 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAG: Boosting Text-VQA via Text-aware Visual Question-answer Generation
Aug 14, 2022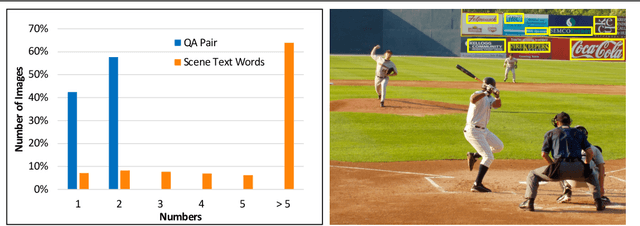
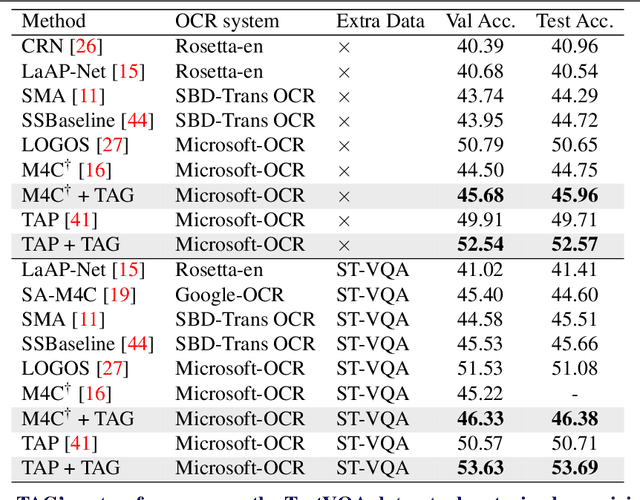

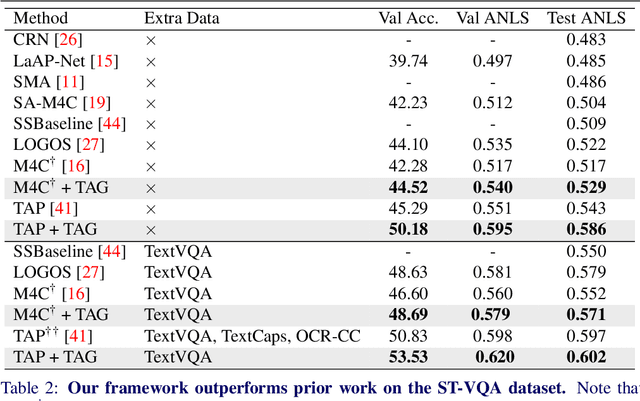
Text-VQA aims at answering questions that require understanding the textual cues in an image. Despite the great progress of existing Text-VQA methods, their performance suffers from insufficient human-labeled question-answer (QA) pairs. However, we observe that, in general, the scene text is not fully exploited in the existing datasets -- only a small portion of text in each image participates in the annotated QA activities. This results in a huge waste of useful information. To address this deficiency, we develop a new method to generate high-quality and diverse QA pairs by explicitly utilizing the existing rich text available in the scene context of each image. Specifically, we propose, TAG, a text-aware visual question-answer generation architecture that learns to produce meaningful, and accurate QA samples using a multimodal transformer. The architecture exploits underexplored scene text information and enhances scene understanding of Text-VQA models by combining the generated QA pairs with the initial training data. Extensive experimental results on two well-known Text-VQA benchmarks (TextVQA and ST-VQA) demonstrate that our proposed TAG effectively enlarges the training data that helps improve the Text-VQA performance without extra labeling effort. Moreover, our model outperforms state-of-the-art approaches that are pre-trained with extra large-scale data. Code is available at https://github.com/HenryJunW/TAG.
Can domain adaptation make object recognition work for everyone?
