 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
PD$^3$: A Project Duplication Detection Framework via Adapted Multi-Agent Debate
May 23, 2025Project duplication detection is critical for project quality assessment, as it improves resource utilization efficiency by preventing investing in newly proposed project that have already been studied. It requires the ability to understand high-level semantics and generate constructive and valuable feedback. Existing detection methods rely on basic word- or sentence-level comparison or solely apply large language models, lacking valuable insights for experts and in-depth comprehension of project content and review criteria. To tackle this issue, we propose PD$^3$, a Project Duplication Detection framework via adapted multi-agent Debate. Inspired by real-world expert debates, it employs a fair competition format to guide multi-agent debate to retrieve relevant projects. For feedback, it incorporates both qualitative and quantitative analysis to improve its practicality. Over 800 real-world power project data spanning more than 20 specialized fields are used to evaluate the framework, demonstrating that our method outperforms existing approaches by 7.43% and 8.00% in two downstream tasks. Furthermore, we establish an online platform, Review Dingdang, to assist power experts, saving 5.73 million USD in initial detection on more than 100 newly proposed projects.
Mitigating Hallucinations on Object Attributes using Multiview Images and Negative Instructions
Jan 17, 2025



Current popular Large Vision-Language Models (LVLMs) are suffering from Hallucinations on Object Attributes (HoOA), leading to incorrect determination of fine-grained attributes in the input images. Leveraging significant advancements in 3D generation from a single image, this paper proposes a novel method to mitigate HoOA in LVLMs. This method utilizes multiview images sampled from generated 3D representations as visual prompts for LVLMs, thereby providing more visual information from other viewpoints. Furthermore, we observe the input order of multiple multiview images significantly affects the performance of LVLMs. Consequently, we have devised Multiview Image Augmented VLM (MIAVLM), incorporating a Multiview Attributes Perceiver (MAP) submodule capable of simultaneously eliminating the influence of input image order and aligning visual information from multiview images with Large Language Models (LLMs). Besides, we designed and employed negative instructions to mitigate LVLMs' bias towards ``Yes" responses. Comprehensive experiments demonstrate the effectiveness of our method.
TrafficGPT: Towards Multi-Scale Traffic Analysis and Generation with Spatial-Temporal Agent Framework
May 08, 2024The precise prediction of multi-scale traffic is a ubiquitous challenge in the urbanization process for car owners, road administrators, and governments. In the case of complex road networks, current and past traffic information from both upstream and downstream roads are crucial since various road networks have different semantic information about traffic. Rationalizing the utilization of semantic information can realize short-term, long-term, and unseen road traffic prediction. As the demands of multi-scale traffic analysis increase, on-demand interactions and visualizations are expected to be available for transportation participants. We have designed a multi-scale traffic generation system, namely TrafficGPT, using three AI agents to process multi-scale traffic data, conduct multi-scale traffic analysis, and present multi-scale visualization results. TrafficGPT consists of three essential AI agents: 1) a text-to-demand agent that is employed with Question & Answer AI to interact with users and extract prediction tasks through texts; 2) a traffic prediction agent that leverages multi-scale traffic data to generate temporal features and similarity, and fuse them with limited spatial features and similarity, to achieve accurate prediction of three tasks; and 3) a suggestion and visualization agent that uses the prediction results to generate suggestions and visualizations, providing users with a comprehensive understanding of traffic conditions. Our TrafficGPT system focuses on addressing concerns about traffic prediction from transportation participants, and conducted extensive experiments on five real-world road datasets to demonstrate its superior predictive and interactive performance
Small Object Detection via Coarse-to-fine Proposal Generation and Imitation Learning
Aug 18, 2023



The past few years have witnessed the immense success of object detection, while current excellent detectors struggle on tackling size-limited instances. Concretely, the well-known challenge of low overlaps between the priors and object regions leads to a constrained sample pool for optimization, and the paucity of discriminative information further aggravates the recognition. To alleviate the aforementioned issues, we propose CFINet, a two-stage framework tailored for small object detection based on the Coarse-to-fine pipeline and Feature Imitation learning. Firstly, we introduce Coarse-to-fine RPN (CRPN) to ensure sufficient and high-quality proposals for small objects through the dynamic anchor selection strategy and cascade regression. Then, we equip the conventional detection head with a Feature Imitation (FI) branch to facilitate the region representations of size-limited instances that perplex the model in an imitation manner. Moreover, an auxiliary imitation loss following supervised contrastive learning paradigm is devised to optimize this branch. When integrated with Faster RCNN, CFINet achieves state-of-the-art performance on the large-scale small object detection benchmarks, SODA-D and SODA-A, underscoring its superiority over baseline detector and other mainstream detection approaches.
