 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoopGen: Koopman Generator Networks for Representing and Predicting Dynamical Systems with Continuous Spectra
Feb 15, 2026Representing and predicting high-dimensional and spatiotemporally chaotic dynamical systems remains a fundamental challenge in dynamical systems and machine learning. Although data-driven models can achieve accurate short-term forecasts, they often lack stability, interpretability, and scalability in regimes dominated by broadband or continuous spectra. Koopman-based approaches provide a principled linear perspective on nonlinear dynamics, but existing methods rely on restrictive finite-dimensional assumptions or explicit spectral parameterizations that degrade in high-dimensional settings. Against these issues, we introduce KoopGen, a generator-based neural Koopman framework that models dynamics through a structured, state-dependent representation of Koopman generators. By exploiting the intrinsic Cartesian decomposition into skew-adjoint and self-adjoint components, KoopGen separates conservative transport from irreversible dissipation while enforcing exact operator-theoretic constraints during learning. Across systems ranging from nonlinear oscillators to high-dimensional chaotic and spatiotemporal dynamics, KoopGen improves prediction accuracy and stability, while clarifying which components of continuous-spectrum dynamics admit interpretable and learnable representations.
DuMeta++: Spatiotemporal Dual Meta-Learning for Generalizable Few-Shot Brain Tissue Segmentation Across Diverse Ages
Feb 06, 2026Accurate segmentation of brain tissues from MRI scans is critical for neuroscience and clinical applications, but achieving consistent performance across the human lifespan remains challenging due to dynamic, age-related changes in brain appearance and morphology. While prior work has sought to mitigate these shifts by using self-supervised regularization with paired longitudinal data, such data are often unavailable in practice. To address this, we propose \emph{DuMeta++}, a dual meta-learning framework that operates without paired longitudinal data. Our approach integrates: (1) meta-feature learning to extract age-agnostic semantic representations of spatiotemporally evolving brain structures, and (2) meta-initialization learning to enable data-efficient adaptation of the segmentation model. Furthermore, we propose a memory-bank-based class-aware regularization strategy to enforce longitudinal consistency without explicit longitudinal supervision. We theoretically prove the convergence of our DuMeta++, ensuring stability. Experiments on diverse datasets (iSeg-2019, IBIS, OASIS, ADNI) under few-shot settings demonstrate that DuMeta++ outperforms existing methods in cross-age generalization. Code will be available at https://github.com/ladderlab-xjtu/DuMeta++.
Improving Memory Efficiency for Training KANs via Meta Learning
Jun 09, 2025Inspired by the Kolmogorov-Arnold representation theorem, KANs offer a novel framework for function approximation by replacing traditional neural network weights with learnable univariate functions. This design demonstrates significant potential as an efficient and interpretable alternative to traditional MLPs. However, KANs are characterized by a substantially larger number of trainable parameters, leading to challenges in memory efficiency and higher training costs compared to MLPs. To address this limitation, we propose to generate weights for KANs via a smaller meta-learner, called MetaKANs. By training KANs and MetaKANs in an end-to-end differentiable manner, MetaKANs achieve comparable or even superior performance while significantly reducing the number of trainable parameters and maintaining promising interpretability. Extensive experiments on diverse benchmark tasks, including symbolic regression, partial differential equation solving, and image classification, demonstrate the effectiveness of MetaKANs in improving parameter efficiency and memory usage. The proposed method provides an alternative technique for training KANs, that allows for greater scalability and extensibility, and narrows the training cost gap with MLPs stated in the original paper of KANs. Our code is available at https://github.com/Murphyzc/MetaKAN.
Removing Multiple Hybrid Adverse Weather in Video via a Unified Model
Mar 08, 2025Videos captured under real-world adverse weather conditions typically suffer from uncertain hybrid weather artifacts with heterogeneous degradation distributions. However, existing algorithms only excel at specific single degradation distributions due to limited adaption capacity and have to deal with different weather degradations with separately trained models, thus may fail to handle real-world stochastic weather scenarios. Besides, the model training is also infeasible due to the lack of paired video data to characterize the coexistence of multiple weather. To ameliorate the aforementioned issue, we propose a novel unified model, dubbed UniWRV, to remove multiple heterogeneous video weather degradations in an all-in-one fashion. Specifically, to tackle degenerate spatial feature heterogeneity, we propose a tailored weather prior guided module that queries exclusive priors for different instances as prompts to steer spatial feature characterization. To tackle degenerate temporal feature heterogeneity, we propose a dynamic routing aggregation module that can automatically select optimal fusion paths for different instances to dynamically integrate temporal features. Additionally, we managed to construct a new synthetic video dataset, termed HWVideo, for learning and benchmarking multiple hybrid adverse weather removal, which contains 15 hybrid weather conditions with a total of 1500 adverse-weather/clean paired video clips. Real-world hybrid weather videos are also collected for evaluating model generalizability. Comprehensive experiments demonstrate that our UniWRV exhibits robust and superior adaptation capability in multiple heterogeneous degradations learning scenarios, including various generic video restoration tasks beyond weather removal.
