 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Are Vision-Language Models from Constructing the Real World? A Benchmark for Physical Generative Reasoning
Mar 25, 2026The physical world is not merely visual; it is governed by rigorous structural and procedural constraints. Yet, the evaluation of vision-language models (VLMs) remains heavily skewed toward perceptual realism, prioritizing the generation of visually plausible 3D layouts, shapes, and appearances. Current benchmarks rarely test whether models grasp the step-by-step processes and physical dependencies required to actually build these artifacts, a capability essential for automating design-to-construction pipelines. To address this, we introduce DreamHouse, a novel benchmark for physical generative reasoning: the capacity to synthesize artifacts that concurrently satisfy geometric, structural, constructability, and code-compliance constraints. We ground this benchmark in residential timber-frame construction, a domain with fully codified engineering standards and objectively verifiable correctness. We curate over 26,000 structures spanning 13 architectural styles, ach verified to construction-document standards (LOD 350) and develop a deterministic 10-test structural validation framework. Unlike static benchmarks that assess only final outputs, DreamHouse supports iterative agentic interaction. Models observe intermediate build states, generate construction actions, and receive structured environmental feedback, enabling a fine-grained evaluation of planning, structural reasoning, and self-correction. Extensive experiments with state-of-the-art VLMs reveal substantial capability gaps that are largely invisible on existing leaderboards. These findings establish physical validity as a critical evaluation axis orthogonal to visual realism, highlighting physical generative reasoning as a distinct and underdeveloped frontier in multimodal intelligence. Available at https://luluyuyuyang.github.io/dreamhouse
Future Optical Flow Prediction Improves Robot Control & Video Generation
Jan 15, 2026Future motion representations, such as optical flow, offer immense value for control and generative tasks. However, forecasting generalizable spatially dense motion representations remains a key challenge, and learning such forecasting from noisy, real-world data remains relatively unexplored. We introduce FOFPred, a novel language-conditioned optical flow forecasting model featuring a unified Vision-Language Model (VLM) and Diffusion architecture. This unique combination enables strong multimodal reasoning with pixel-level generative fidelity for future motion prediction. Our model is trained on web-scale human activity data-a highly scalable but unstructured source. To extract meaningful signals from this noisy video-caption data, we employ crucial data preprocessing techniques and our unified architecture with strong image pretraining. The resulting trained model is then extended to tackle two distinct downstream tasks in control and generation. Evaluations across robotic manipulation and video generation under language-driven settings establish the cross-domain versatility of FOFPred, confirming the value of a unified VLM-Diffusion architecture and scalable learning from diverse web data for future optical flow prediction.
GenMM: Geometrically and Temporally Consistent Multimodal Data Generation for Video and LiDAR
Jun 15, 2024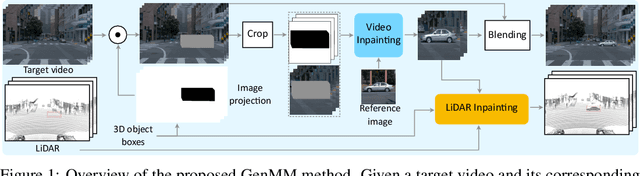
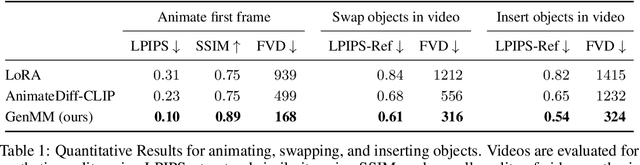
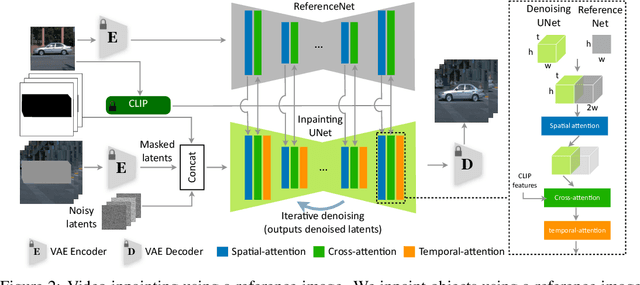

Multimodal synthetic data generation is crucial in domains such as autonomous driving, robotics, augmented/virtual reality, and retail. We propose a novel approach, GenMM, for jointly editing RGB videos and LiDAR scans by inserting temporally and geometrically consistent 3D objects. Our method uses a reference image and 3D bounding boxes to seamlessly insert and blend new objects into target videos. We inpaint the 2D Regions of Interest (consistent with 3D boxes) using a diffusion-based video inpainting model. We then compute semantic boundaries of the object and estimate it's surface depth using state-of-the-art semantic segmentation and monocular depth estimation techniques. Subsequently, we employ a geometry-based optimization algorithm to recover the 3D shape of the object's surface, ensuring it fits precisely within the 3D bounding box. Finally, LiDAR rays intersecting with the new object surface are updated to reflect consistent depths with its geometry. Our experiments demonstrate the effectiveness of GenMM in inserting various 3D objects across video and LiDAR modalities.
