 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePD$^3$: A Project Duplication Detection Framework via Adapted Multi-Agent Debate
May 23, 2025Project duplication detection is critical for project quality assessment, as it improves resource utilization efficiency by preventing investing in newly proposed project that have already been studied. It requires the ability to understand high-level semantics and generate constructive and valuable feedback. Existing detection methods rely on basic word- or sentence-level comparison or solely apply large language models, lacking valuable insights for experts and in-depth comprehension of project content and review criteria. To tackle this issue, we propose PD$^3$, a Project Duplication Detection framework via adapted multi-agent Debate. Inspired by real-world expert debates, it employs a fair competition format to guide multi-agent debate to retrieve relevant projects. For feedback, it incorporates both qualitative and quantitative analysis to improve its practicality. Over 800 real-world power project data spanning more than 20 specialized fields are used to evaluate the framework, demonstrating that our method outperforms existing approaches by 7.43% and 8.00% in two downstream tasks. Furthermore, we establish an online platform, Review Dingdang, to assist power experts, saving 5.73 million USD in initial detection on more than 100 newly proposed projects.
An Expert is Worth One Token: Synergizing Multiple Expert LLMs as Generalist via Expert Token Routing
Mar 25, 2024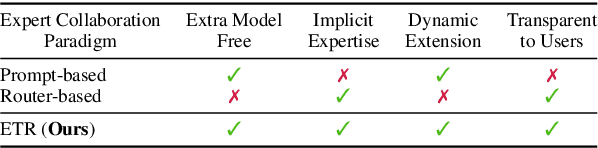
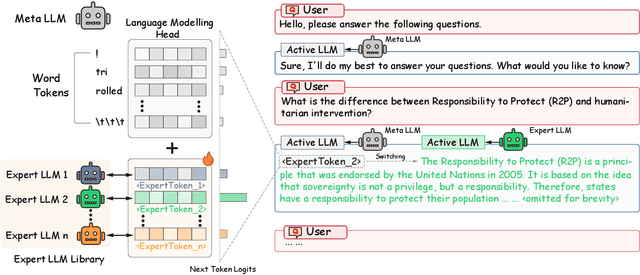
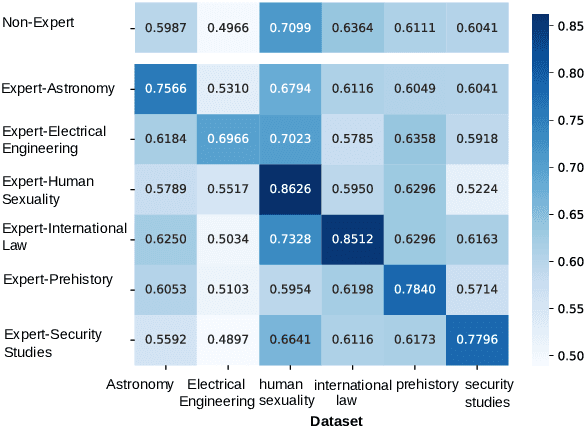
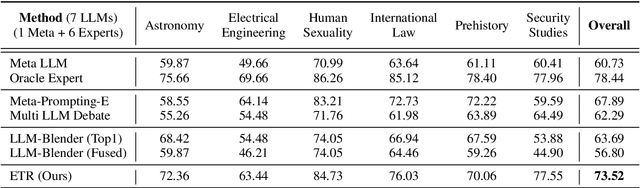
We present Expert-Token-Routing, a unified generalist framework that facilitates seamless integration of multiple expert LLMs. Our framework represents expert LLMs as special expert tokens within the vocabulary of a meta LLM. The meta LLM can route to an expert LLM like generating new tokens. Expert-Token-Routing not only supports learning the implicit expertise of expert LLMs from existing instruction dataset but also allows for dynamic extension of new expert LLMs in a plug-and-play manner. It also conceals the detailed collaboration process from the user's perspective, facilitating interaction as though it were a singular LLM. Our framework outperforms various existing multi-LLM collaboration paradigms across benchmarks that incorporate six diverse expert domains, demonstrating effectiveness and robustness in building generalist LLM system via synergizing multiple expert LLMs.
Can GNN be Good Adapter for LLMs?
Feb 20, 2024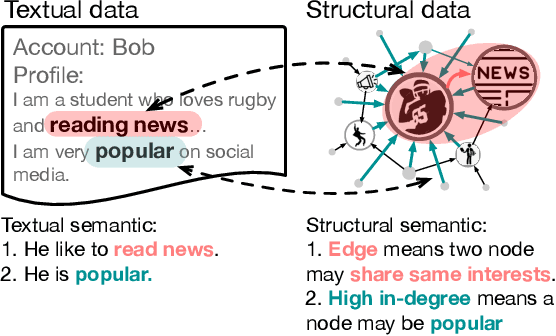
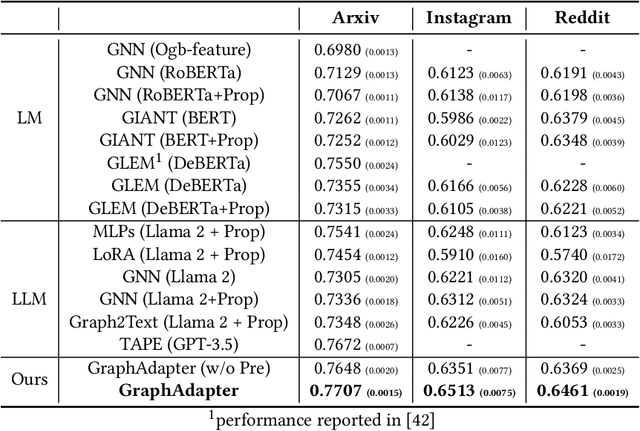
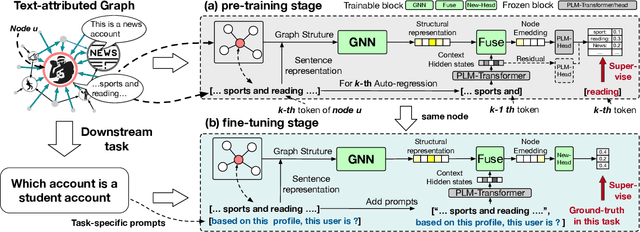