On the Noise Robustness of In-Context Learning for Text Generation
May 27, 2024



Large language models (LLMs) have shown impressive performance on downstream tasks by in-context learning (ICL), which heavily relies on the quality of demonstrations selected from a large set of annotated examples. Recent works claim that in-context learning is robust to noisy demonstrations in text classification. In this work, we show that, on text generation tasks, noisy annotations significantly hurt the performance of in-context learning. To circumvent the issue, we propose a simple and effective approach called Local Perplexity Ranking (LPR), which replaces the "noisy" candidates with their nearest neighbors that are more likely to be clean. Our method is motivated by analyzing the perplexity deviation caused by noisy labels and decomposing perplexity into inherent perplexity and matching perplexity. Our key idea behind LPR is thus to decouple the matching perplexity by performing the ranking among the neighbors in semantic space. Our approach can prevent the selected demonstrations from including mismatched input-label pairs while preserving the effectiveness of the original selection methods. Extensive experiments demonstrate the effectiveness of LPR, improving the EM score by up to 18.75 on common benchmarks with noisy annotations.
Are Dense Labels Always Necessary for 3D Object Detection from Point Cloud?
Mar 05, 2024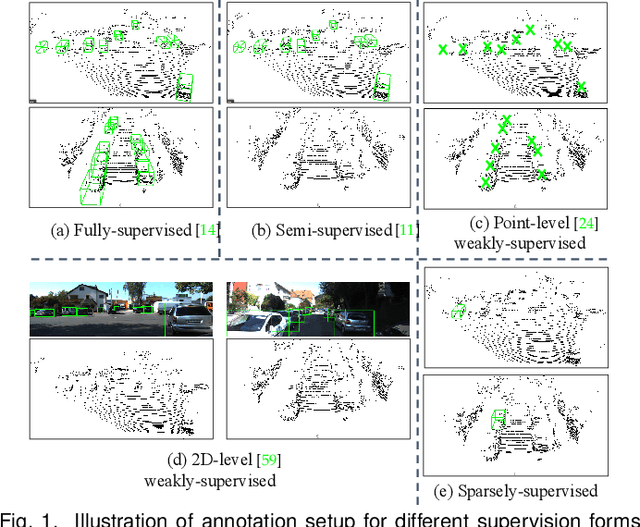



Current state-of-the-art (SOTA) 3D object detection methods often require a large amount of 3D bounding box annotations for training. However, collecting such large-scale densely-supervised datasets is notoriously costly. To reduce the cumbersome data annotation process, we propose a novel sparsely-annotated framework, in which we just annotate one 3D object per scene. Such a sparse annotation strategy could significantly reduce the heavy annotation burden, while inexact and incomplete sparse supervision may severely deteriorate the detection performance. To address this issue, we develop the SS3D++ method that alternatively improves 3D detector training and confident fully-annotated scene generation in a unified learning scheme. Using sparse annotations as seeds, we progressively generate confident fully-annotated scenes based on designing a missing-annotated instance mining module and reliable background mining module. Our proposed method produces competitive results when compared with SOTA weakly-supervised methods using the same or even more annotation costs. Besides, compared with SOTA fully-supervised methods, we achieve on-par or even better performance on the KITTI dataset with about 5x less annotation cost, and 90% of their performance on the Waymo dataset with about 15x less annotation cost. The additional unlabeled training scenes could further boost the performance. The code will be available at https://github.com/gaocq/SS3D2.