Are Dense Labels Always Necessary for 3D Object Detection from Point Cloud?
Mar 05, 2024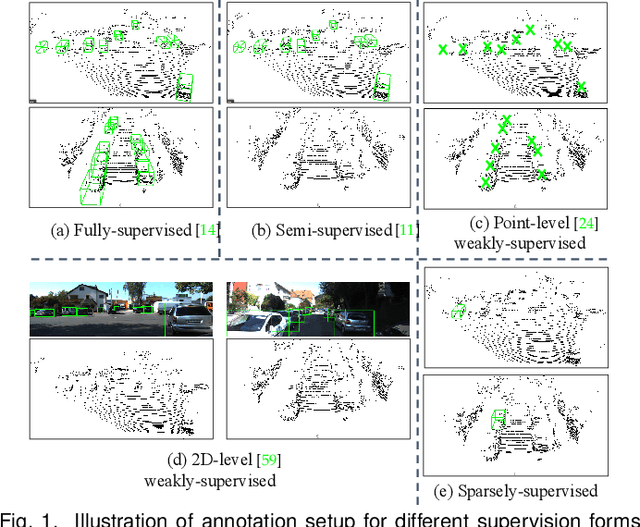



Current state-of-the-art (SOTA) 3D object detection methods often require a large amount of 3D bounding box annotations for training. However, collecting such large-scale densely-supervised datasets is notoriously costly. To reduce the cumbersome data annotation process, we propose a novel sparsely-annotated framework, in which we just annotate one 3D object per scene. Such a sparse annotation strategy could significantly reduce the heavy annotation burden, while inexact and incomplete sparse supervision may severely deteriorate the detection performance. To address this issue, we develop the SS3D++ method that alternatively improves 3D detector training and confident fully-annotated scene generation in a unified learning scheme. Using sparse annotations as seeds, we progressively generate confident fully-annotated scenes based on designing a missing-annotated instance mining module and reliable background mining module. Our proposed method produces competitive results when compared with SOTA weakly-supervised methods using the same or even more annotation costs. Besides, compared with SOTA fully-supervised methods, we achieve on-par or even better performance on the KITTI dataset with about 5x less annotation cost, and 90% of their performance on the Waymo dataset with about 15x less annotation cost. The additional unlabeled training scenes could further boost the performance. The code will be available at https://github.com/gaocq/SS3D2.
Learning Semantic Correspondence with Sparse Annotations
Aug 17, 2022
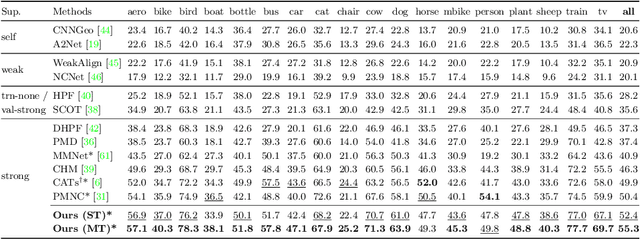
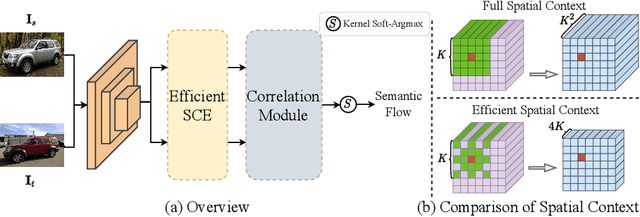
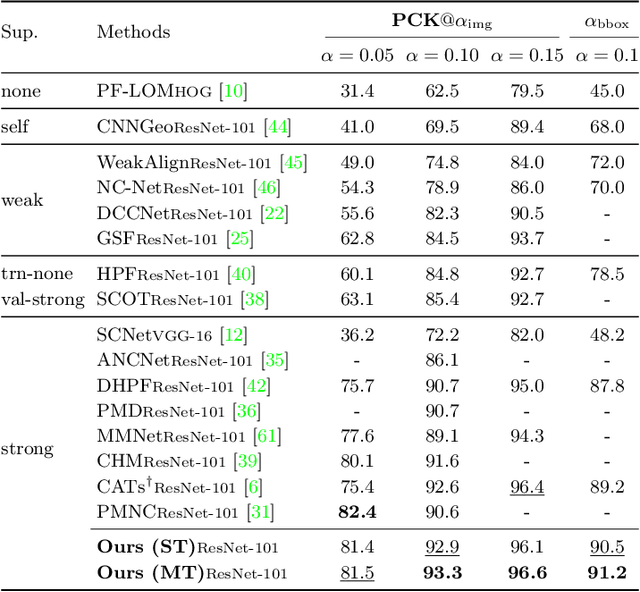
