 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssembling the Mind's Mosaic: Towards EEG Semantic Intent Decoding
Jan 28, 2026Enabling natural communication through brain-computer interfaces (BCIs) remains one of the most profound challenges in neuroscience and neurotechnology. While existing frameworks offer partial solutions, they are constrained by oversimplified semantic representations and a lack of interpretability. To overcome these limitations, we introduce Semantic Intent Decoding (SID), a novel framework that translates neural activity into natural language by modeling meaning as a flexible set of compositional semantic units. SID is built on three core principles: semantic compositionality, continuity and expandability of semantic space, and fidelity in reconstruction. We present BrainMosaic, a deep learning architecture implementing SID. BrainMosaic decodes multiple semantic units from EEG/SEEG signals using set matching and then reconstructs coherent sentences through semantic-guided reconstruction. This approach moves beyond traditional pipelines that rely on fixed-class classification or unconstrained generation, enabling a more interpretable and expressive communication paradigm. Extensive experiments on multilingual EEG and clinical SEEG datasets demonstrate that SID and BrainMosaic offer substantial advantages over existing frameworks, paving the way for natural and effective BCI-mediated communication.
NeuroSketch: An Effective Framework for Neural Decoding via Systematic Architectural Optimization
Dec 10, 2025Neural decoding, a critical component of Brain-Computer Interface (BCI), has recently attracted increasing research interest. Previous research has focused on leveraging signal processing and deep learning methods to enhance neural decoding performance. However, the in-depth exploration of model architectures remains underexplored, despite its proven effectiveness in other tasks such as energy forecasting and image classification. In this study, we propose NeuroSketch, an effective framework for neural decoding via systematic architecture optimization. Starting with the basic architecture study, we find that CNN-2D outperforms other architectures in neural decoding tasks and explore its effectiveness from temporal and spatial perspectives. Building on this, we optimize the architecture from macro- to micro-level, achieving improvements in performance at each step. The exploration process and model validations take over 5,000 experiments spanning three distinct modalities (visual, auditory, and speech), three types of brain signals (EEG, SEEG, and ECoG), and eight diverse decoding tasks. Experimental results indicate that NeuroSketch achieves state-of-the-art (SOTA) performance across all evaluated datasets, positioning it as a powerful tool for neural decoding. Our code and scripts are available at https://github.com/Galaxy-Dawn/NeuroSketch.
PD$^3$: A Project Duplication Detection Framework via Adapted Multi-Agent Debate
May 23, 2025Project duplication detection is critical for project quality assessment, as it improves resource utilization efficiency by preventing investing in newly proposed project that have already been studied. It requires the ability to understand high-level semantics and generate constructive and valuable feedback. Existing detection methods rely on basic word- or sentence-level comparison or solely apply large language models, lacking valuable insights for experts and in-depth comprehension of project content and review criteria. To tackle this issue, we propose PD$^3$, a Project Duplication Detection framework via adapted multi-agent Debate. Inspired by real-world expert debates, it employs a fair competition format to guide multi-agent debate to retrieve relevant projects. For feedback, it incorporates both qualitative and quantitative analysis to improve its practicality. Over 800 real-world power project data spanning more than 20 specialized fields are used to evaluate the framework, demonstrating that our method outperforms existing approaches by 7.43% and 8.00% in two downstream tasks. Furthermore, we establish an online platform, Review Dingdang, to assist power experts, saving 5.73 million USD in initial detection on more than 100 newly proposed projects.