Dual Meta-Learning with Longitudinally Generalized Regularization for One-Shot Brain Tissue Segmentation Across the Human Lifespan
Aug 13, 2023

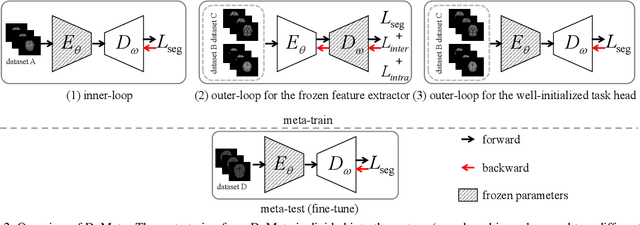
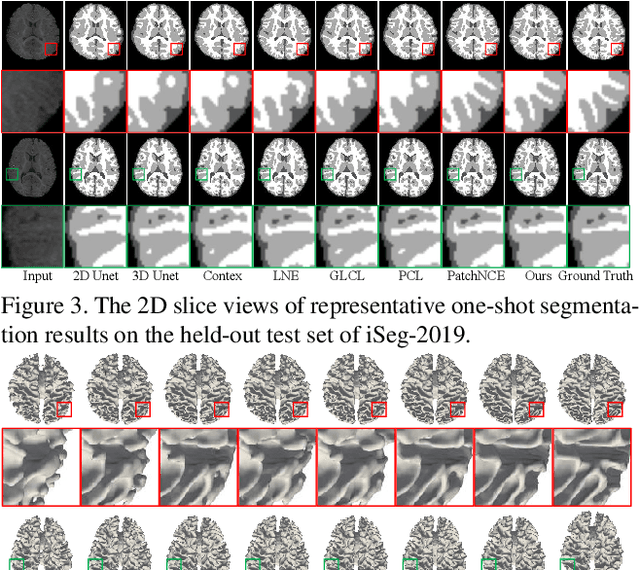
Brain tissue segmentation is essential for neuroscience and clinical studies. However, segmentation on longitudinal data is challenging due to dynamic brain changes across the lifespan. Previous researches mainly focus on self-supervision with regularizations and will lose longitudinal generalization when fine-tuning on a specific age group. In this paper, we propose a dual meta-learning paradigm to learn longitudinally consistent representations and persist when fine-tuning. Specifically, we learn a plug-and-play feature extractor to extract longitudinal-consistent anatomical representations by meta-feature learning and a well-initialized task head for fine-tuning by meta-initialization learning. Besides, two class-aware regularizations are proposed to encourage longitudinal consistency. Experimental results on the iSeg2019 and ADNI datasets demonstrate the effectiveness of our method. Our code is available at https://github.com/ladderlab-xjtu/DuMeta.
DAC-MR: Data Augmentation Consistency Based Meta-Regularization for Meta-Learning
May 13, 2023



Meta learning recently has been heavily researched and helped advance the contemporary machine learning. However, achieving well-performing meta-learning model requires a large amount of training tasks with high-quality meta-data representing the underlying task generalization goal, which is sometimes difficult and expensive to obtain for real applications. Current meta-data-driven meta-learning approaches, however, are fairly hard to train satisfactory meta-models with imperfect training tasks. To address this issue, we suggest a meta-knowledge informed meta-learning (MKIML) framework to improve meta-learning by additionally integrating compensated meta-knowledge into meta-learning process. We preliminarily integrate meta-knowledge into meta-objective via using an appropriate meta-regularization (MR) objective to regularize capacity complexity of the meta-model function class to facilitate better generalization on unseen tasks. As a practical implementation, we introduce data augmentation consistency to encode invariance as meta-knowledge for instantiating MR objective, denoted by DAC-MR. The proposed DAC-MR is hopeful to learn well-performing meta-models from training tasks with noisy, sparse or unavailable meta-data. We theoretically demonstrate that DAC-MR can be treated as a proxy meta-objective used to evaluate meta-model without high-quality meta-data. Besides, meta-data-driven meta-loss objective combined with DAC-MR is capable of achieving better meta-level generalization. 10 meta-learning tasks with different network architectures and benchmarks substantiate the capability of our DAC-MR on aiding meta-model learning. Fine performance of DAC-MR are obtained across all settings, and are well-aligned with our theoretical insights. This implies that our DAC-MR is problem-agnostic, and hopeful to be readily applied to extensive meta-learning problems and tasks.
Improve Noise Tolerance of Robust Loss via Noise-Awareness
Jan 18, 2023Robust loss minimization is an important strategy for handling robust learning issue on noisy labels. Current robust losses, however, inevitably involve hyperparameters to be tuned for different datasets with noisy labels, manually or heuristically through cross validation, which makes them fairly hard to be generally applied in practice. Existing robust loss methods usually assume that all training samples share common hyperparameters, which are independent of instances. This limits the ability of these methods on distinguishing individual noise properties of different samples, making them hardly adapt to different noise structures. To address above issues, we propose to assemble robust loss with instance-dependent hyperparameters to improve their noise-tolerance with theoretical guarantee. To achieve setting such instance-dependent hyperparameters for robust loss, we propose a meta-learning method capable of adaptively learning a hyperparameter prediction function, called Noise-Aware-Robust-Loss-Adjuster (NARL-Adjuster). Specifically, through mutual amelioration between hyperparameter prediction function and classifier parameters in our method, both of them can be simultaneously finely ameliorated and coordinated to attain solutions with good generalization capability. Four kinds of SOTA robust losses are attempted to be integrated with our algorithm, and experiments substantiate the general availability and effectiveness of the proposed method in both its noise tolerance and generalization performance. Meanwhile, the explicit parameterized structure makes the meta-learned prediction function capable of being readily transferrable and plug-and-play to unseen datasets with noisy labels. Specifically, we transfer our meta-learned NARL-Adjuster to unseen tasks, including several real noisy datasets, and achieve better performance compared with conventional hyperparameter tuning strategy.