Finding dense semantic correspondence is a fundamental problem in computer vision, which remains challenging in complex scenes due to background clutter, extreme intra-class variation, and a severe lack of ground truth. In this paper, we aim to address the challenge of label sparsity in semantic correspondence by enriching supervision signals from sparse keypoint annotations. To this end, we first propose a teacher-student learning paradigm for generating dense pseudo-labels and then develop two novel strategies for denoising pseudo-labels. In particular, we use spatial priors around the sparse annotations to suppress the noisy pseudo-labels. In addition, we introduce a loss-driven dynamic label selection strategy for label denoising. We instantiate our paradigm with two variants of learning strategies: a single offline teacher setting, and mutual online teachers setting. Our approach achieves notable improvements on three challenging benchmarks for semantic correspondence and establishes the new state-of-the-art. Project page: https://shuaiyihuang.github.io/publications/SCorrSAN.
Burn After Reading: Online Adaptation for Cross-domain Streaming Data
Dec 08, 2021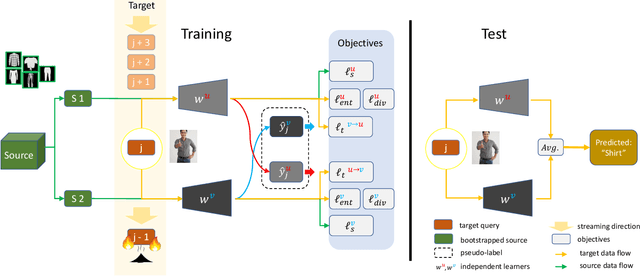
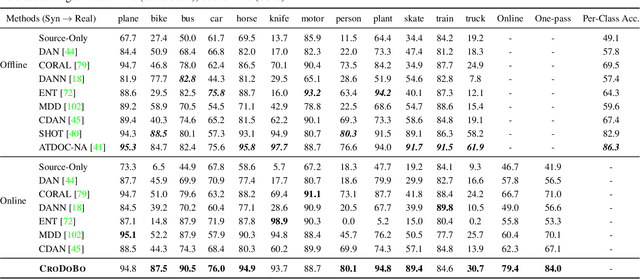

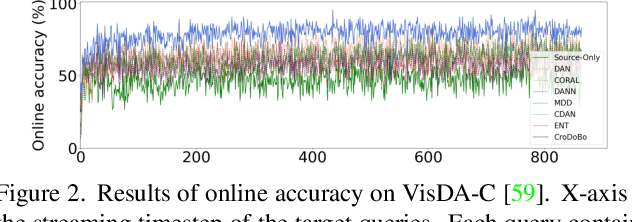
In the context of online privacy, many methods propose complex privacy and security preserving measures to protect sensitive data. In this paper, we argue that: not storing any sensitive data is the best form of security. Thus we propose an online framework that "burns after reading", i.e. each online sample is immediately deleted after it is processed. Meanwhile, we tackle the inevitable distribution shift between the labeled public data and unlabeled private data as a problem of unsupervised domain adaptation. Specifically, we propose a novel algorithm that aims at the most fundamental challenge of the online adaptation setting--the lack of diverse source-target data pairs. Therefore, we design a Cross-Domain Bootstrapping approach, called CroDoBo, to increase the combined diversity across domains. Further, to fully exploit the valuable discrepancies among the diverse combinations, we employ the training strategy of multiple learners with co-supervision. CroDoBo achieves state-of-the-art online performance on four domain adaptation benchmarks.