Apr 23, 2022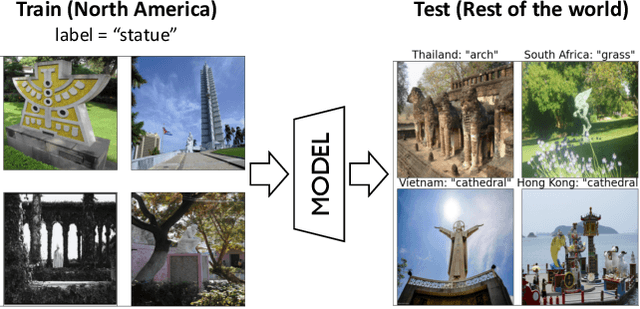



Despite the rapid progress in deep visual recognition, modern computer vision datasets significantly overrepresent the developed world and models trained on such datasets underperform on images from unseen geographies. We investigate the effectiveness of unsupervised domain adaptation (UDA) of such models across geographies at closing this performance gap. To do so, we first curate two shifts from existing datasets to study the Geographical DA problem, and discover new challenges beyond data distribution shift: context shift, wherein object surroundings may change significantly across geographies, and subpopulation shift, wherein the intra-category distributions may shift. We demonstrate the inefficacy of standard DA methods at Geographical DA, highlighting the need for specialized geographical adaptation solutions to address the challenge of making object recognition work for everyone.
CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations
Dec 14, 2021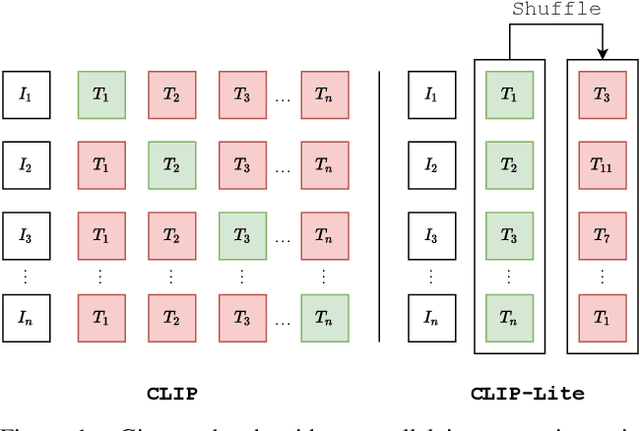
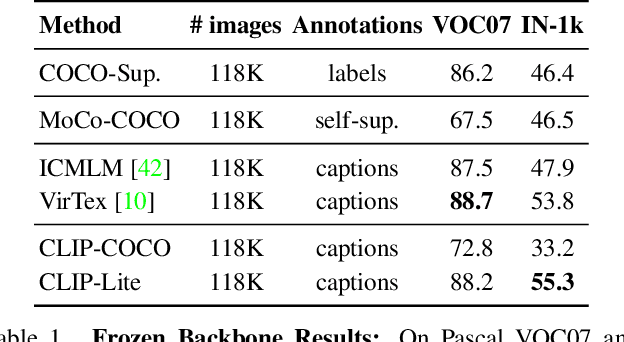

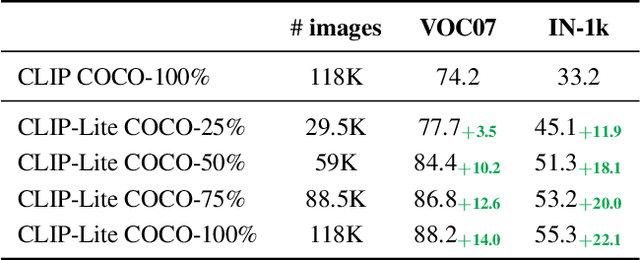
We propose CLIP-Lite, an information efficient method for visual representation learning by feature alignment with textual annotations. Compared to the previously proposed CLIP model, CLIP-Lite requires only one negative image-text sample pair for every positive image-text sample during the optimization of its contrastive learning objective. We accomplish this by taking advantage of an information efficient lower-bound to maximize the mutual information between the two input modalities. This allows CLIP-Lite to be trained with significantly reduced amounts of data and batch sizes while obtaining better performance than CLIP. We evaluate CLIP-Lite by pretraining on the COCO-Captions dataset and testing transfer learning to other datasets. CLIP-Lite obtains a +15.4% mAP absolute gain in performance on Pascal VOC classification, and a +22.1% top-1 accuracy gain on ImageNet, while being comparable or superior to other, more complex, text-supervised models. CLIP-Lite is also superior to CLIP on image and text retrieval, zero-shot classification, and visual grounding. Finally, by performing explicit image-text alignment during representation learning, we show that CLIP-Lite can leverage language semantics to encourage bias-free visual representations that can be used in downstream tasks.
