 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAG: Boosting Text-VQA via Text-aware Visual Question-answer Generation
Aug 14, 2022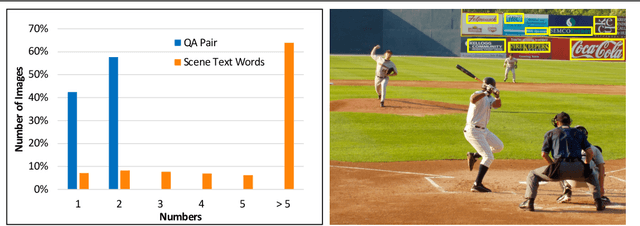
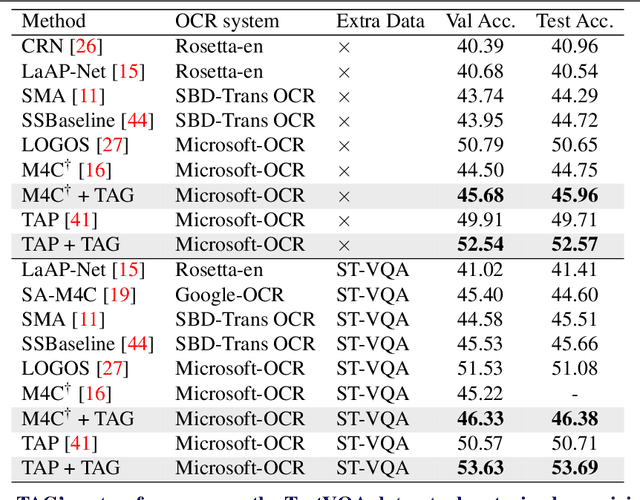

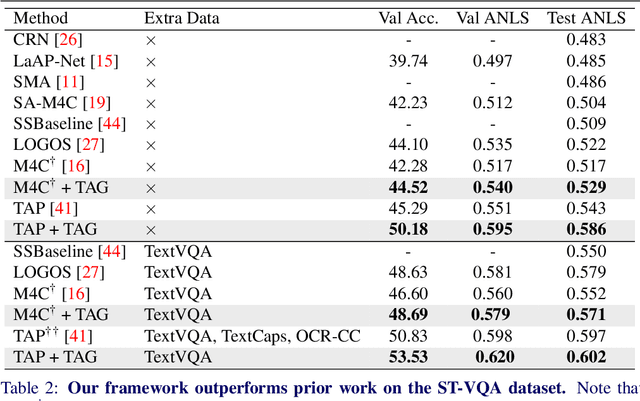
Text-VQA aims at answering questions that require understanding the textual cues in an image. Despite the great progress of existing Text-VQA methods, their performance suffers from insufficient human-labeled question-answer (QA) pairs. However, we observe that, in general, the scene text is not fully exploited in the existing datasets -- only a small portion of text in each image participates in the annotated QA activities. This results in a huge waste of useful information. To address this deficiency, we develop a new method to generate high-quality and diverse QA pairs by explicitly utilizing the existing rich text available in the scene context of each image. Specifically, we propose, TAG, a text-aware visual question-answer generation architecture that learns to produce meaningful, and accurate QA samples using a multimodal transformer. The architecture exploits underexplored scene text information and enhances scene understanding of Text-VQA models by combining the generated QA pairs with the initial training data. Extensive experimental results on two well-known Text-VQA benchmarks (TextVQA and ST-VQA) demonstrate that our proposed TAG effectively enlarges the training data that helps improve the Text-VQA performance without extra labeling effort. Moreover, our model outperforms state-of-the-art approaches that are pre-trained with extra large-scale data. Code is available at https://github.com/HenryJunW/TAG.
Use All The Labels: A Hierarchical Multi-Label Contrastive Learning Framework
Apr 27, 2022