Recently, large language models (LLMs) have demonstrated superior capabilities in understanding and zero-shot learning on textual data, promising significant advances for many text-related domains. In the graph domain, various real-world scenarios also involve textual data, where tasks and node features can be described by text. These text-attributed graphs (TAGs) have broad applications in social media, recommendation systems, etc. Thus, this paper explores how to utilize LLMs to model TAGs. Previous methods for TAG modeling are based on million-scale LMs. When scaled up to billion-scale LLMs, they face huge challenges in computational costs. Additionally, they also ignore the zero-shot inference capabilities of LLMs. Therefore, we propose GraphAdapter, which uses a graph neural network (GNN) as an efficient adapter in collaboration with LLMs to tackle TAGs. In terms of efficiency, the GNN adapter introduces only a few trainable parameters and can be trained with low computation costs. The entire framework is trained using auto-regression on node text (next token prediction). Once trained, GraphAdapter can be seamlessly fine-tuned with task-specific prompts for various downstream tasks. Through extensive experiments across multiple real-world TAGs, GraphAdapter based on Llama 2 gains an average improvement of approximately 5\% in terms of node classification. Furthermore, GraphAdapter can also adapt to other language models, including RoBERTa, GPT-2. The promising results demonstrate that GNNs can serve as effective adapters for LLMs in TAG modeling.
One Graph Model for Cross-domain Dynamic Link Prediction
Feb 03, 2024



This work proposes DyExpert, a dynamic graph model for cross-domain link prediction. It can explicitly model historical evolving processes to learn the evolution pattern of a specific downstream graph and subsequently make pattern-specific link predictions. DyExpert adopts a decode-only transformer and is capable of efficiently parallel training and inference by \textit{conditioned link generation} that integrates both evolution modeling and link prediction. DyExpert is trained by extensive dynamic graphs across diverse domains, comprising 6M dynamic edges. Extensive experiments on eight untrained graphs demonstrate that DyExpert achieves state-of-the-art performance in cross-domain link prediction. Compared to the advanced baseline under the same setting, DyExpert achieves an average of 11.40% improvement Average Precision across eight graphs. More impressive, it surpasses the fully supervised performance of 8 advanced baselines on 6 untrained graphs.
GraphLLM: Boosting Graph Reasoning Ability of Large Language Model
Oct 09, 2023



The advancement of Large Language Models (LLMs) has remarkably pushed the boundaries towards artificial general intelligence (AGI), with their exceptional ability on understanding diverse types of information, including but not limited to images and audio. Despite this progress, a critical gap remains in empowering LLMs to proficiently understand and reason on graph data. Recent studies underscore LLMs' underwhelming performance on fundamental graph reasoning tasks. In this paper, we endeavor to unearth the obstacles that impede LLMs in graph reasoning, pinpointing the common practice of converting graphs into natural language descriptions (Graph2Text) as a fundamental bottleneck. To overcome this impediment, we introduce GraphLLM, a pioneering end-to-end approach that synergistically integrates graph learning models with LLMs. This synergy equips LLMs with the ability to proficiently interpret and reason on graph data, harnessing the superior expressive power of graph learning models. Our empirical evaluations across four fundamental graph reasoning tasks validate the effectiveness of GraphLLM. The results exhibit a substantial average accuracy enhancement of 54.44%, alongside a noteworthy context reduction of 96.45% across various graph reasoning tasks.
How to Generate Popular Post Headlines on Social Media?
Sep 18, 2023Posts, as important containers of user-generated-content pieces on social media, are of tremendous social influence and commercial value. As an integral components of a post, the headline has a decisive contribution to the post's popularity. However, current mainstream method for headline generation is still manually writing, which is unstable and requires extensive human effort. This drives us to explore a novel research question: Can we automate the generation of popular headlines on social media? We collect more than 1 million posts of 42,447 celebrities from public data of Xiaohongshu, which is a well-known social media platform in China. We then conduct careful observations on the headlines of these posts. Observation results demonstrate that trends and personal styles are widespread in headlines on social medias and have significant contribution to posts's popularity. Motivated by these insights, we present MEBART, which combines Multiple preference-Extractors with Bidirectional and Auto-Regressive Transformers (BART), capturing trends and personal styles to generate popular headlines on social medias. We perform extensive experiments on real-world datasets and achieve state-of-the-art performance compared with several advanced baselines. In addition, ablation and case studies demonstrate that MEBART advances in capturing trends and personal styles.
DGraph: A Large-Scale Financial Dataset for Graph Anomaly Detection
Jul 12, 2022