DAC-MR: Data Augmentation Consistency Based Meta-Regularization for Meta-Learning
May 13, 2023



Meta learning recently has been heavily researched and helped advance the contemporary machine learning. However, achieving well-performing meta-learning model requires a large amount of training tasks with high-quality meta-data representing the underlying task generalization goal, which is sometimes difficult and expensive to obtain for real applications. Current meta-data-driven meta-learning approaches, however, are fairly hard to train satisfactory meta-models with imperfect training tasks. To address this issue, we suggest a meta-knowledge informed meta-learning (MKIML) framework to improve meta-learning by additionally integrating compensated meta-knowledge into meta-learning process. We preliminarily integrate meta-knowledge into meta-objective via using an appropriate meta-regularization (MR) objective to regularize capacity complexity of the meta-model function class to facilitate better generalization on unseen tasks. As a practical implementation, we introduce data augmentation consistency to encode invariance as meta-knowledge for instantiating MR objective, denoted by DAC-MR. The proposed DAC-MR is hopeful to learn well-performing meta-models from training tasks with noisy, sparse or unavailable meta-data. We theoretically demonstrate that DAC-MR can be treated as a proxy meta-objective used to evaluate meta-model without high-quality meta-data. Besides, meta-data-driven meta-loss objective combined with DAC-MR is capable of achieving better meta-level generalization. 10 meta-learning tasks with different network architectures and benchmarks substantiate the capability of our DAC-MR on aiding meta-model learning. Fine performance of DAC-MR are obtained across all settings, and are well-aligned with our theoretical insights. This implies that our DAC-MR is problem-agnostic, and hopeful to be readily applied to extensive meta-learning problems and tasks.
Towards Large-Scale Small Object Detection: Survey and Benchmarks
Jul 31, 2022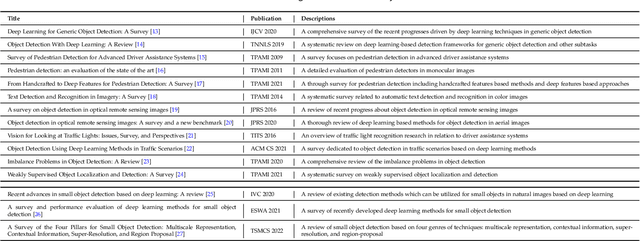
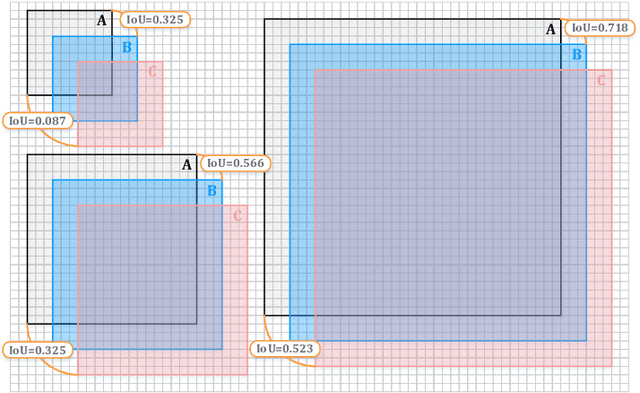
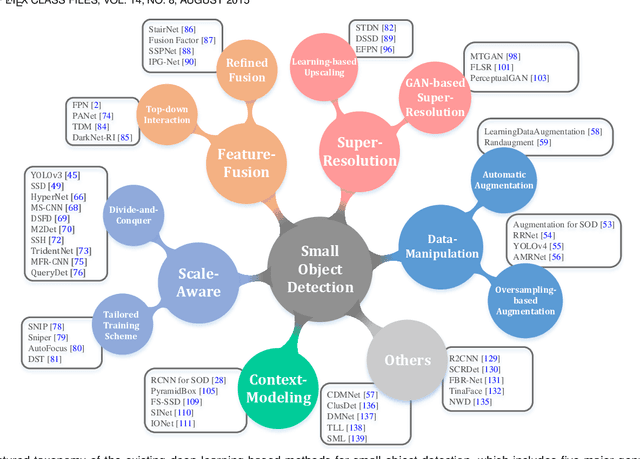
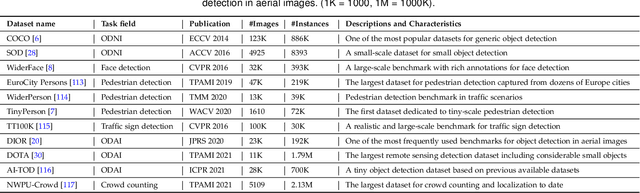
With the rise of deep convolutional neural networks, object detection has achieved prominent advances in past years. However, such prosperity could not camouflage the unsatisfactory situation of Small Object Detection (SOD), one of the notoriously challenging tasks in computer vision, owing to the poor visual appearance and noisy representation caused by the intrinsic structure of small targets. In addition, large-scale dataset for benchmarking small object detection methods remains a bottleneck. In this paper, we first conduct a thorough review of small object detection. Then, to catalyze the development of SOD, we construct two large-scale Small Object Detection dAtasets (SODA), SODA-D and SODA-A, which focus on the Driving and Aerial scenarios respectively. SODA-D includes 24704 high-quality traffic images and 277596 instances of 9 categories. For SODA-A, we harvest 2510 high-resolution aerial images and annotate 800203 instances over 9 classes. The proposed datasets, as we know, are the first-ever attempt to large-scale benchmarks with a vast collection of exhaustively annotated instances tailored for multi-category SOD. Finally, we evaluate the performance of mainstream methods on SODA. We expect the released benchmarks could facilitate the development of SOD and spawn more breakthroughs in this field. Datasets and codes will be available soon at: \url{https://shaunyuan22.github.io/SODA}.