Current contrastive learning frameworks focus on leveraging a single supervisory signal to learn representations, which limits the efficacy on unseen data and downstream tasks. In this paper, we present a hierarchical multi-label representation learning framework that can leverage all available labels and preserve the hierarchical relationship between classes. We introduce novel hierarchy preserving losses, which jointly apply a hierarchical penalty to the contrastive loss, and enforce the hierarchy constraint. The loss function is data driven and automatically adapts to arbitrary multi-label structures. Experiments on several datasets show that our relationship-preserving embedding performs well on a variety of tasks and outperform the baseline supervised and self-supervised approaches. Code is available at https://github.com/salesforce/hierarchicalContrastiveLearning.
Value Retrieval with Arbitrary Queries for Form-like Documents
Dec 15, 2021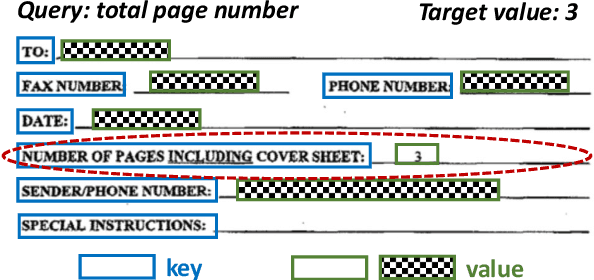

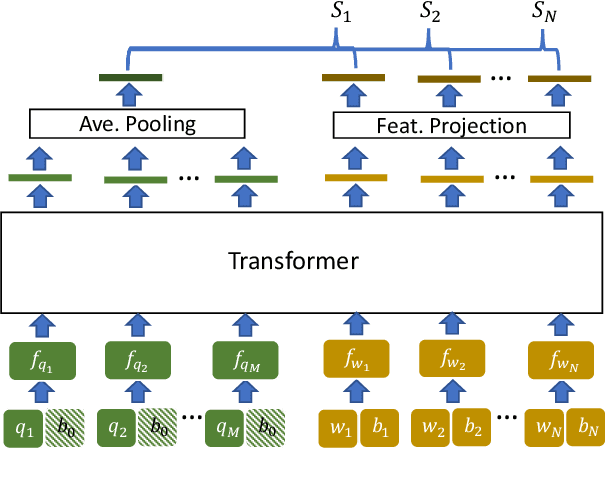
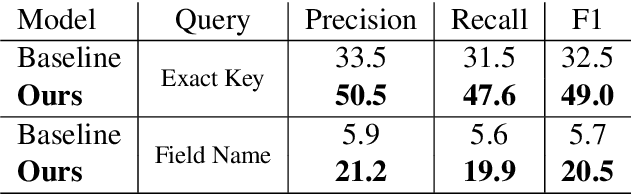
We propose value retrieval with arbitrary queries for form-like documents to reduce human effort of processing forms. Unlike previous methods that only address a fixed set of field items, our method predicts target value for an arbitrary query based on the understanding of layout and semantics of a form. To further boost model performance, we propose a simple document language modeling (simpleDLM) strategy to improve document understanding on large-scale model pre-training. Experimental results show that our method outperforms our baselines significantly and the simpleDLM further improves our performance on value retrieval by around 17\% F1 score compared with the state-of-the-art pre-training method. Code will be made publicly available.
Burn After Reading: Online Adaptation for Cross-domain Streaming Data
Dec 08, 2021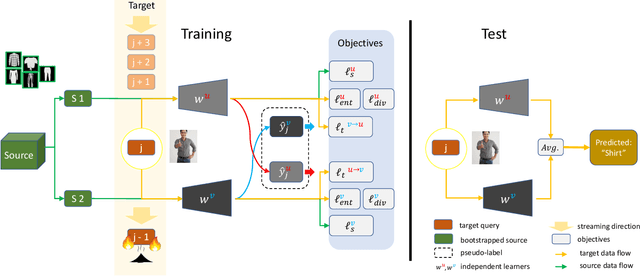
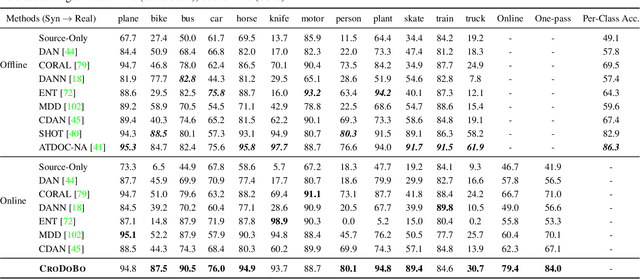