MiCo: Mixup Co-Training for Semi-Supervised Domain Adaptation
Jul 24, 2020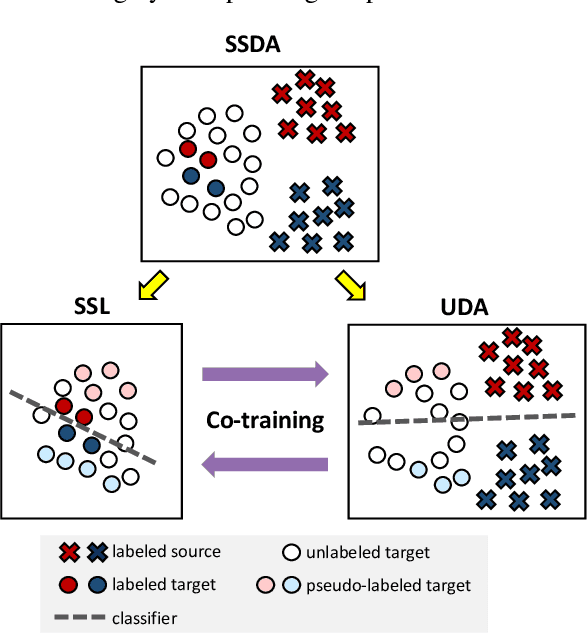
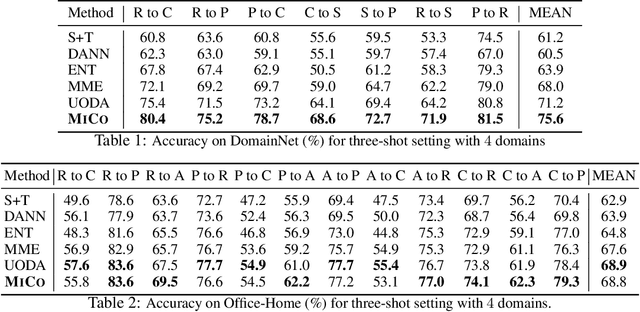
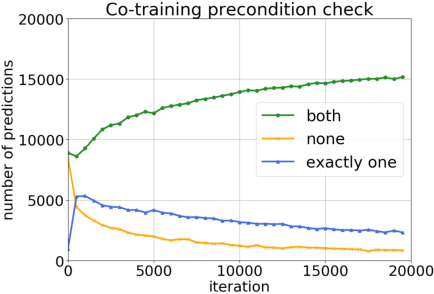
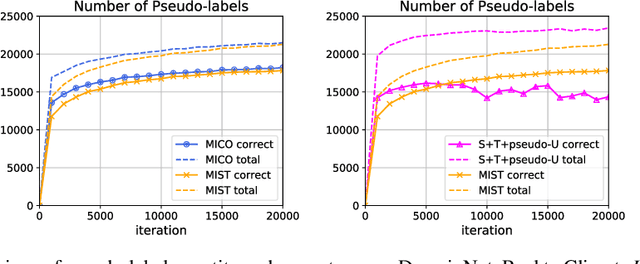
Semi-supervised domain adaptation (SSDA) aims to adapt models from a labeled source domain to a different but related target domain, from which unlabeled data and a small set of labeled data are provided. In this paper we propose a new approach for SSDA, which is to explicitly decompose SSDA into two sub-problems: a semi-supervised learning (SSL) problem in the target domain and an unsupervised domain adaptation (UDA) problem across domains. We show that these two sub-problems yield very different classifiers, which we leverage with our algorithm MixUp Co-training (MiCo). MiCo applies Mixup to bridge the gap between labeled and unlabeled data of each individual model and employs co-training to exchange the expertise between the two classifiers. MiCo needs no adversarial and minmax training, making it easily implementable and stable. MiCo achieves state-of-the-art results on SSDA datasets, outperforming the prior art by a notable 4% margin on DomainNet.
Curriculum Manager for Source Selection in Multi-Source Domain Adaptation
Jul 02, 2020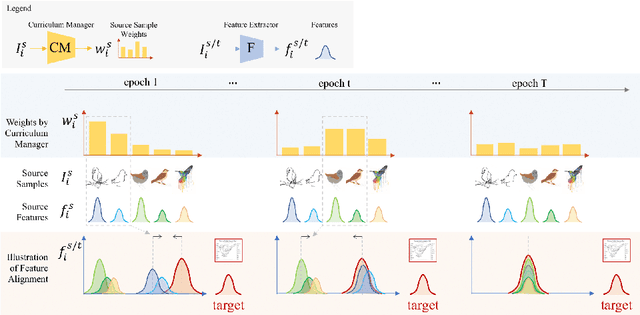
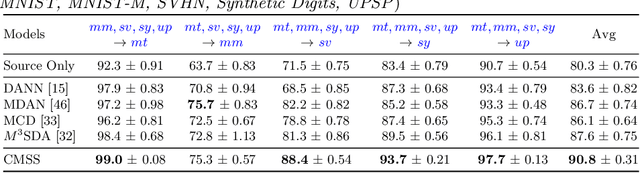
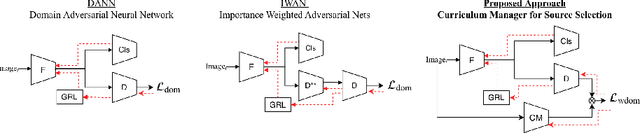

The performance of Multi-Source Unsupervised Domain Adaptation depends significantly on the effectiveness of transfer from labeled source domain samples. In this paper, we proposed an adversarial agent that learns a dynamic curriculum for source samples, called Curriculum Manager for Source Selection (CMSS). The Curriculum Manager, an independent network module, constantly updates the curriculum during training, and iteratively learns which domains or samples are best suited for aligning to the target. The intuition behind this is to force the Curriculum Manager to constantly re-measure the transferability of latent domains over time to adversarially raise the error rate of the domain discriminator. CMSS does not require any knowledge of the domain labels, yet it outperforms other methods on four well-known benchmarks by significant margins. We also provide interpretable results that shed light on the proposed method.
