 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAG: Boosting Text-VQA via Text-aware Visual Question-answer Generation
Aug 14, 2022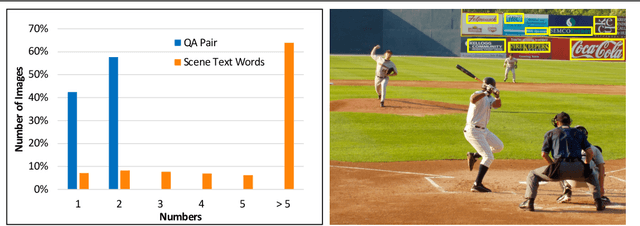
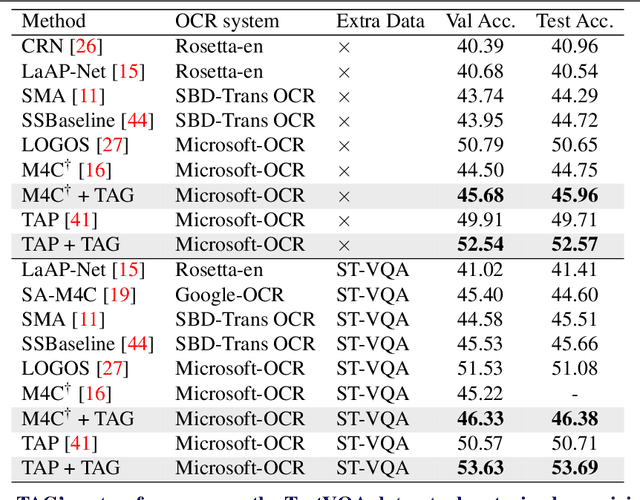

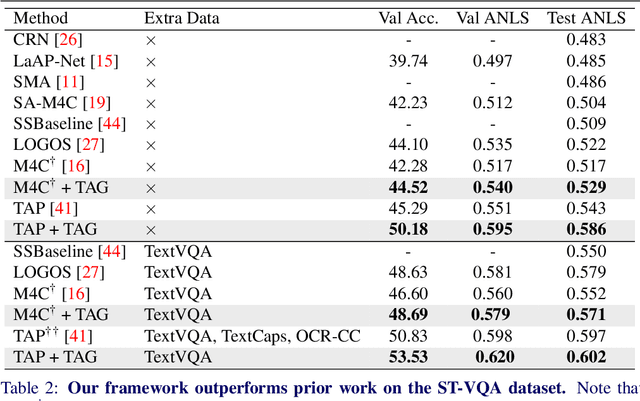
Text-VQA aims at answering questions that require understanding the textual cues in an image. Despite the great progress of existing Text-VQA methods, their performance suffers from insufficient human-labeled question-answer (QA) pairs. However, we observe that, in general, the scene text is not fully exploited in the existing datasets -- only a small portion of text in each image participates in the annotated QA activities. This results in a huge waste of useful information. To address this deficiency, we develop a new method to generate high-quality and diverse QA pairs by explicitly utilizing the existing rich text available in the scene context of each image. Specifically, we propose, TAG, a text-aware visual question-answer generation architecture that learns to produce meaningful, and accurate QA samples using a multimodal transformer. The architecture exploits underexplored scene text information and enhances scene understanding of Text-VQA models by combining the generated QA pairs with the initial training data. Extensive experimental results on two well-known Text-VQA benchmarks (TextVQA and ST-VQA) demonstrate that our proposed TAG effectively enlarges the training data that helps improve the Text-VQA performance without extra labeling effort. Moreover, our model outperforms state-of-the-art approaches that are pre-trained with extra large-scale data. Code is available at https://github.com/HenryJunW/TAG.
Learning Graph-Level Representations with Recurrent Neural Networks
Sep 11, 2018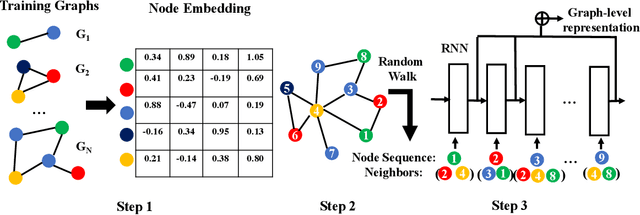
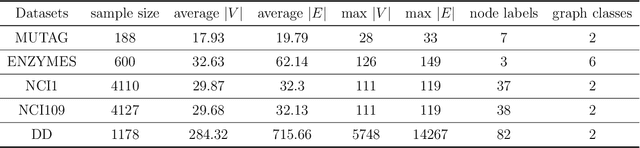
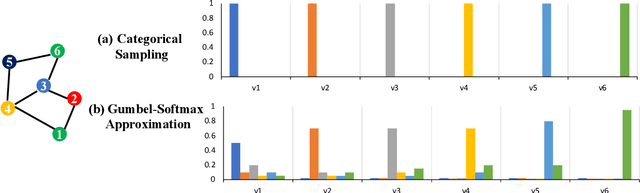
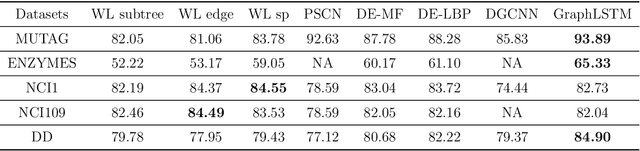
Recently a variety of methods have been developed to encode graphs into low-dimensional vectors that can be easily exploited by machine learning algorithms. The majority of these methods start by embedding the graph nodes into a low-dimensional vector space, followed by using some scheme to aggregate the node embeddings. In this work, we develop a new approach to learn graph-level representations, which includes a combination of unsupervised and supervised learning components. We start by learning a set of node representations in an unsupervised fashion. Graph nodes are mapped into node sequences sampled from random walk approaches approximated by the Gumbel-Softmax distribution. Recurrent neural network (RNN) units are modified to accommodate both the node representations as well as their neighborhood information. Experiments on standard graph classification benchmarks demonstrate that our proposed approach achieves superior or comparable performance relative to the state-of-the-art algorithms in terms of convergence speed and classification accuracy. We further illustrate the effectiveness of the different components used by our approach.