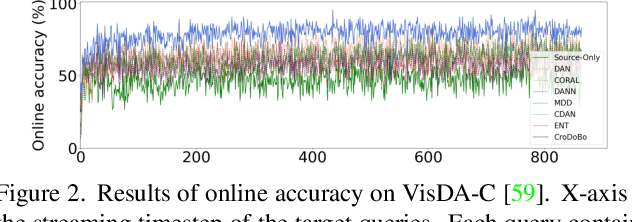
In the context of online privacy, many methods propose complex privacy and security preserving measures to protect sensitive data. In this paper, we argue that: not storing any sensitive data is the best form of security. Thus we propose an online framework that "burns after reading", i.e. each online sample is immediately deleted after it is processed. Meanwhile, we tackle the inevitable distribution shift between the labeled public data and unlabeled private data as a problem of unsupervised domain adaptation. Specifically, we propose a novel algorithm that aims at the most fundamental challenge of the online adaptation setting--the lack of diverse source-target data pairs. Therefore, we design a Cross-Domain Bootstrapping approach, called CroDoBo, to increase the combined diversity across domains. Further, to fully exploit the valuable discrepancies among the diverse combinations, we employ the training strategy of multiple learners with co-supervision. CroDoBo achieves state-of-the-art online performance on four domain adaptation benchmarks.
Proposal Learning for Semi-Supervised Object Detection
Jan 15, 2020
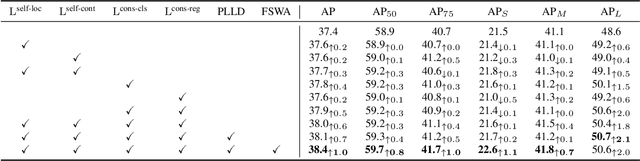

In this paper, we focus on semi-supervised object detection to boost accuracies of proposal-based object detectors (a.k.a. two-stage object detectors) by training on both labeled and unlabeled data. However, it is non-trivial to train object detectors on unlabeled data due to the unavailability of ground truth labels. To address this problem, we present a proposal learning approach to learn proposal features and predictions from both labeled and unlabeled data. The approach consists of a self-supervised proposal learning module and a consistency-based proposal learning module. In the self-supervised proposal learning module, we present a proposal location loss and a contrastive loss to learn context-aware and noise-robust proposal features respectively. In the consistency-based proposal learning module, we apply consistency losses to both bounding box classification and regression predictions of proposals to learn noise-robust proposal features and predictions. Experiments are conducted on the COCO dataset with all available labeled and unlabeled data. Results show that our approach consistently improves the accuracies of fully-supervised baselines. In particular, after combining with data distillation, our approach improves AP by about 2.0% and 0.9% on average compared with fully-supervised baselines and data distillation baselines respectively.
Challenges in Representation Learning: A report on three machine learning contests
Jul 01, 2013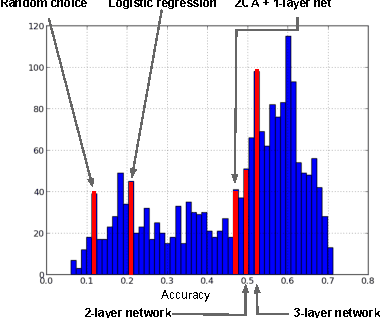

The ICML 2013 Workshop on Challenges in Representation Learning focused on three challenges: the black box learning challenge, the facial expression recognition challenge, and the multimodal learning challenge. We describe the datasets created for these challenges and summarize the results of the competitions. We provide suggestions for organizers of future challenges and some comments on what kind of knowledge can be gained from machine learning competitions.