comparable to the Air-FEEL without quantization, thus enhancing the performance of OBDA. Then, we further introduce a power control policy by maximizing the convergence rate under instantaneous power constraints. The convergence analysis and optimized power control policy are verified by the experiments, which show that the proposed scheme achieves significantly faster convergence and higher test accuracy in image classification tasks compared with the one-bit quantization scheme without error feedback or optimized power control policy.
Leveraging Channel Noise for Sampling and Privacy via Quantized Federated Langevin Monte Carlo
Feb 28, 2022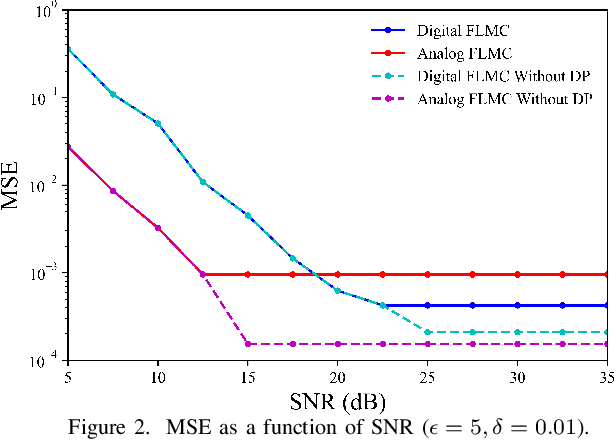
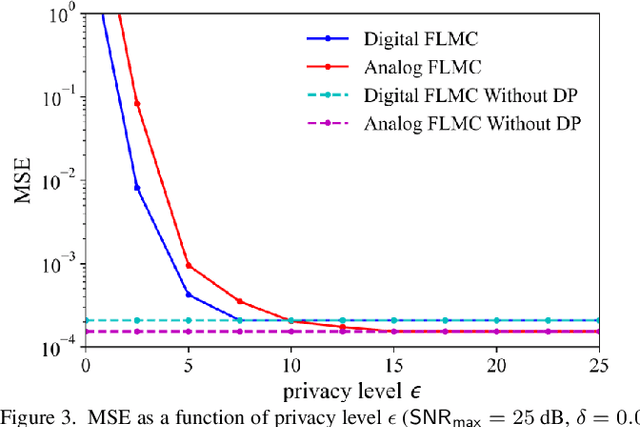
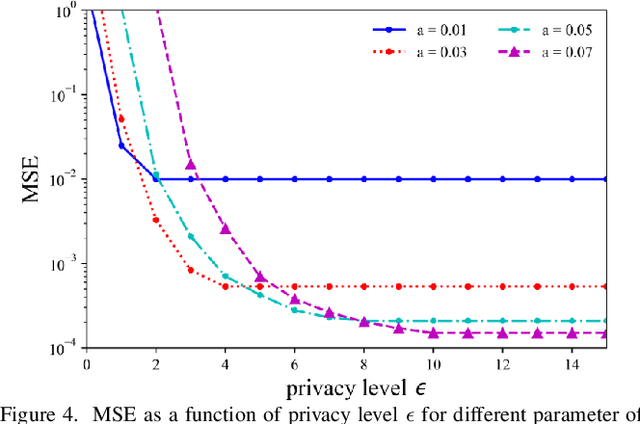
For engineering applications of artificial intelligence, Bayesian learning holds significant advantages over standard frequentist learning, including the capacity to quantify uncertainty. Langevin Monte Carlo (LMC) is an efficient gradient-based approximate Bayesian learning strategy that aims at producing samples drawn from the posterior distribution of the model parameters. Prior work focused on a distributed implementation of LMC over a multi-access wireless channel via analog modulation. In contrast, this paper proposes quantized federated LMC (FLMC), which integrates one-bit stochastic quantization of the local gradients with channel-driven sampling. Channel-driven sampling leverages channel noise for the purpose of contributing to Monte Carlo sampling, while also serving the role of privacy mechanism. Analog and digital implementations of wireless LMC are compared as a function of differential privacy (DP) requirements, revealing the advantages of the latter at sufficiently high signal-to-noise ratio.
Wireless Federated Langevin Monte Carlo: Repurposing Channel Noise for Bayesian Sampling and Privacy
Aug 17, 2021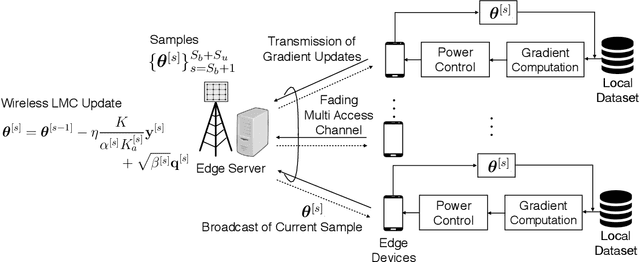
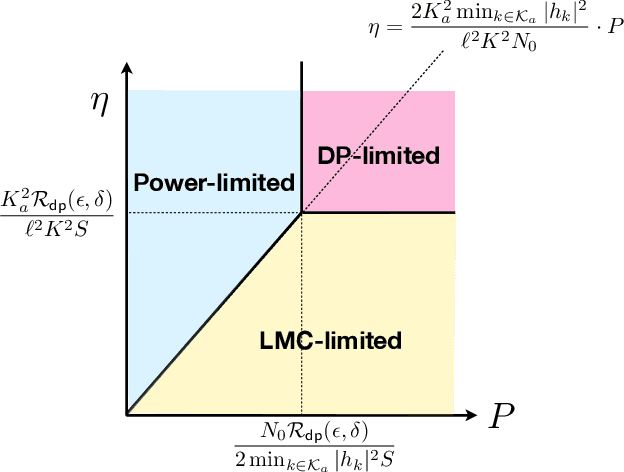

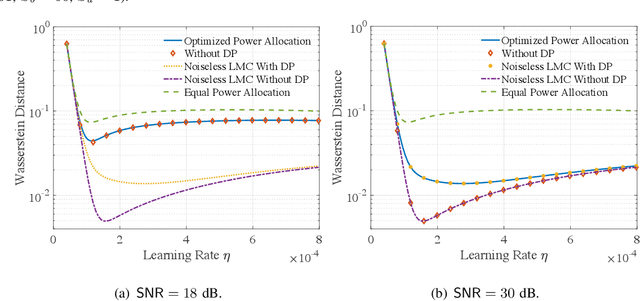
Most works on federated learning (FL) focus on the most common frequentist formulation of learning whereby the goal is minimizing the global empirical loss. Frequentist learning, however, is known to be problematic in the regime of limited data as it fails to quantify epistemic uncertainty in prediction. Bayesian learning provides a principled solution to this problem by shifting the optimization domain to the space of distribution in the model parameters. This paper studies for the first time Bayesian FL in wireless systems by proposing and analyzing a gradient-based Markov Chain Monte Carlo (MCMC) method -- Wireless Federated Langevin Monte Carlo (WFLMC). The key idea of this work is to repurpose channel noise for the double role of seed randomness for MCMC sampling and of privacy-preserving mechanism. To this end, based on the analysis of the Wasserstein distance between sample distribution and global posterior distribution under privacy and power constraints, we introduce a power allocation strategy as the solution of a convex program. The analysis identifies distinct operating regimes in which the performance of the system is power-limited, privacy-limited, or limited by the requirement of MCMC sampling. Both analytical and simulation results demonstrate that, if the channel noise is properly accounted for under suitable conditions, it can be fully repurposed for both MCMC sampling and privacy preservation, obtaining the same performance as in an ideal communication setting that is not subject to privacy constraints.