CMW-Net: Learning a Class-Aware Sample Weighting Mapping for Robust Deep Learning
Feb 22, 2022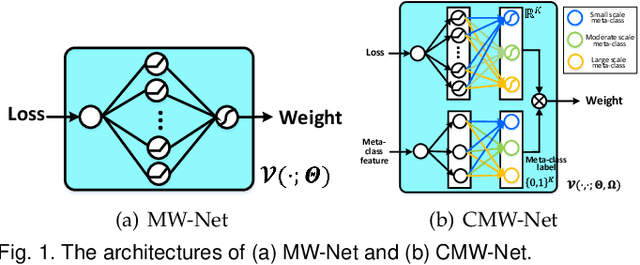
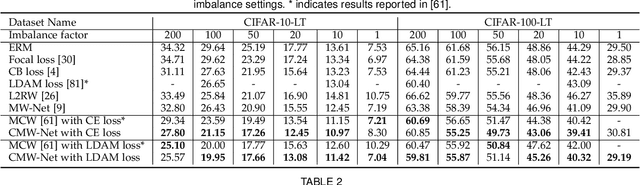
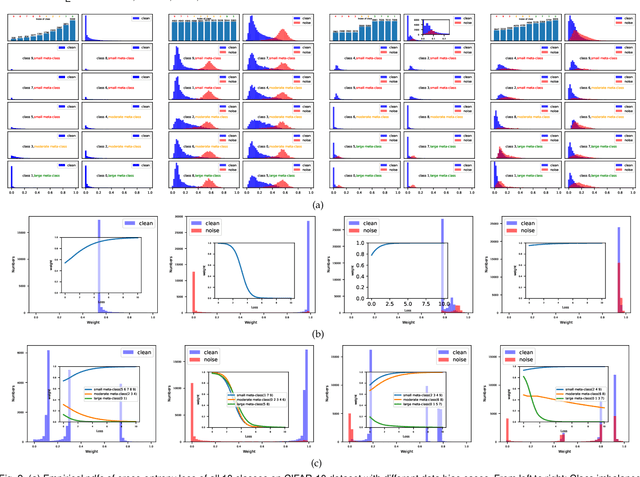
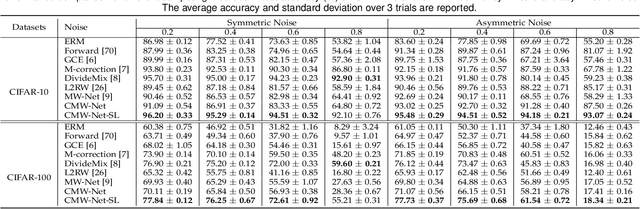
Modern deep neural networks can easily overfit to biased training data containing corrupted labels or class imbalance. Sample re-weighting methods are popularly used to alleviate this data bias issue. Most current methods, however, require to manually pre-specify the weighting schemes as well as their additional hyper-parameters relying on the characteristics of the investigated problem and training data. This makes them fairly hard to be generally applied in practical scenarios, due to their significant complexities and inter-class variations of data bias situations. To address this issue, we propose a meta-model capable of adaptively learning an explicit weighting scheme directly from data. Specifically, by seeing each training class as a separate learning task, our method aims to extract an explicit weighting function with sample loss and task/class feature as input, and sample weight as output, expecting to impose adaptively varying weighting schemes to different sample classes based on their own intrinsic bias characteristics. Synthetic and real data experiments substantiate the capability of our method on achieving proper weighting schemes in various data bias cases, like the class imbalance, feature-independent and dependent label noise scenarios, and more complicated bias scenarios beyond conventional cases. Besides, the task-transferability of the learned weighting scheme is also substantiated, by readily deploying the weighting function learned on relatively smaller-scale CIFAR-10 dataset on much larger-scale full WebVision dataset. A performance gain can be readily achieved compared with previous SOAT ones without additional hyper-parameter tuning and meta gradient descent step. The general availability of our method for multiple robust deep learning issues, including partial-label learning, semi-supervised learning and selective classification, has also been validated.