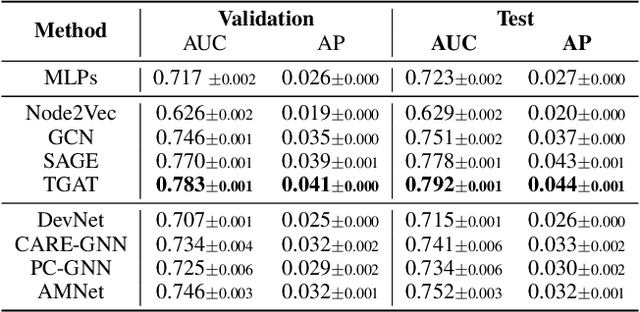
Graph Anomaly Detection (GAD) has recently become a hot research spot due to its practicability and theoretical value. Since GAD emphasizes the application and the rarity of anomalous samples, enriching the varieties of its datasets is a fundamental work. Thus, this paper present DGraph, a real-world dynamic graph in the finance domain. DGraph overcomes many limitations of current GAD datasets. It contains about 3M nodes, 4M dynamic edges, and 1M ground-truth nodes. We provide a comprehensive observation of DGraph, revealing that anomalous nodes and normal nodes generally have different structures, neighbor distribution, and temporal dynamics. Moreover, it suggests that those unlabeled nodes are also essential for detecting fraudsters. Furthermore, we conduct extensive experiments on DGraph. Observation and experiments demonstrate that DGraph is propulsive to advance GAD research and enable in-depth exploration of anomalous nodes.
Adaptive Hierarchical Graph Reasoning with Semantic Coherence for Video-and-Language Inference
Aug 09, 2021
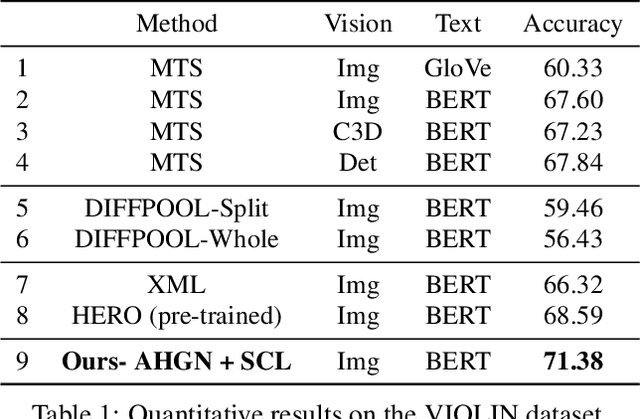
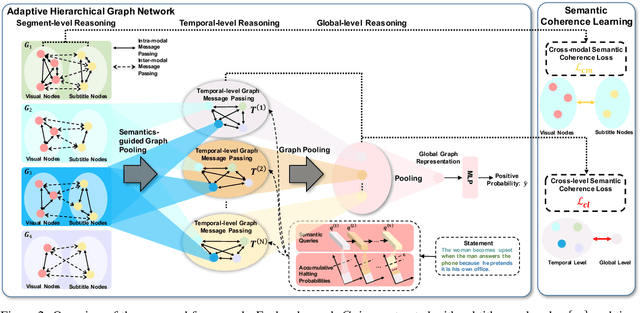

Video-and-Language Inference is a recently proposed task for joint video-and-language understanding. This new task requires a model to draw inference on whether a natural language statement entails or contradicts a given video clip. In this paper, we study how to address three critical challenges for this task: judging the global correctness of the statement involved multiple semantic meanings, joint reasoning over video and subtitles, and modeling long-range relationships and complex social interactions. First, we propose an adaptive hierarchical graph network that achieves in-depth understanding of the video over complex interactions. Specifically, it performs joint reasoning over video and subtitles in three hierarchies, where the graph structure is adaptively adjusted according to the semantic structures of the statement. Secondly, we introduce semantic coherence learning to explicitly encourage the semantic coherence of the adaptive hierarchical graph network from three hierarchies. The semantic coherence learning can further improve the alignment between vision and linguistics, and the coherence across a sequence of video segments. Experimental results show that our method significantly outperforms the baseline by a large margin.