Deep Learning-Powered Electrical Brain Signals Analysis: Advancing Neurological Diagnostics
Feb 24, 2025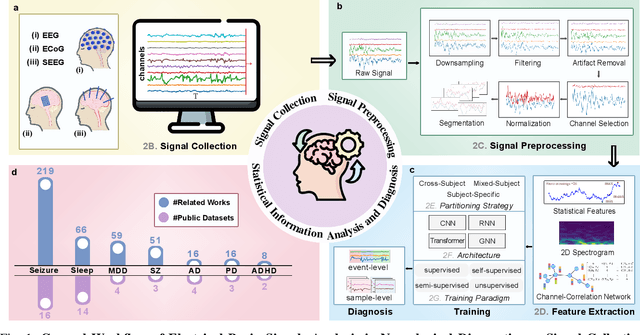
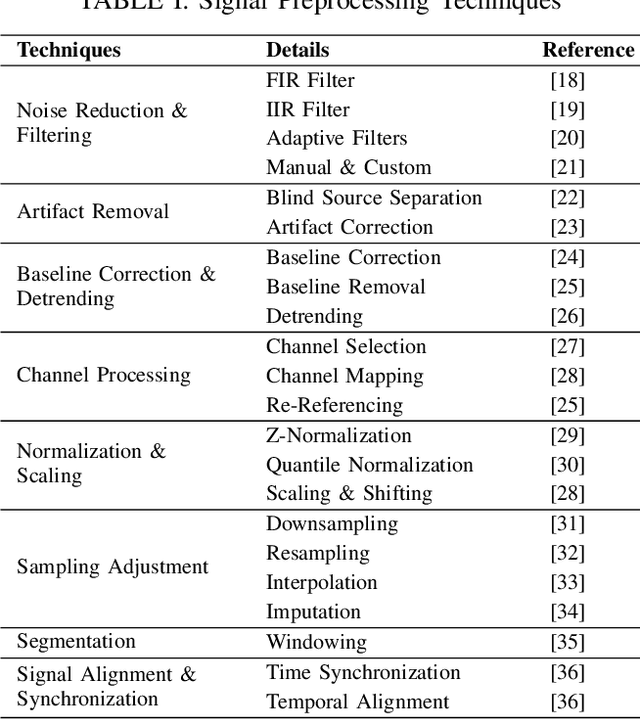
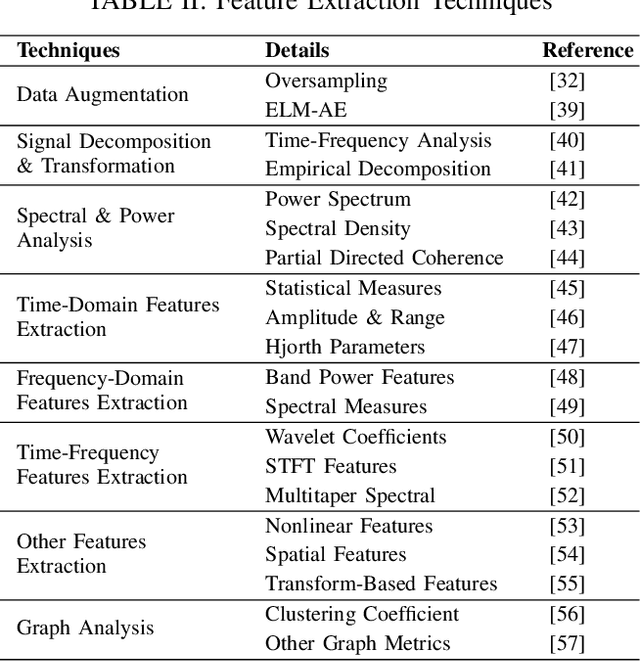
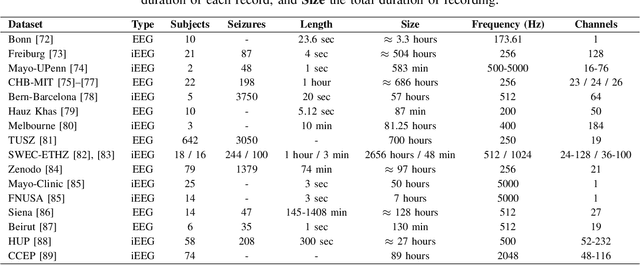
Neurological disorders represent significant global health challenges, driving the advancement of brain signal analysis methods. Scalp electroencephalography (EEG) and intracranial electroencephalography (iEEG) are widely used to diagnose and monitor neurological conditions. However, dataset heterogeneity and task variations pose challenges in developing robust deep learning solutions. This review systematically examines recent advances in deep learning approaches for EEG/iEEG-based neurological diagnostics, focusing on applications across 7 neurological conditions using 46 datasets. We explore trends in data utilization, model design, and task-specific adaptations, highlighting the importance of pre-trained multi-task models for scalable, generalizable solutions. To advance research, we propose a standardized benchmark for evaluating models across diverse datasets to enhance reproducibility. This survey emphasizes how recent innovations can transform neurological diagnostics and enable the development of intelligent, adaptable healthcare solutions.