CMW-Net: Learning a Class-Aware Sample Weighting Mapping for Robust Deep Learning
Feb 22, 2022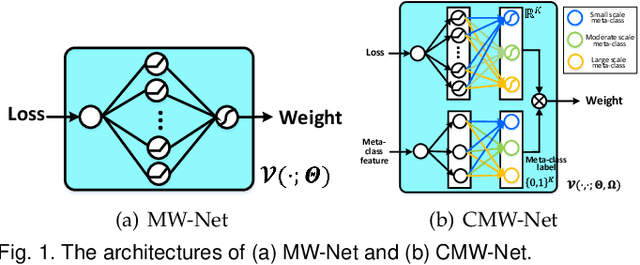
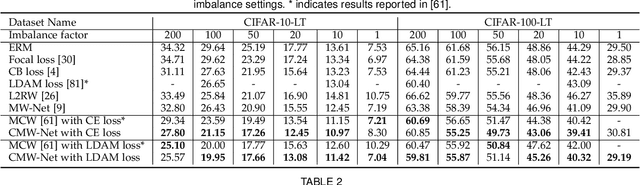
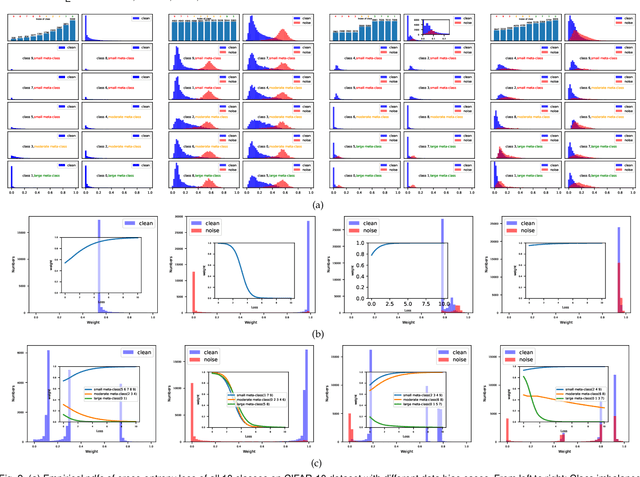
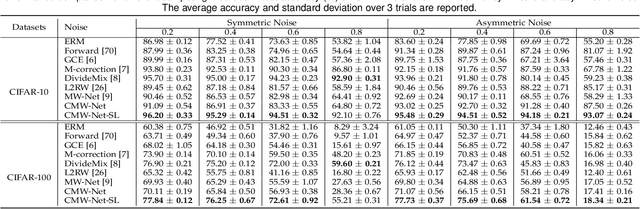
Modern deep neural networks can easily overfit to biased training data containing corrupted labels or class imbalance. Sample re-weighting methods are popularly used to alleviate this data bias issue. Most current methods, however, require to manually pre-specify the weighting schemes as well as their additional hyper-parameters relying on the characteristics of the investigated problem and training data. This makes them fairly hard to be generally applied in practical scenarios, due to their significant complexities and inter-class variations of data bias situations. To address this issue, we propose a meta-model capable of adaptively learning an explicit weighting scheme directly from data. Specifically, by seeing each training class as a separate learning task, our method aims to extract an explicit weighting function with sample loss and task/class feature as input, and sample weight as output, expecting to impose adaptively varying weighting schemes to different sample classes based on their own intrinsic bias characteristics. Synthetic and real data experiments substantiate the capability of our method on achieving proper weighting schemes in various data bias cases, like the class imbalance, feature-independent and dependent label noise scenarios, and more complicated bias scenarios beyond conventional cases. Besides, the task-transferability of the learned weighting scheme is also substantiated, by readily deploying the weighting function learned on relatively smaller-scale CIFAR-10 dataset on much larger-scale full WebVision dataset. A performance gain can be readily achieved compared with previous SOAT ones without additional hyper-parameter tuning and meta gradient descent step. The general availability of our method for multiple robust deep learning issues, including partial-label learning, semi-supervised learning and selective classification, has also been validated.