 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMW-Net: Learning a Class-Aware Sample Weighting Mapping for Robust Deep Learning
Paper and Code
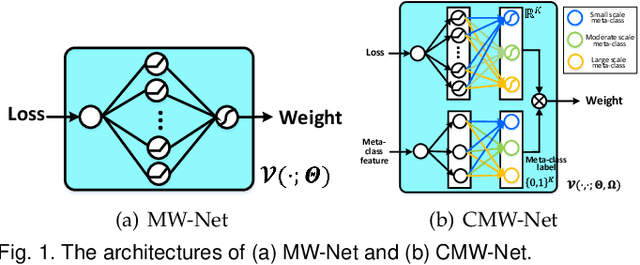
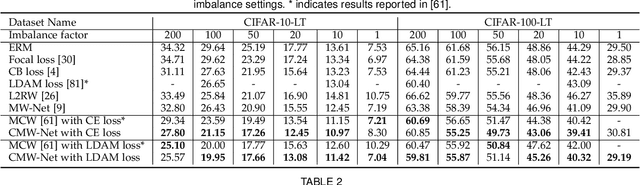
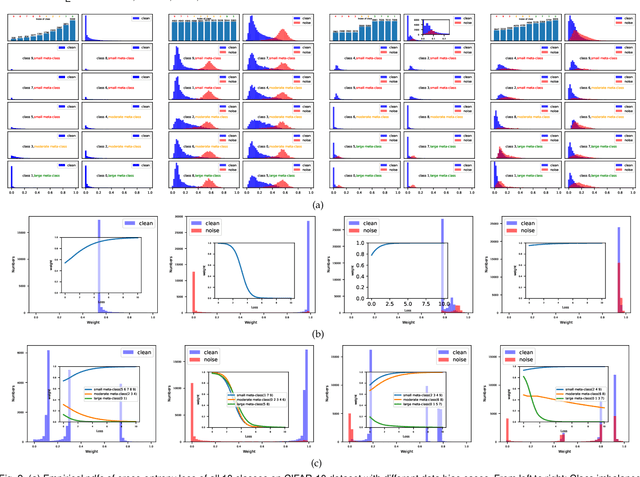
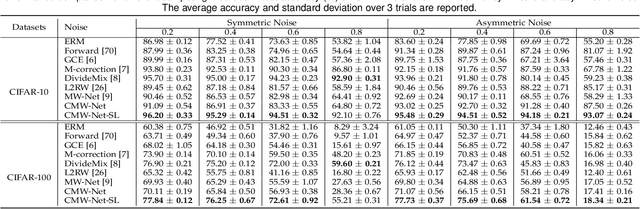
Modern deep neural networks can easily overfit to biased training data containing corrupted labels or class imbalance. Sample re-weighting methods are popularly used to alleviate this data bias issue. Most current methods, however, require to manually pre-specify the weighting schemes as well as their additional hyper-parameters relying on the characteristics of the investigated problem and training data. This makes them fairly hard to be generally applied in practical scenarios, due to their significant complexities and inter-class variations of data bias situations. To address this issue, we propose a meta-model capable of adaptively learning an explicit weighting scheme directly from data. Specifically, by seeing each training class as a separate learning task, our method aims to extract an explicit weighting function with sample loss and task/class feature as input, and sample weight as output, expecting to impose adaptively varying weighting schemes to different sample classes based on their own intrinsic bias characteristics. Synthetic and real data experiments substantiate the capability of our method on achieving proper weighting schemes in various data bias cases, like the class imbalance, feature-independent and dependent label noise scenarios, and more complicated bias scenarios beyond conventional cases. Besides, the task-transferability of the learned weighting scheme is also substantiated, by readily deploying the weighting function learned on relatively smaller-scale CIFAR-10 dataset on much larger-scale full WebVision dataset. A performance gain can be readily achieved compared with previous SOAT ones without additional hyper-parameter tuning and meta gradient descent step. The general availability of our method for multiple robust deep learning issues, including partial-label learning, semi-supervised learning and selective classification, has also been validated.