Brant-X: A Unified Physiological Signal Alignment Framework
Aug 28, 2024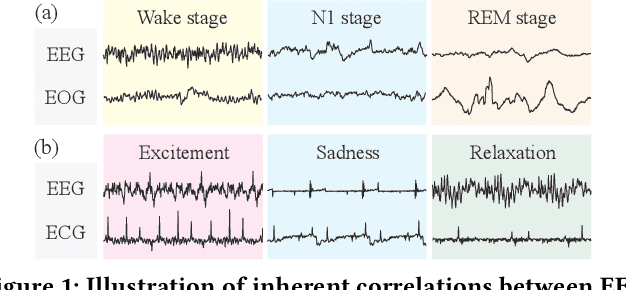
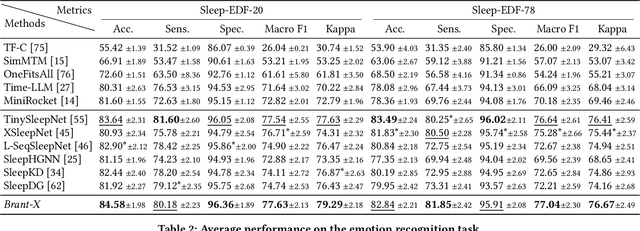

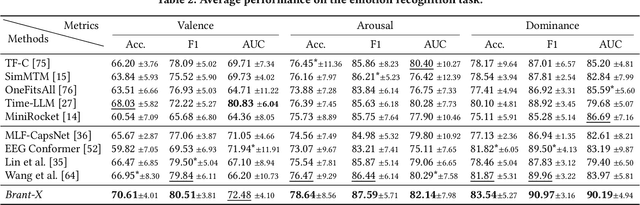
Physiological signals serve as indispensable clues for understanding various physiological states of human bodies. Most existing works have focused on a single type of physiological signals for a range of application scenarios. However, as the body is a holistic biological system, the inherent interconnection among various physiological data should not be neglected. In particular, given the brain's role as the control center for vital activities, electroencephalogram (EEG) exhibits significant correlations with other physiological signals. Therefore, the correlation between EEG and other physiological signals holds potential to improve performance in various scenarios. Nevertheless, achieving this goal is still constrained by several challenges: the scarcity of simultaneously collected physiological data, the differences in correlations between various signals, and the correlation differences between various tasks. To address these issues, we propose a unified physiological signal alignment framework, Brant-X, to model the correlation between EEG and other signals. Our approach (1) employs the EEG foundation model to data-efficiently transfer the rich knowledge in EEG to other physiological signals, and (2) introduces the two-level alignment to fully align the semantics of EEG and other signals from different semantic scales. In the experiments, Brant-X achieves state-of-the-art performance compared with task-agnostic and task-specific baselines on various downstream tasks in diverse scenarios, including sleep stage classification, emotion recognition, freezing of gaits detection, and eye movement communication. Moreover, the analysis on the arrhythmia detection task and the visualization in case study further illustrate the effectiveness of Brant-X in the knowledge transfer from EEG to other physiological signals. The model's homepage is at https://github.com/zjunet/Brant-X/.
* Accepted by SIGKDD 2024
Con4m: Context-aware Consistency Learning Framework for Segmented Time Series Classification
Jul 31, 2024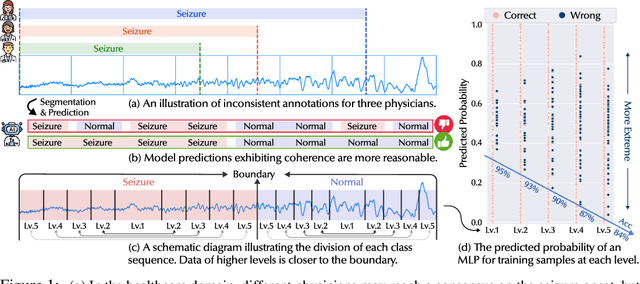

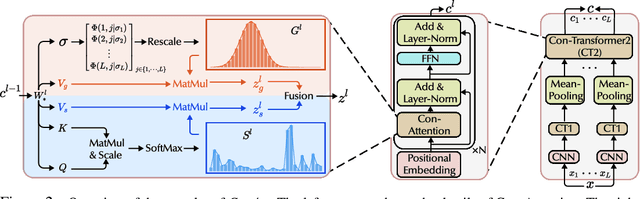
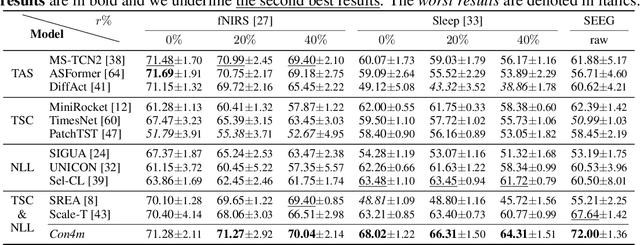
Time Series Classification (TSC) encompasses two settings: classifying entire sequences or classifying segmented subsequences. The raw time series for segmented TSC usually contain Multiple classes with Varying Duration of each class (MVD). Therefore, the characteristics of MVD pose unique challenges for segmented TSC, yet have been largely overlooked by existing works. Specifically, there exists a natural temporal dependency between consecutive instances (segments) to be classified within MVD. However, mainstream TSC models rely on the assumption of independent and identically distributed (i.i.d.), focusing on independently modeling each segment. Additionally, annotators with varying expertise may provide inconsistent boundary labels, leading to unstable performance of noise-free TSC models. To address these challenges, we first formally demonstrate that valuable contextual information enhances the discriminative power of classification instances. Leveraging the contextual priors of MVD at both the data and label levels, we propose a novel consistency learning framework Con4m, which effectively utilizes contextual information more conducive to discriminating consecutive segments in segmented TSC tasks, while harmonizing inconsistent boundary labels for training. Extensive experiments across multiple datasets validate the effectiveness of Con4m in handling segmented TSC tasks on MVD.