PreViTS: Contrastive Pretraining with Video Tracking Supervision
Dec 01, 2021
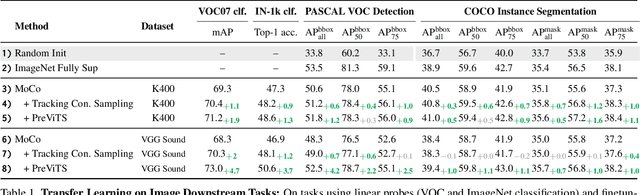
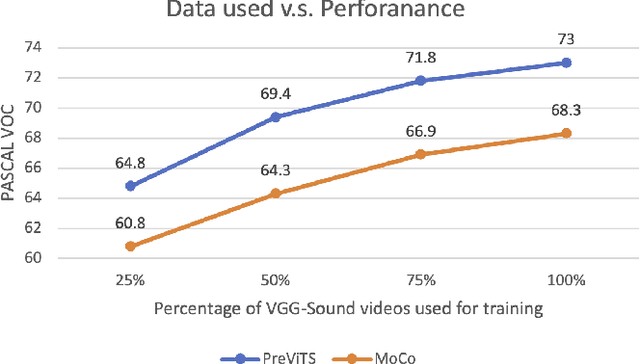
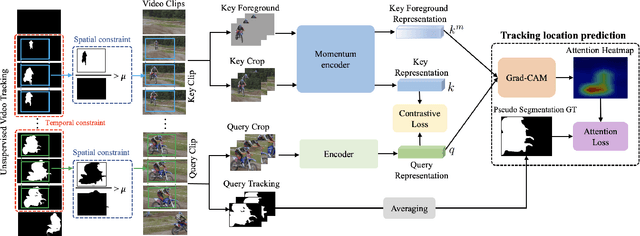
Videos are a rich source for self-supervised learning (SSL) of visual representations due to the presence of natural temporal transformations of objects. However, current methods typically randomly sample video clips for learning, which results in a poor supervisory signal. In this work, we propose PreViTS, an SSL framework that utilizes an unsupervised tracking signal for selecting clips containing the same object, which helps better utilize temporal transformations of objects. PreViTS further uses the tracking signal to spatially constrain the frame regions to learn from and trains the model to locate meaningful objects by providing supervision on Grad-CAM attention maps. To evaluate our approach, we train a momentum contrastive (MoCo) encoder on VGG-Sound and Kinetics-400 datasets with PreViTS. Training with PreViTS outperforms representations learnt by MoCo alone on both image recognition and video classification downstream tasks, obtaining state-of-the-art performance on action classification. PreViTS helps learn feature representations that are more robust to changes in background and context, as seen by experiments on image and video datasets with background changes. Learning from large-scale uncurated videos with PreViTS could lead to more accurate and robust visual feature representations.