PM-GANs: Discriminative Representation Learning for Action Recognition Using Partial-modalities
Apr 17, 2018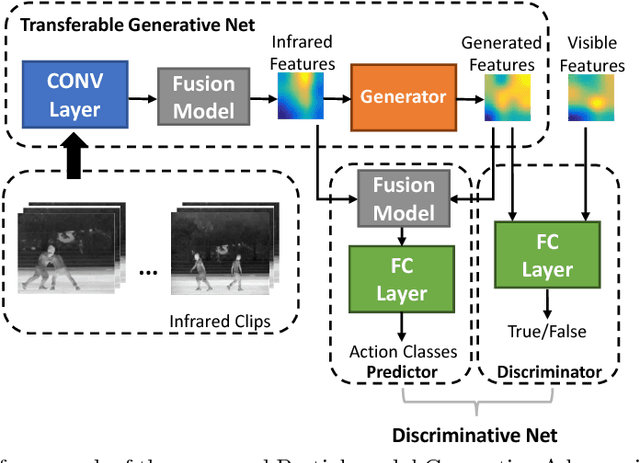
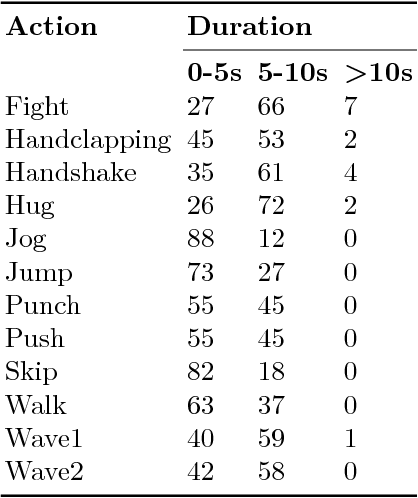
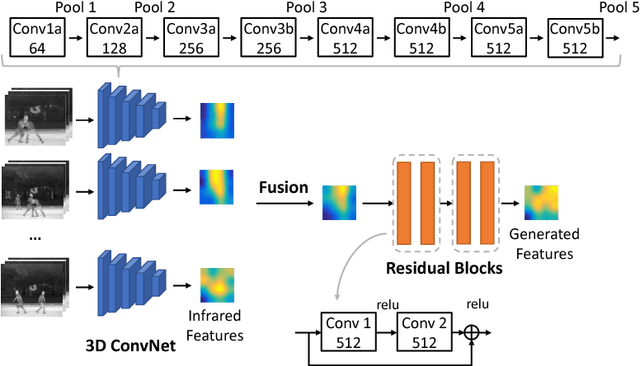

Data of different modalities generally convey complimentary but heterogeneous information, and a more discriminative representation is often preferred by combining multiple data modalities like the RGB and infrared features. However in reality, obtaining both data channels is challenging due to many limitations. For example, the RGB surveillance cameras are often restricted from private spaces, which is in conflict with the need of abnormal activity detection for personal security. As a result, using partial data channels to build a full representation of multi-modalities is clearly desired. In this paper, we propose a novel Partial-modal Generative Adversarial Networks (PM-GANs) that learns a full-modal representation using data from only partial modalities. The full representation is achieved by a generated representation in place of the missing data channel. Extensive experiments are conducted to verify the performance of our proposed method on action recognition, compared with four state-of-the-art methods. Meanwhile, a new Infrared-Visible Dataset for action recognition is introduced, and will be the first publicly available action dataset that contains paired infrared and visible spectrum.