Brant-2: Foundation Model for Brain Signals
Feb 22, 2024Foundational models benefit from pre-training on large amounts of unlabeled data and enable strong performance in a wide variety of applications with a small amount of labeled data. Such models can be particularly effective in analyzing brain signals, as this field encompasses numerous application scenarios, and it is costly to perform large-scale annotation. In this work, we present the largest foundation model in brain signals, Brant-2. Compared to Brant, a foundation model designed for intracranial neural signals, Brant-2 not only exhibits robustness towards data variations and modeling scales but also can be applied to a broader range of brain neural data. By experimenting on an extensive range of tasks, we demonstrate that Brant-2 is adaptive to various application scenarios in brain signals. Further analyses reveal the scalability of the Brant-2, validate each component's effectiveness, and showcase our model's ability to maintain performance in scenarios with scarce labels. The source code and pre-trained weights are available at: https://github.com/yzz673/Brant-2.
Are Synthetic Time-series Data Really not as Good as Real Data?
Feb 01, 2024Time-series data presents limitations stemming from data quality issues, bias and vulnerabilities, and generalization problem. Integrating universal data synthesis methods holds promise in improving generalization. However, current methods cannot guarantee that the generator's output covers all unseen real data. In this paper, we introduce InfoBoost -- a highly versatile cross-domain data synthesizing framework with time series representation learning capability. We have developed a method based on synthetic data that enables model training without the need for real data, surpassing the performance of models trained with real data. Additionally, we have trained a universal feature extractor based on our synthetic data that is applicable to all time-series data. Our approach overcomes interference from multiple sources rhythmic signal, noise interference, and long-period features that exceed sampling window capabilities. Through experiments, our non-deep-learning synthetic data enables models to achieve superior reconstruction performance and universal explicit representation extraction without the need for real data.
BrainNet: Epileptic Wave Detection from SEEG with Hierarchical Graph Diffusion Learning
Jun 15, 2023



Epilepsy is one of the most serious neurological diseases, affecting 1-2% of the world's population. The diagnosis of epilepsy depends heavily on the recognition of epileptic waves, i.e., disordered electrical brainwave activity in the patient's brain. Existing works have begun to employ machine learning models to detect epileptic waves via cortical electroencephalogram (EEG). However, the recently developed stereoelectrocorticography (SEEG) method provides information in stereo that is more precise than conventional EEG, and has been broadly applied in clinical practice. Therefore, we propose the first data-driven study to detect epileptic waves in a real-world SEEG dataset. While offering new opportunities, SEEG also poses several challenges. In clinical practice, epileptic wave activities are considered to propagate between different regions in the brain. These propagation paths, also known as the epileptogenic network, are deemed to be a key factor in the context of epilepsy surgery. However, the question of how to extract an exact epileptogenic network for each patient remains an open problem in the field of neuroscience. To address these challenges, we propose a novel model (BrainNet) that jointly learns the dynamic diffusion graphs and models the brain wave diffusion patterns. In addition, our model effectively aids in resisting label imbalance and severe noise by employing several self-supervised learning tasks and a hierarchical framework. By experimenting with the extensive real SEEG dataset obtained from multiple patients, we find that BrainNet outperforms several latest state-of-the-art baselines derived from time-series analysis.
MBrain: A Multi-channel Self-Supervised Learning Framework for Brain Signals
Jun 15, 2023Brain signals are important quantitative data for understanding physiological activities and diseases of human brain. Most existing studies pay attention to supervised learning methods, which, however, require high-cost clinical labels. In addition, the huge difference in the clinical patterns of brain signals measured by invasive (e.g., SEEG) and non-invasive (e.g., EEG) methods leads to the lack of a unified method. To handle the above issues, we propose to study the self-supervised learning (SSL) framework for brain signals that can be applied to pre-train either SEEG or EEG data. Intuitively, brain signals, generated by the firing of neurons, are transmitted among different connecting structures in human brain. Inspired by this, we propose MBrain to learn implicit spatial and temporal correlations between different channels (i.e., contacts of the electrode, corresponding to different brain areas) as the cornerstone for uniformly modeling different types of brain signals. Specifically, we represent the spatial correlation by a graph structure, which is built with proposed multi-channel CPC. We theoretically prove that optimizing the goal of multi-channel CPC can lead to a better predictive representation and apply the instantaneou-time-shift prediction task based on it. Then we capture the temporal correlation by designing the delayed-time-shift prediction task. Finally, replace-discriminative-learning task is proposed to preserve the characteristics of each channel. Extensive experiments of seizure detection on both EEG and SEEG large-scale real-world datasets demonstrate that our model outperforms several state-of-the-art time series SSL and unsupervised models, and has the ability to be deployed to clinical practice.