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
Jul 16, 2021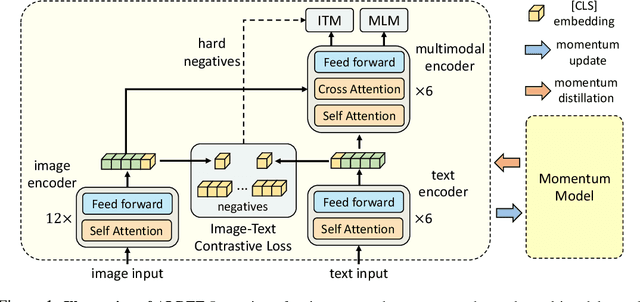



Large-scale vision and language representation learning has shown promising improvements on various vision-language tasks. Most existing methods employ a transformer-based multimodal encoder to jointly model visual tokens (region-based image features) and word tokens. Because the visual tokens and word tokens are unaligned, it is challenging for the multimodal encoder to learn image-text interactions. In this paper, we introduce a contrastive loss to ALign the image and text representations BEfore Fusing (ALBEF) them through cross-modal attention, which enables more grounded vision and language representation learning. Unlike most existing methods, our method does not require bounding box annotations nor high-resolution images. In order to improve learning from noisy web data, we propose momentum distillation, a self-training method which learns from pseudo-targets produced by a momentum model. We provide a theoretical analysis of ALBEF from a mutual information maximization perspective, showing that different training tasks can be interpreted as different ways to generate views for an image-text pair. ALBEF achieves state-of-the-art performance on multiple downstream vision-language tasks. On image-text retrieval, ALBEF outperforms methods that are pre-trained on orders of magnitude larger datasets. On VQA and NLVR$^2$, ALBEF achieves absolute improvements of 2.37% and 3.84% compared to the state-of-the-art, while enjoying faster inference speed. Code and pre-trained models are available at https://github.com/salesforce/ALBEF/.
CASTing Your Model: Learning to Localize Improves Self-Supervised Representations
Dec 08, 2020


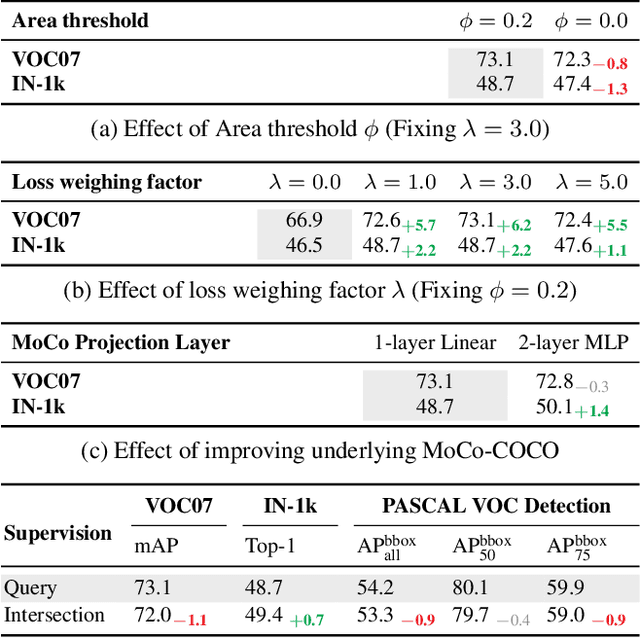
Recent advances in self-supervised learning (SSL) have largely closed the gap with supervised ImageNet pretraining. Despite their success these methods have been primarily applied to unlabeled ImageNet images, and show marginal gains when trained on larger sets of uncurated images. We hypothesize that current SSL methods perform best on iconic images, and struggle on complex scene images with many objects. Analyzing contrastive SSL methods shows that they have poor visual grounding and receive poor supervisory signal when trained on scene images. We propose Contrastive Attention-Supervised Tuning(CAST) to overcome these limitations. CAST uses unsupervised saliency maps to intelligently sample crops, and to provide grounding supervision via a Grad-CAM attention loss. Experiments on COCO show that CAST significantly improves the features learned by SSL methods on scene images, and further experiments show that CAST-trained models are more robust to changes in backgrounds.
