 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalizing Low-Rank Bayesian Neural Networks Via Federated Learning
Oct 18, 2024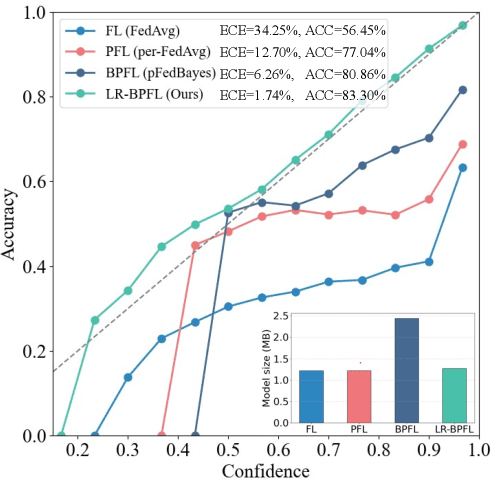
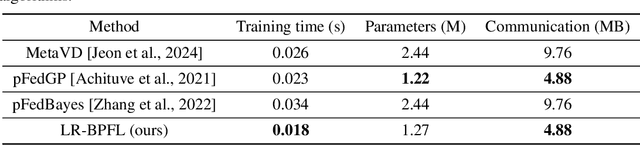
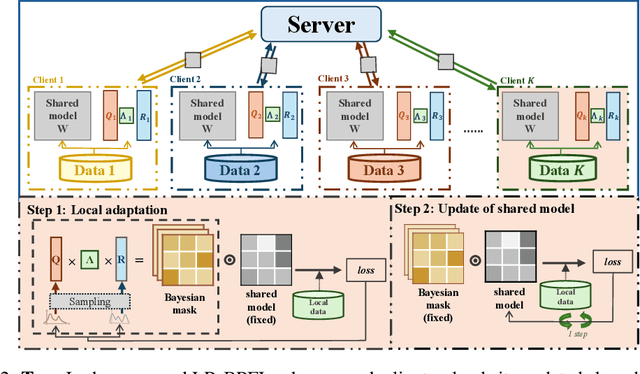

To support real-world decision-making, it is crucial for models to be well-calibrated, i.e., to assign reliable confidence estimates to their predictions. Uncertainty quantification is particularly important in personalized federated learning (PFL), as participating clients typically have small local datasets, making it difficult to unambiguously determine optimal model parameters. Bayesian PFL (BPFL) methods can potentially enhance calibration, but they often come with considerable computational and memory requirements due to the need to track the variances of all the individual model parameters. Furthermore, different clients may exhibit heterogeneous uncertainty levels owing to varying local dataset sizes and distributions. To address these challenges, we propose LR-BPFL, a novel BPFL method that learns a global deterministic model along with personalized low-rank Bayesian corrections. To tailor the local model to each client's inherent uncertainty level, LR-BPFL incorporates an adaptive rank selection mechanism. We evaluate LR-BPFL across a variety of datasets, demonstrating its advantages in terms of calibration, accuracy, as well as computational and memory requirements.
MARIO Eval: Evaluate Your Math LLM with your Math LLM--A mathematical dataset evaluation toolkit
Apr 22, 2024Large language models (LLMs) have been explored in a variety of reasoning tasks including solving of mathematical problems. Each math dataset typically includes its own specially designed evaluation script, which, while suitable for its intended use, lacks generalizability across different datasets. Consequently, updates and adaptations to these evaluation tools tend to occur without being systematically reported, leading to inconsistencies and obstacles to fair comparison across studies. To bridge this gap, we introduce a comprehensive mathematical evaluation toolkit that not only utilizes a python computer algebra system (CAS) for its numerical accuracy, but also integrates an optional LLM, known for its considerable natural language processing capabilities. To validate the effectiveness of our toolkit, we manually annotated two distinct datasets. Our experiments demonstrate that the toolkit yields more robust evaluation results compared to prior works, even without an LLM. Furthermore, when an LLM is incorporated, there is a notable enhancement. The code for our method will be made available at \url{https://github.com/MARIO-Math-Reasoning/math_evaluation}.
How to Generate Popular Post Headlines on Social Media?
Sep 18, 2023Posts, as important containers of user-generated-content pieces on social media, are of tremendous social influence and commercial value. As an integral components of a post, the headline has a decisive contribution to the post's popularity. However, current mainstream method for headline generation is still manually writing, which is unstable and requires extensive human effort. This drives us to explore a novel research question: Can we automate the generation of popular headlines on social media? We collect more than 1 million posts of 42,447 celebrities from public data of Xiaohongshu, which is a well-known social media platform in China. We then conduct careful observations on the headlines of these posts. Observation results demonstrate that trends and personal styles are widespread in headlines on social medias and have significant contribution to posts's popularity. Motivated by these insights, we present MEBART, which combines Multiple preference-Extractors with Bidirectional and Auto-Regressive Transformers (BART), capturing trends and personal styles to generate popular headlines on social medias. We perform extensive experiments on real-world datasets and achieve state-of-the-art performance compared with several advanced baselines. In addition, ablation and case studies demonstrate that MEBART advances in capturing trends and personal styles.
Bayesian Over-the-Air FedAvg via Channel Driven Stochastic Gradient Langevin Dynamics
May 09, 2023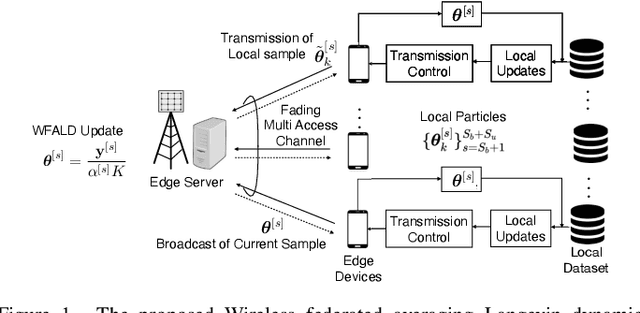



The recent development of scalable Bayesian inference methods has renewed interest in the adoption of Bayesian learning as an alternative to conventional frequentist learning that offers improved model calibration via uncertainty quantification. Recently, federated averaging Langevin dynamics (FALD) was introduced as a variant of federated averaging that can efficiently implement distributed Bayesian learning in the presence of noiseless communications. In this paper, we propose wireless FALD (WFALD), a novel protocol that realizes FALD in wireless systems by integrating over-the-air computation and channel-driven sampling for Monte Carlo updates. Unlike prior work on wireless Bayesian learning, WFALD enables (\emph{i}) multiple local updates between communication rounds; and (\emph{ii}) stochastic gradients computed by mini-batch. A convergence analysis is presented in terms of the 2-Wasserstein distance between the samples produced by WFALD and the targeted global posterior distribution. Analysis and experiments show that, when the signal-to-noise ratio is sufficiently large, channel noise can be fully repurposed for Monte Carlo sampling, thus entailing no loss in performance.
I4U System Description for NIST SRE'20 CTS Challenge
Nov 02, 2022



This manuscript describes the I4U submission to the 2020 NIST Speaker Recognition Evaluation (SRE'20) Conversational Telephone Speech (CTS) Challenge. The I4U's submission was resulted from active collaboration among researchers across eight research teams - I$^2$R (Singapore), UEF (Finland), VALPT (Italy, Spain), NEC (Japan), THUEE (China), LIA (France), NUS (Singapore), INRIA (France) and TJU (China). The submission was based on the fusion of top performing sub-systems and sub-fusion systems contributed by individual teams. Efforts have been spent on the use of common development and validation sets, submission schedule and milestone, minimizing inconsistency in trial list and score file format across sites.