SOrT-ing VQA Models : Contrastive Gradient Learning for Improved Consistency
Oct 20, 2020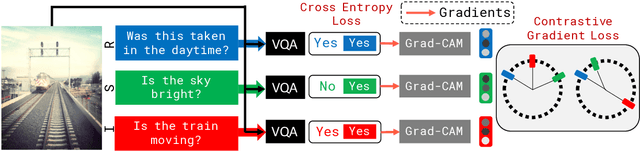



Recent research in Visual Question Answering (VQA) has revealed state-of-the-art models to be inconsistent in their understanding of the world -- they answer seemingly difficult questions requiring reasoning correctly but get simpler associated sub-questions wrong. These sub-questions pertain to lower level visual concepts in the image that models ideally should understand to be able to answer the higher level question correctly. To address this, we first present a gradient-based interpretability approach to determine the questions most strongly correlated with the reasoning question on an image, and use this to evaluate VQA models on their ability to identify the relevant sub-questions needed to answer a reasoning question. Next, we propose a contrastive gradient learning based approach called Sub-question Oriented Tuning (SOrT) which encourages models to rank relevant sub-questions higher than irrelevant questions for an <$image, reasoning-question$> pair. We show that SOrT improves model consistency by upto 6.5% points over existing baselines, while also improving visual grounding.
SQuINTing at VQA Models: Interrogating VQA Models with Sub-Questions
Jan 20, 2020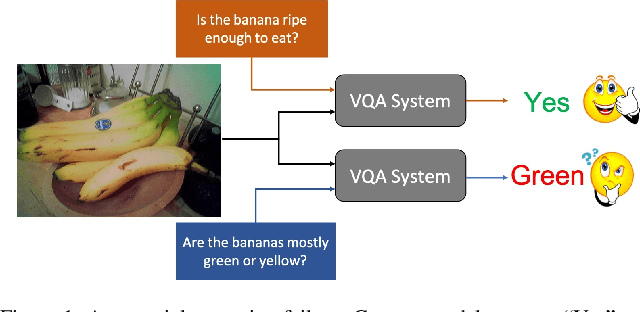

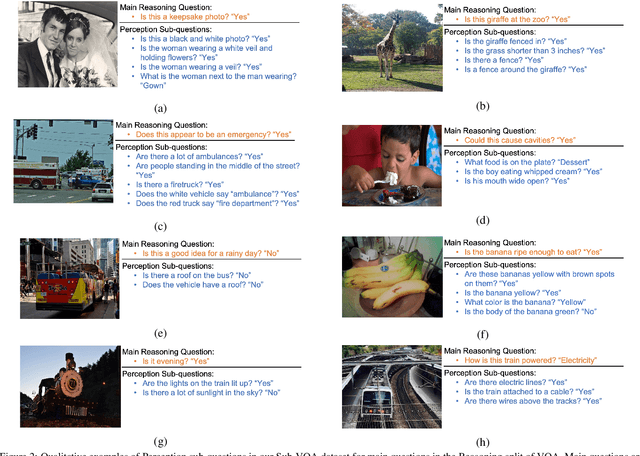
Existing VQA datasets contain questions with varying levels of complexity. While the majority of questions in these datasets require perception for recognizing existence, properties, and spatial relationships of entities, a significant portion of questions pose challenges that correspond to reasoning tasks -- tasks that can only be answered through a synthesis of perception and knowledge about the world, logic and / or reasoning. This distinction allows us to notice when existing VQA models have consistency issues -- they answer the reasoning question correctly but fail on associated low-level perception questions. For example, models answer the complex reasoning question "Is the banana ripe enough to eat?" correctly, but fail on the associated perception question "Are the bananas mostly green or yellow?" indicating that the model likely answered the reasoning question correctly but for the wrong reason. We quantify the extent to which this phenomenon occurs by creating a new Reasoning split of the VQA dataset and collecting Sub-VQA, a new dataset consisting of 200K new perception questions which serve as sub questions corresponding to the set of perceptual tasks needed to effectively answer the complex reasoning questions in the Reasoning split. Additionally, we propose an approach called Sub-Question Importance-aware Network Tuning (SQuINT), which encourages the model to attend do the same parts of the image when answering the reasoning question and the perception sub questions. We show that SQuINT improves model consistency by 7.8%, also marginally improving its performance on the Reasoning questions in VQA, while also displaying qualitatively better attention maps.
Trick or TReAT: Thematic Reinforcement for Artistic Typography
Mar 19, 2019

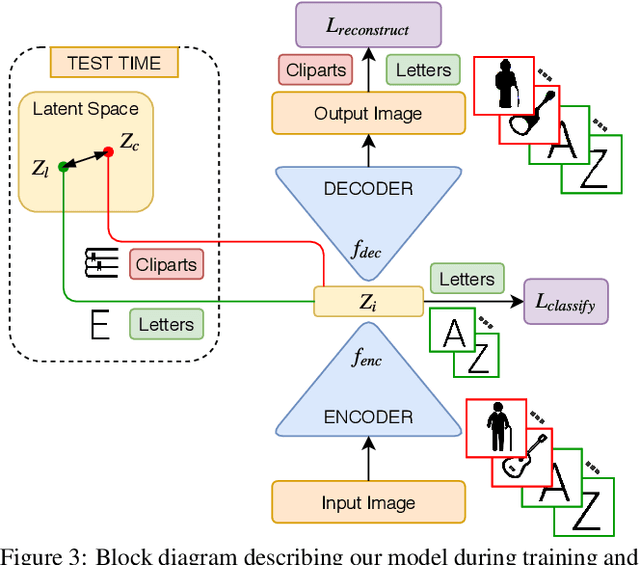

An approach to make text visually appealing and memorable is semantic reinforcement - the use of visual cues alluding to the context or theme in which the word is being used to reinforce the message (e.g., Google Doodles). We present a computational approach for semantic reinforcement called TReAT - Thematic Reinforcement for Artistic Typography. Given an input word (e.g. exam) and a theme (e.g. education), the individual letters of the input word are replaced by cliparts relevant to the theme which visually resemble the letters - adding creative context to the potentially boring input word. We use an unsupervised approach to learn a latent space to represent letters and cliparts and compute similarities between the two. Human studies show that participants can reliably recognize the word as well as the theme in our outputs (TReATs) and find them more creative compared to meaningful baselines.
Taking a HINT: Leveraging Explanations to Make Vision and Language Models More Grounded
Feb 11, 2019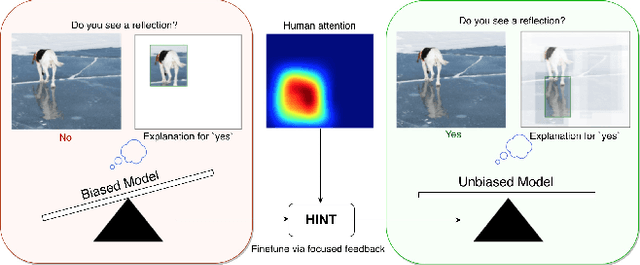
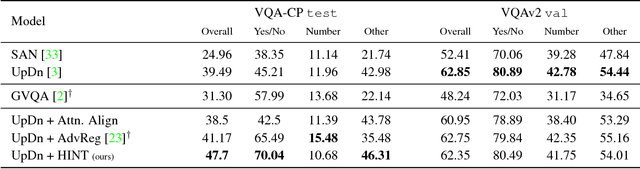


Many vision and language models suffer from poor visual grounding - often falling back on easy-to-learn language priors rather than associating language with visual concepts. In this work, we propose a generic framework which we call Human Importance-aware Network Tuning (HINT) that effectively leverages human supervision to improve visual grounding. HINT constrains deep networks to be sensitive to the same input regions as humans. Crucially, our approach optimizes the alignment between human attention maps and gradient-based network importances - ensuring that models learn not just to look at but rather rely on visual concepts that humans found relevant for a task when making predictions. We demonstrate our approach on Visual Question Answering and Image Captioning tasks, achieving state of-the-art for the VQA-CP dataset which penalizes over-reliance on language priors.